参考
好处
- 加速模型收敛
- 提高模型精度
区别
1. 标准化Z-score
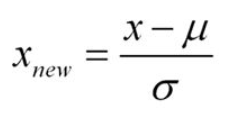
- 受异常点影响小。有异常点时,用归一化的话,正常点会挤到一块,增加了模型区分难度。
- 更符合统计学假设。对数值特征来说,有很大可能符合正态分布。
- 使用场景更广泛。
使用场景:
在涉及距离度量、协方差计算、数据异常较多等时候,需要使用标准化。
(1)逻辑回归必须用标准化吗?
- 有正则项时,必须用标准化。正则项度量参数值是否足够小,和特征的量纲相关。例如1cm=0.01m,使用不用量纲时,特征数据差异巨大,需要用标准化时特征无量纲化,使得特征数值量级相当。
- 标准化能加速模型训练过程。
- 标准化后,可以用特征权重筛选特征重要度。
标准化注意事项?先拆分出test集,仅对训练集做标准化,防止信息泄露。
(2)距离相关、PAC需要标准化
距离相关:分类聚类算法中,如KNN、Kmean等。
- 特征重要度:PCA降维的时候,标准化的表现更好。
2. 归一化
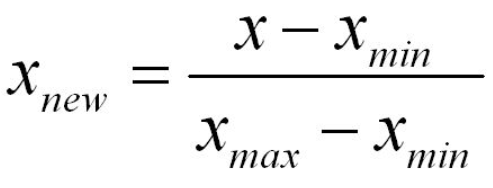
缺点:
- 容易受异常点影响,鲁棒性不强。
- 数据变化时,min和max可能会变化。
- 使用场景较少。
使用场景:
- 在不涉及距离度量、协方差计算、数据不符合正态分布的时候,可以使用归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。有时候,我们必须要特征在0到1之间,此时就只能用归一化。
代码实现
参考Spark ML的特征处理实战,使用Scala的org.apache.spark.ml.feature.StandardScaler对特征进行标准化。
import org.apache.spark.ml.feature.StandardScalerimport org.apache.spark.ml.linalg.{Vector,Vectors}val dataFrame = spark.createDataFrame(Seq((0, Vectors.dense(1.0, 0.5, -1.0)),(1, Vectors.dense(2.0, 1.0, 1.0)),(2, Vectors.dense(4.0, 10.0, 2.0)))).toDF("id", "features")val scaler = new StandardScaler().setInputCol("features").setOutputCol("scaledFeatures").setWithStd(true).setWithMean(false)val scalerModel = scaler.fit(dataFrame)val scaledData = scalerModel.transform(dataFrame)scaledData.show(false)
结果
注意:上述将每一列的标准差缩放到1。如果特征的标准差为零,则该特征在向量中返回的默认值为0.0。

若有收获,就点个赞吧
0 人点赞
