一、迭代器
1、什么是迭代器
迭代器指的是迭代取值的工具,迭代是一个重复的过程,每次重复都是基于上一次的结果而继续的,单纯的重复并不是迭代<br />
2、为何要有迭代器
迭代器是用来迭代取值的工具,而涉及到把多个值循环取出来的类有:列表、字符串、元组、字典、集合、打开文件
l=['egon','liu','alex']i=0while i < len(l):print(l[i])i+=1
上述迭代取值的方式只适用于有索引的数据类型:列表、字符串、元组;为了解决基于索引迭代器取值的局限性<br /> python必须提供一种能够不依赖于索引的取值方式,这就是迭代器
3、如何用迭代器
3.1 可迭代的对象:
但凡内置有iter方法的都称之为可迭代的对象
s1=''# s1.__iter__()l=[]# l.__iter__()t=(1,)# t.__iter__()d={'a':1}# d.__iter__()set1={1,2,3}# set1.__iter__()with open('a.txt',mode='w') as f:# f.__iter__()pass
3.2 调用可迭代对象下的iter方法会将其转换成迭代器对象
d={'a':1,'b':2,'c':3}d_iterator=d.__iter__()# print(d_iterator)# print(d_iterator.__next__())# print(d_iterator.__next__())# print(d_iterator.__next__())# print(d_iterator.__next__()) # 抛出异常StopIterationwhile True:try:print(d_iterator.__next__())except StopIteration:breakprint('====>>>>>>') # 在一个迭代器取值取干净的情况下,再对其取值娶不到d_iterator=d.__iter__()while True:try:print(d_iterator.__next__())except StopIteration:breakl=[1,2,3,4,5]l_iterator=l.__iter__()while True:try:print(l_iterator.__next__())except StopIteration:break
3.3 可迭代对象与迭代器对象详解
可迭代对象(”可以转换成迭代器的对象”):内置有iter方法对象
可迭代对象.__iter__(): 得到迭代器对象
迭代器对象:内置有next方法并且内置有iter方法的对象
迭代器对象.__next__():得到迭代器的下一个值<br /> 迭代器对象.__iter__():得到迭代器的本身,说白了调了跟没调一个样子<br />dic={'a':1,'b':2,'c':3}
diciterator=dic.iter()
print(diciterator is diciterator.iter()._iter().__iter())
3.4 可迭代对象:
字符串、列表、元组、字典、集合、文件对象
迭代器对象:文件对象
s1=''s1.__iter__()l=[]l.__iter__()t=(1,)t.__iter__()d={'a':1}d.__iter__()set1={1,2,3}set1.__iter__()with open('a.txt',mode='w') as f:f.__iter__()f.__next__()
3.5 for循环的工作原理:
for循环可以称之为叫迭代器循环
d={‘a’:1,’b’:2,’c’:3}
- d.iter()得到一个迭代器对象
- 迭代器对象.next()拿到一个返回值,然后将该返回值赋值给k
- 循环往复步骤2,直到抛出StopIteration异常for循环会捕捉异常然后结束循环
for k in d:
print(k)
with open(‘a.txt’,mode=’rt’,encoding=’utf-8’) as f:
for line in f: # f.iter()
print(line)
list(‘hello’) #原理同for循环
3.6 迭代器优缺点总结
缺点:
I、为序列和非序列类型提供了一种统一的迭代取值方式。
II、惰性计算:迭代器对象表示的是一个数据流,可以只在需要时才去调用next来计算出一个值,就迭代器本身来说,同一时刻在内存中只有一个值,因而可以存放无限大的数据流,而对于其他容器类型,如列表,需要把所有的元素都存放于内存中,受内存大小的限制,可以存放的值的个数是有限的。
缺点:
I、除非取尽,否则无法获取迭代器的长度
II、只能取下一个值,不能回到开始,更像是‘一次性的’,迭代器产生后的唯一目标就是重复执行next方法直到值取尽,否则就会停留在某个位置,等待下一次调用next;若是要再次迭代同个对象,你只能重新调用iter方法去创建一个新的迭代器对象,如果有两个或者多个循环使用同一个迭代器,必然只会有一个循环能取到值。
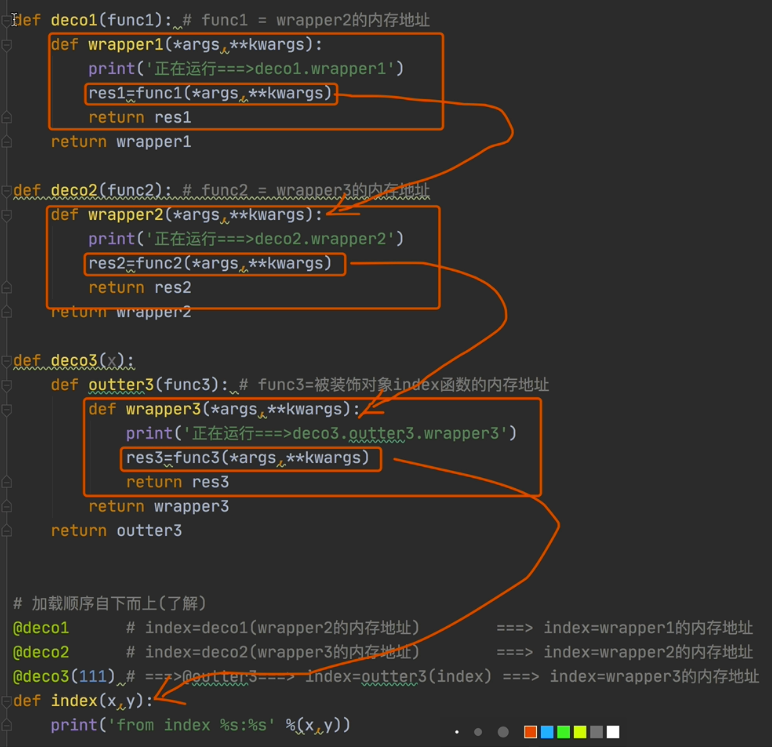
4、叠加多个装饰器的加载、运行分析(了解*)
def deco1(func1): # func1 = wrapper2的内存地址
def wrapper1(*args,**kwargs):
print('正在运行===>deco1.wrapper1')
res1=func1(*args,**kwargs)
return res1
return wrapper1
def deco2(func2): # func2 = wrapper3的内存地址
def wrapper2(*args,**kwargs):
print('正在运行===>deco2.wrapper2')
res2=func2(*args,**kwargs)
return res2
return wrapper2
def deco3(x):
def outter3(func3): # func3=被装饰对象index函数的内存地址
def wrapper3(*args,**kwargs):
print('正在运行===>deco3.outter3.wrapper3')
res3=func3(*args,**kwargs)
return res3
return wrapper3
return outter3
加载顺序自下而上(了解)
@deco1 # index=deco1(wrapper2的内存地址) ===> index=wrapper1的内存地址
@deco2 # index=deco2(wrapper3的内存地址) ===> index=wrapper2的内存地址
@deco3(111) # ===>@outter3===> index=outter3(index) ===> index=wrapper3的内存地址
def index(x,y):
print('from index %s:%s' %(x,y))
@执行顺序自上而下的,即wraper1-》wrapper2-》wrapper3
index(1,2) # wrapper1(1,2)
二、生成器
1、如何得到自定义的迭代器
在函数内一旦存在yield关键字,调用函数并不会执行函数体代码
会返回一个生成器对象,生成器即自定义的迭代器
def func():
print('第一次')
yield 1
print('第二次')
yield 2
print('第三次')
yield 3
print('第四次')
g=func()
print(g)
# 生成器就是迭代器
g.__iter__()
g.__next__()
会触发函数体代码的运行,然后遇到yield停下来,将yield后的值
当做本次调用的结果返回
res1=g.__next__()
print(res1)
res2=g.__next__()
print(res2)
res3=g.__next__()
print(res3)
res4=g.__next__()
len('aaa') # 'aaa'.__len__()
next(g) # g.__next__()
iter(可迭代对象) # 可迭代对象.__iter__()
应用案列
def my_range(start,stop,step=1):
# print('start...')
while start < stop:
yield start
start+=step
# print('end....')
# g=my_range(1,5,2) # 1 3
# print(next(g))
# print(next(g))
# print(next(g))
for n in my_range(1,7,2):
print(n)
2、总结yield
有了yield关键字,我们就有了一种自定义迭代器的实现方式。yield可以用于返回值,但不同于return,函数一旦遇到return就结束了,而yield可以保存函数的运行状态挂起函数,用来返回多次值
3、yield返回值
x=yield 返回值
```python def dog(name): print(‘道哥%s准备吃东西啦…’ %name) while True:# x拿到的是yield接收到的值 x = yield # x = '肉包子' print('道哥%s吃了 %s' %(name,x))
g=dog(‘alex’) g.send(None) # 等同于next(g)
g.send([‘一根骨头’,’aaa’])
g.send(‘肉包子’)
g.send(‘一同泔水’)
g.close()
g.send(‘1111’) # 关闭之后无法传值
2. <br />
```python
def dog(name):
food_list=[]
print('道哥%s准备吃东西啦...' %name)
while True:
# x拿到的是yield接收到的值
x = yield food_list # x = '肉包子'
print('道哥%s吃了 %s' %(name,x))
food_list.append(x) # ['一根骨头','肉包子']
g=dog('alex')
res=g.send(None) # next(g)
print(res)
res=g.send('一根骨头')
print(res)
res=g.send('肉包子')
print(res)
# g.send('一同泔水')
def func():
print('start.....')
x=yield 1111 # x='xxxxx'
print('哈哈哈啊哈')
print('哈哈哈啊哈')
print('哈哈哈啊哈')
print('哈哈哈啊哈')
yield 22222
g=func()
res=next(g)
print(res)
res=g.send('xxxxx')
print(res)
三、三元表达式
针对以下需求
def func(x,y):
if x > y:
return x
else:
return y
res=func(1,2)
print(res)
三元表达式
语法格式: 条件成立时要返回的值 if 条件 else 条件不成立时要返回的值
x=1
y=2
# res=x if x > y else y
# print(res)
res=111111 if 'egon' == 'egon' else 2222222222
print(res)
#应用举例
def func():
# if 1 > 3:
# x=1
# else:
# x=3
x = 1 if 1 > 3 else 3
四、生成式
1、列表生成式
l = ['alex_dsb', 'lxx_dsb', 'wxx_dsb', "xxq_dsb", 'egon']
new_l=[]
for name in l:
if name.endswith('dsb'):
new_l.append(name)
new_l=[name for name in l if name.endswith('dsb')]
new_l=[name for name in l]
print(new_l)
把所有小写字母全变成大写
new_l=[name.upper() for name in l]
print(new_l)
把所有的名字去掉后缀_dsb
new_l=[name.replace(‘_dsb’,’’) for name in l]
print(new_l)
2、字典生成式
keys=['name','age','gender']
dic={key:None for key in keys}
print(dic)
items=[('name','egon'),('age',18),('gender','male')]
res={k:v for k,v in items if k != 'gender'}
print(res)
3、集合生成式
keys=['name','age','gender']
set1={key for key in keys}
print(set1,type(set1))
4、生成器表达式
g=(i for i in range(10) if i > 3)
# !!!!!!!!!!!强调!!!!!!!!!!!!!!!
# 此刻g内部一个值也没有
print(g,type(g))
print(g)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
with open('笔记.txt', mode='rt', encoding='utf-8') as f:
# 方式一:
res=0
for line in f:
res+=len(line)
print(res)
# 方式二:
res=sum([len(line) for line in f])
print(res)
# 方式三 :效率最高
res = sum((len(line) for line in f))
# 上述可以简写为如下形式
res = sum(len(line) for line in f)
print(res)

若有收获,就点个赞吧
0 人点赞
