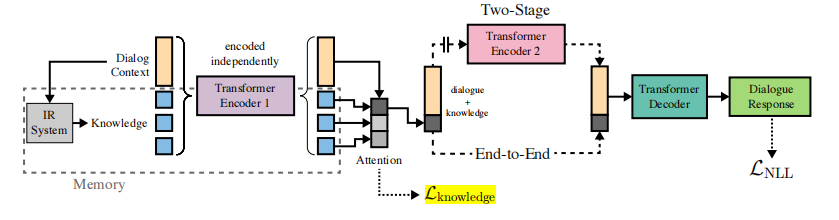
图1:模型参考结构。其中检索部分使用DPR模型,选择知识用Attention,生成回复使用BART模型。在公开的预训练模型基础上,用多轮对话数据微调训练。
多轮对话数据
数据格式(ctx_topic, ctx_dialogue_pre, ctx_knowledge, response),其中:
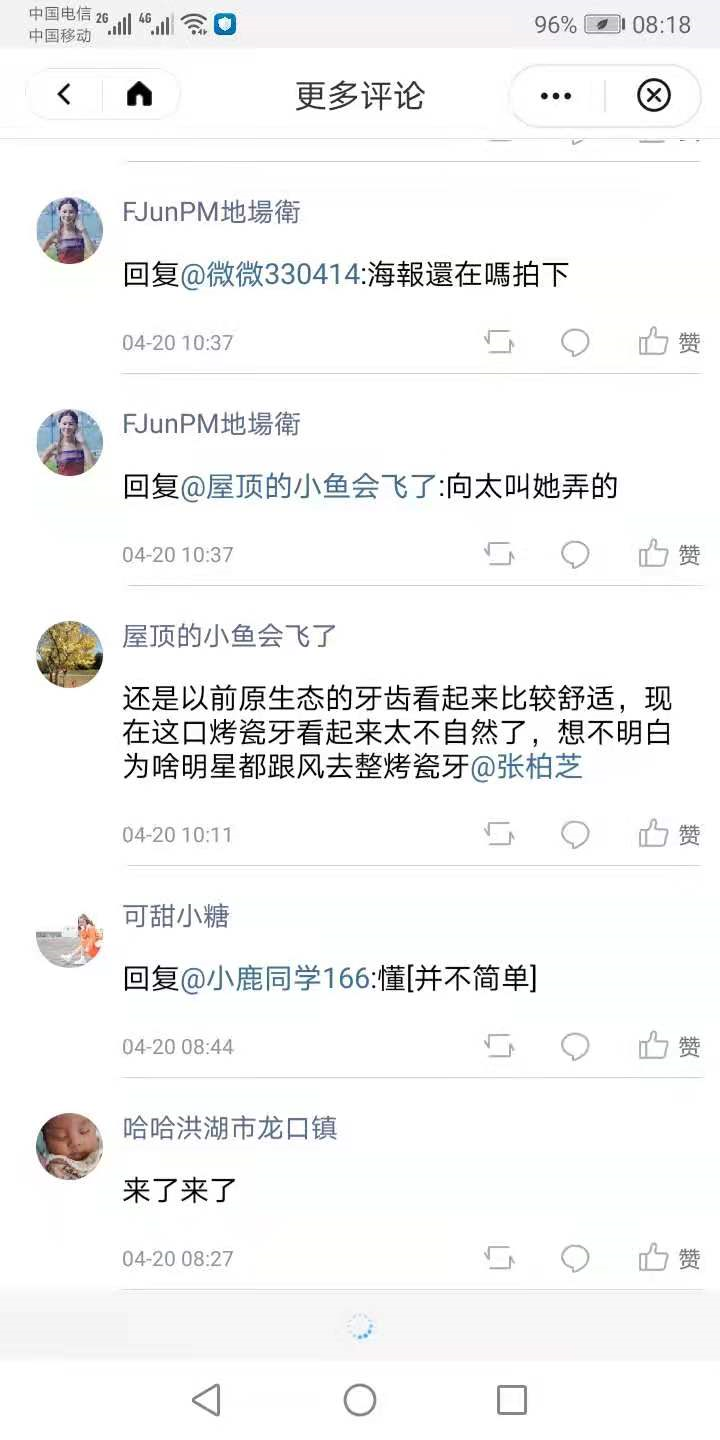
- ctx_topic:热搜话题, 包括明星+内容。例如下图微博热搜,明星=“张柏芝”,内容=#“尽兴生活#任何天气[][太阳][浮云][下雨][微风]”
- ctx_dialogue_pre:前几轮的对话内容。例如下图中“FjunPM地场街”和“屋顶的小鱼会飞了”有多轮对话。
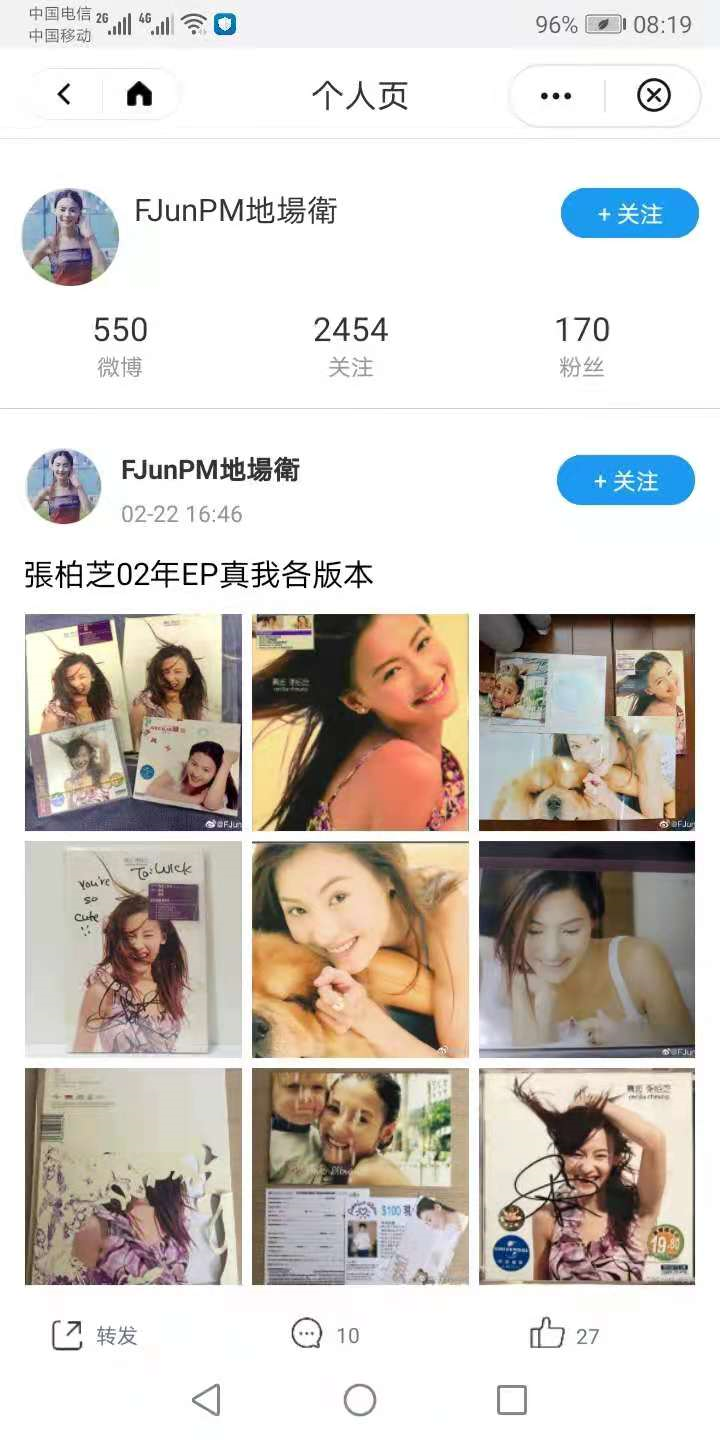
- ctx_knowledge:用户对明星了解的知识一般比较零碎。其了解的信息有,用户个人页发布的明星信息(见下图右),用户关于某明星的历史对话,明星的历史热门内容。可以将这些文字信息爬取下来,拆分为”明星+内容”后,用encoder编码存为index。
- response:正样本为真实回复,负样本可取同batch内的其它回复、本人其它轮回复、随机回复等。

模型流程
- 获取ctx_knowledge。使用DPR模型,仿照wizard_of_wikipedia模型,用encoder将ctx_topic和后几轮的问句,编码为query_vector,然后用faiss从该用户的ctx_knowledge中检索相关的topk条内容。
- ctx_knowledge选择。使用attention机制选择其中一条ctx_knowledge进入BART模型,用户的一次回答一般会参考一个知识点。
- 预测response。使用BART模型,将ctx_topic, ctx_dialogue_pre, ctx_knowledge等信息输入模型,使用beam search或sample and rank方法生成回复内容。需要做knowledge_dropout,因为用户一般只会用到部分知识。
难点
- 多轮对话数据收集。目前看微博是较好的数据来源,文字信息和评论都比较多。预计至少需要收集1万个对话*10轮。
- 回复的知识性。做好ctx_knowledge选择,可以提高聊天的知识性。
- 回复的多样性。解决方法有:1)将本人历史回复作为负样本,避免重复;2)过滤多次出现的n-gram,减少重复;2)控制回复长度,保证回复具体但不啰嗦。

若有收获,就点个赞吧
0 人点赞
