参考
- Learning To Rank之LambdaMART的前世今生
- gbdt原理(非常重要)
- 决策树-上-ID3C4.5_CART及剪枝
- 数据挖掘十大算法之CART详解
- 深入理解GBDT回归算法。对GBDT的原理讲解的比较清晰,举的例子也比较好。
知识点
LambdaMART算法原理?
参考Learning To Rank之LambdaMART的前世今生。
损失函数,其中算分函数s=f(x;w)。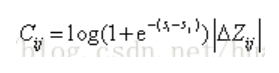
这个损失函数,log部分是用算分函数si拟合实际的相关性偏序关系,本质上还是二分类交叉熵。|△Z|是位置权重的影响,在排序问题中,位置越靠前越重要,相应的负梯度应该更大。
对s的一阶梯度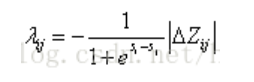
物理意义:上式默认了文档i的相关性高于j。
- 拉开正负样本得分。从i的角度看,sigmod负梯度始终大于0,会使文档得分si增大,拉开正负样本的得分。正负样本分值差si-sj越小,sigmod负梯度越大,正样本si增加越多。
- 位置的影响。假设有两个正样本i1和i2,i1位置在i2前面,且s_i1=s_i2,负样本为j。在排序问题中,位置越靠前越重要,因此应该让s_i1增加幅度更大。例如将第2位的正样本调至第1位,用户能明显感知;而将第12位的正样本调至第11位,用户则无明显感知。那么如何实现这一点呢?就是通过梯度中的|△Z|,由于i1排在i2前面,交换i1和j时,NDCG指标的变化更大,负梯度也越大,从而s_i1获得更大的增量。
对s的二阶梯度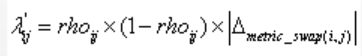
lambdaMART算法流程:
lambdaMART算法流程图: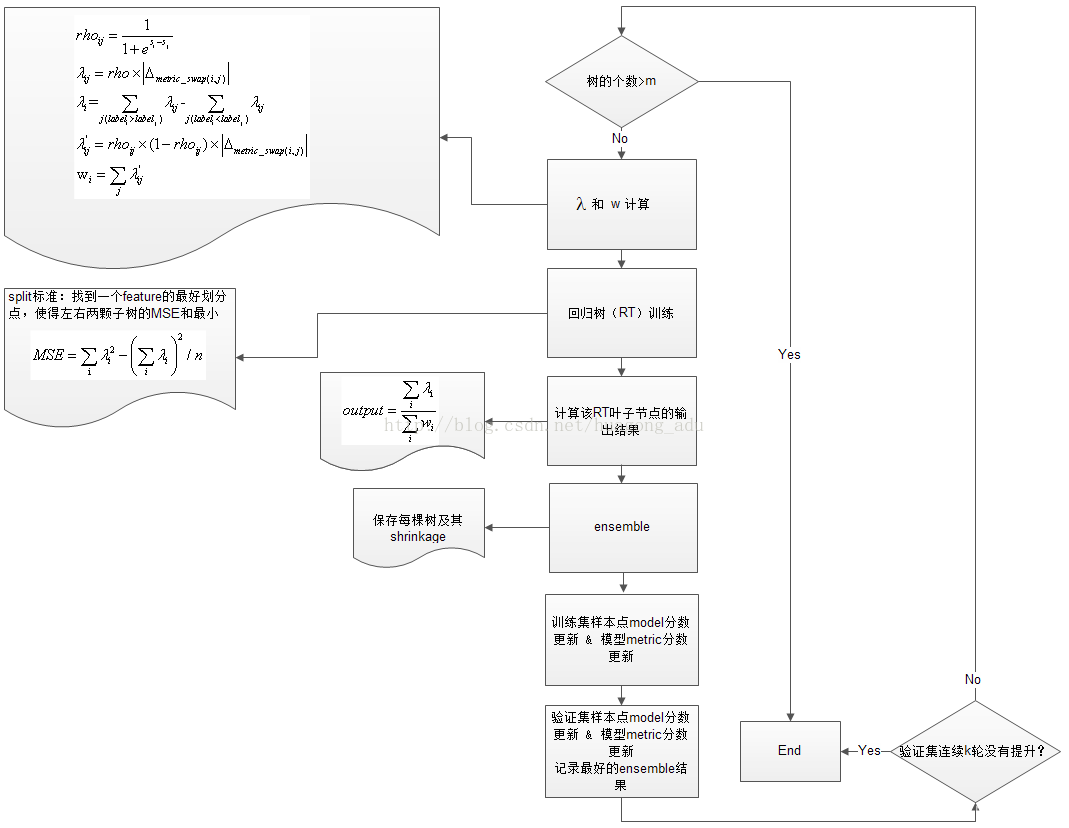
XGboost和GBDT的区别?
参考wepon: 机器学习算法中 GBDT 和 XGBOOST 的区别有哪些?
参考GBDT和Xgboost:原理、推导、比较。
- 梯度信息: 传统GBDT只引入了一阶导数信息,Xgboost引入了一阶导数和二阶导数信息,其对目标函数引入了二阶近似,求得解析解, 用解析解作为Gain来建立决策树, 使得目标函数最优(Gain求到的是解析解)。另外,XGBoost工具支持自定义损失函数,只要函数可一阶和二阶求导。
- 正则项: Xgboost引入了正则项部分,这是传统GBDT中没有的。加入正则项可以控制模型的复杂度,防止过拟合。正则项γ相当于预剪枝的阈值,只有分裂的收益大于阈值时才分裂。
- 基分类器: 传统GBDT以CART作为基分类器,XGBoost还支持线性分类器,这个时候XGBoost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 分裂方式:GBDT是用的MSE,XGBoost是经过优化推导后的。
- 缺失值:对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- 特征采样: Xgboost引入了特征子采样,像随机森林那样,既可以降低过拟合,也可以减少计算。
- 并行化: 传统GBDT由于树之间的强依赖关系是无法实现并行处理的,但是Xgboost支持并行处理,XGBoost的并行不是在模型上的并行,而是在特征上的并行,将特征列排序后以block的形式存储在内存中,在后面的迭代中重复使用这个结构。这个block也使得并行化成为了可能,其次在进行节点分裂时,计算每个特征的增益,最终选择增益最大的那个特征去做分割,那么各个特征的增益计算就可以开多线程进行。
- 除此之外,Xgboost实现了分裂点寻找近似算法、缺失值处理、列抽样(降低过拟合,还能减少计算)等包括一些工程上的优化,LightGBM是Xgboost的更高效实现。
分裂标准:ID3、C4.5、CART、GBDT、xgboost?
ID3算法采用信息增益;
C4.5算法采用信息增益比;
CART分类数采用Gini系数;
CART回归树采用MSE;
GBDT采用MSE;
XGBoost采用xgboost打分函数。
信息熵,越小越有序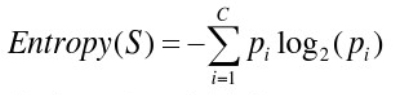
信息增益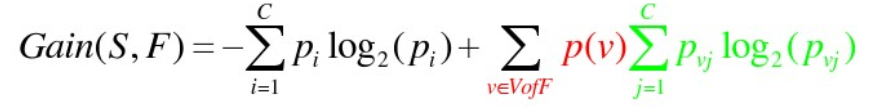
信息增益率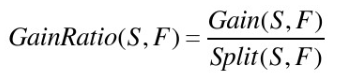
其中split为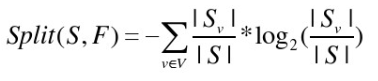
gini系数,越小越有序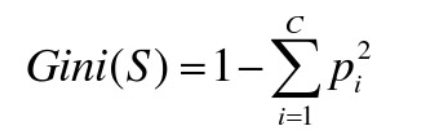
gini系数加权求和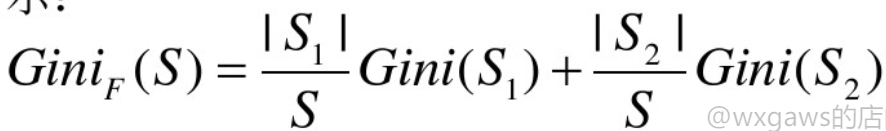
xgboost打分函数
样本不平衡对树模型分裂的影响?
- 影响树的形状。例如1个正样本,99个负样本,则可能出现极度倾斜的树,使正样本的判断条件太简单,学到正样本的有用信息很少。
- 影响叶子的标签。例如1个正样本,99个负样本,分裂后可能叶子1有50个负样本,叶子2有49个负样本加1个正样本。那么叶子2应该标记为正样本还是负样本?更应该标记为正样本,因为1/49>1/99,如果考虑到样本权重,叶子2标记为正样本更合理。
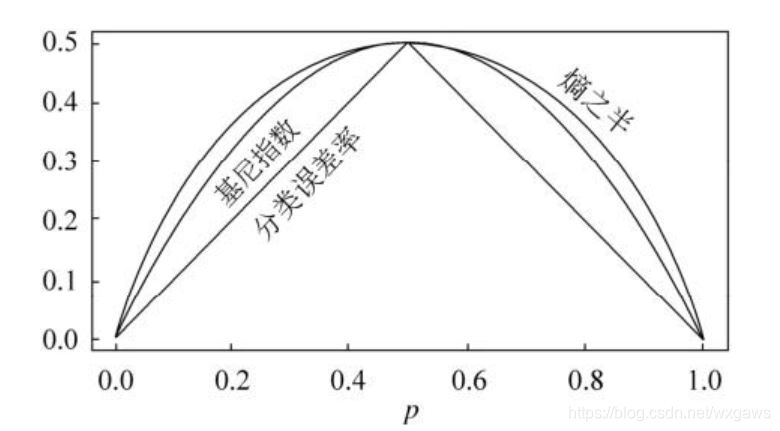
gini系数和信息熵什么关系?
小量近似下等价。gini系数没有对数运算,计算效率更高。参考cart算法为什么选用gini指数?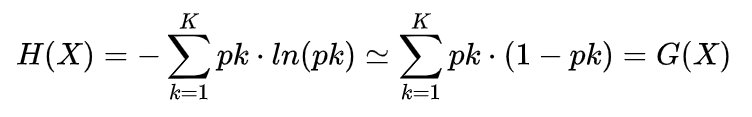
疑问
- 分类树和回归树的区别?损失函数:分类用交叉熵等,回归用MSE等。分裂标准:分类用gini系数,回归用MSE。
- xgboost中如何处理分类树?参考GBDT算法用于分类问题
- 离散特征如何处理?文献4有离散特征例子。
- 岭回归?加了L2正则项的线性回归。
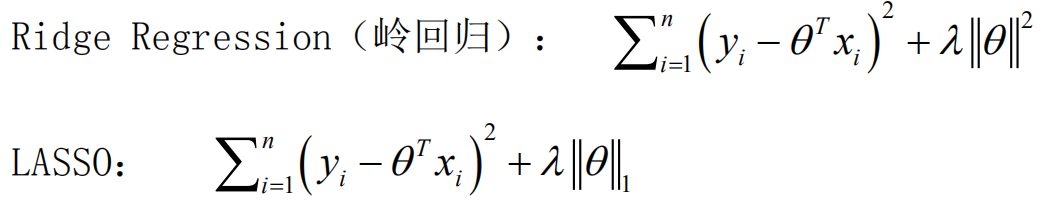

若有收获,就点个赞吧
0 人点赞
