参考
算法亮点
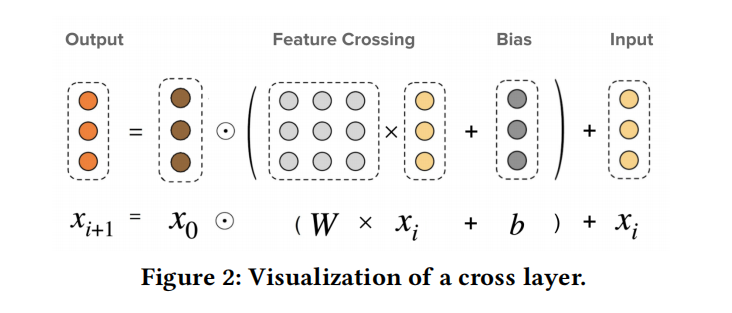
- 显示构造了vector-wise的指定阶特征交叉,计算公式和xdeepFm有点像。
将大矩阵分解为两个小矩阵,降低计算量。之所以能这样,是因为学出的矩阵W的特征值一般衰减的很快。论文发现,low-rank DCN的取rank=input_size/4,就能达到和完整矩阵一样的效果。
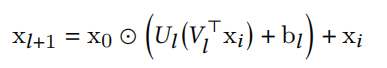<br />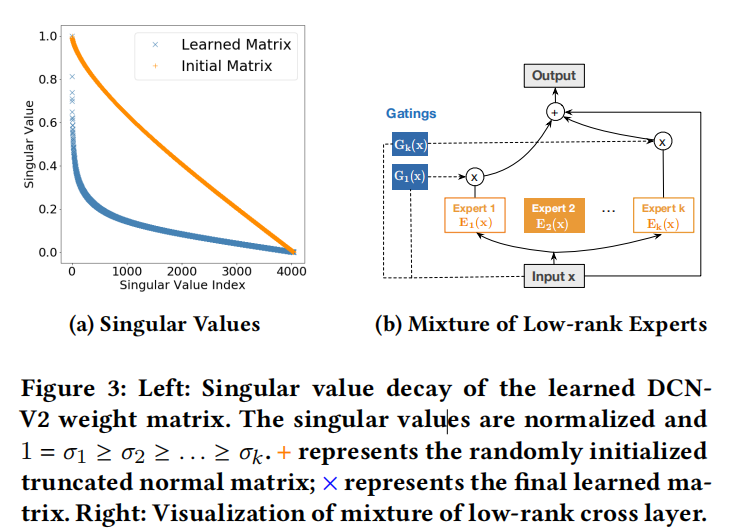
DCN比DNN更能拟合固定阶多项式。论文构造了2/3/4阶多项式数据,发现DCN能更好的拟合结果。
疑问
- 不要求emb具有相同维度?具体怎么实现的?
改进点
- 如何更高效的构造高阶特征?如果二阶项xaxb本身比较小,那么三阶项xaxb*xc将更小,所以算三阶项时,只用考虑权重大的二阶项?根据权重的大小可以进行一定的截断,保证效果减少计算量。

若有收获,就点个赞吧
0 人点赞
