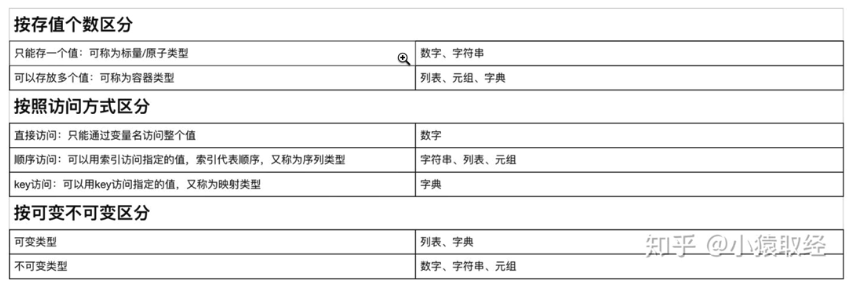
一、集合
1、作用
1.1 关系运算
friends1 = ["zero","kevin","jason","egon"]friends2 = ["Jy","ricky","jason","egon"]l=[]for x in friends1:if x in friends2:l.append(x)print(l)
1.2、去重
2、定义:
在{}内用逗号分隔开多个元素,多个元素满足以下三个条件
1. 集合内元素必须为不可变类型
2. 集合内元素无序
3. 集合内元素没有重复
s={1,2} # s=set({1,2})
s={1,[1,2]} # 集合内元素必须为不可变类型
s={1,’a’,’z’,’b’,4,7} # 集合内元素无序
s={1,1,1,1,1,1,’a’,’b’} # 集合内元素没有重复
print(s)
了解
s={} # 默认是空字典
print(type(s))
定义空集合
s=set()
print(s,type(s))
3、类型转换
set({1,2,3})
res=set(‘hellolllll’)
print(res)
print(set([1,1,1,1,1,1]))
print(set([1,1,1,1,1,1,[11,222]]) # 报错
4、内置方法
=========================关系运算符=========================
friends1 = {“zero”,”kevin”,”jason”,”egon”}
friends2 = {“Jy”,”ricky”,”jason”,”egon”}
4.1 取交集:两者共同的好友
res=friends1 & friends2
print(res)
print(friends1.intersection(friends2))
4.2 取并集/合集:两者所有的好友
print(friends1 | friends2)
print(friends1.union(friends2))
4.3 取差集:取friends1独有的好友
print(friends1 - friends2)
print(friends1.difference(friends2))
取friends2独有的好友
print(friends2 - friends1)
print(friends2.difference(friends1))
4.4 对称差集: 求两个用户独有的好友们(即去掉共有的好友)
print(friends1 ^ friends2)
print(friends1.symmetric_difference(friends2))
4.5 父子集:包含的关系
s1={1,2,3}
s2={1,2,4}
不存在包含关系,下面比较均为False
print(s1 > s2)
print(s1 < s2)
s1={1,2,3}
s2={1,2}
print(s1 > s2) # 当s1大于或等于s2时,才能说是s1是s2他爹
print(s1.issuperset(s2))
print(s2.issubset(s1)) # s2 < s2 =>True
s1={1,2,3}
s2={1,2,3}
print(s1 == s2) # s1与s2互为父子
print(s1.issuperset(s2))
print(s2.issuperset(s1))
5、去重
5.1、只能针对不可变类型去重
print(set([1,1,1,1,2]))
5.2、无法保证原来的顺序
l=[1,’a’,’b’,’z’,1,1,1,2]
l=list(set(l))
print(l)
l=[{'name':'lili','age':18,'sex':'male'},{'name':'jack','age':73,'sex':'male'},{'name':'tom','age':20,'sex':'female'},{'name':'lili','age':18,'sex':'male'},{'name':'lili','age':18,'sex':'male'},]new_l=[]for dic in l:if dic not in new_l:new_l.append(dic)print(new_l)
其他操作
# 1.长度
>>> s={‘a’,’b’,’c’}
>>> len(s)
3
2.成员运算
>>> ‘c’ in s
True
3.循环
>>> for item in s:
… print(item)
…
c
a
b
‘’’
其他内置方法
s={1,2,3}
需要掌握的内置方法1:discard
s.discard(4) # 删除元素不存在do nothing
print(s)
s.remove(4) # 删除元素不存在则报错
需要掌握的内置方法2:update
s.update({1,3,5})
print(s)
需要掌握的内置方法3:pop
res=s.pop()#随机删除
print(res)
需要掌握的内置方法4:add
s.add(4)
print(s)
其余方法全为了解
res=s.isdisjoint({3,4,5,6}) # 两个集合完全独立、没有共同部分,返回True
print(res)
了解
s.difference_update({3,4,5}) # s=s.difference({3,4,5})
print(s)
二、字符编码
分析过程
x=”上”
内存<br />上-------翻译-----》0101010<br />上《----翻译《-----0101010
字符编码表就是一张字符与数字对应关系的表
a-00
b-01
c-10
d-11
ASCII表:
1、只支持英文字符串<br /> 2、采用8位二进制数对应一个英文字符串
GBK表:
1、支持英文字符、中文字符<br /> 2、<br /> 采用8位(8bit=1Bytes)二进制数对应一个英文字符串<br /> 采用16位(16bit=2Bytes)二进制数对应一个中文字符串
unicode(内存中统一使用unicode):
1、<br /> 兼容万国字符<br /> 与万国字符都有对应关系<br /> 2、<br /> 采用16位(16bit=2Bytes)二进制数对应一个中文字符串<br /> 个别生僻会采用4Bytes、8Bytesunicode表:<br /> 内存<br /> 人类的字符---------unicode格式的数字----------<br /> | |<br /> | |<br /> |<br /> 硬盘 |<br /> |<br /> | |<br /> | |<br /> GBK格式的二进制 Shift-JIS格式的二进制老的字符编码都可以转换成unicode,但是不能通过unicode互转
utf-8:
英文->1Bytes<br /> 汉字->3Bytes
结论:
1、内存固定使用unicode,我们可以改变的是存入硬盘采用格式
英文+汉字-》unicode-》gbk
英文+日文-》unicode-》shift-jis
万国字符》-unicode-》utf-8
2、文本文件存取乱码问题<br /> 存乱了:解决方法是,编码格式应该设置成支持文件内字符串的格式<br /> 取乱了:解决方法是,文件是以什么编码格式存如硬盘的,就应该以什么编码格式读入内存3、python解释器默认读文件的编码<br /> python3默认:utf-8<br /> python2默认:ASCII指定文件头修改默认读的编码:<br /> 在py文件的首行写:<br /> #coding:gbk4、保证运行python程序前两个阶段不乱码的核心法则:<br /> 指定文件头<br /> # coding:文件当初存入硬盘时所采用的编码格式5、python3的str类型默认直接存成unicode格式,无论如何都不会乱码<br /> 保证python2的str类型不乱码<br /> x=u'上'6、了解<br /> python2解释器有两种字符串类型:str、unicode<br /> # str类型<br /> x='上' # 字符串值会按照文件头指定的编码格式存入变量值的内存空间<br /> # unicode类型<br /> x=u'上' # 强制存成unicode

若有收获,就点个赞吧
0 人点赞
