一、VOC2007介绍
在利用诸如Faster R-CNN等深度学习网络进行目标检测的时候一定需要训练自己的数据集,一般有两种方法:
- 按照VOC2007的格式修改自己的数据格式
- 根据自己的数据格式修改代码
一般推荐第一种方法,因为第一种方法比较简单而且不容易出错,在制作为VOC2007格式的数据集之前,这里可以下载原始VOC2007数据集:VOC2007数据集,来看看这个数据集到底是什么样的:
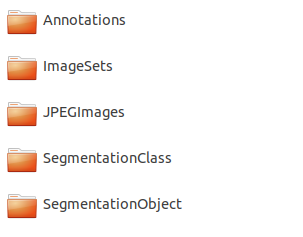
1. 注释
**Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。xml文件的解析如下:
<annotation><folder>VOC2007</folder><filename>2007_000392.jpg</filename> //文件名<source> //图像来源(不重要)<database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image></source><size> //图像尺寸(长宽以及通道数)<width>500</width><height>332</height><depth>3</depth></size><segmented>1</segmented> //是否用于分割(在图像物体识别中01无所谓)<object> //检测到的物体<name>horse</name> //物体类别<pose>Right</pose> //拍摄角度<truncated>0</truncated> //是否被截断(0表示完整)<difficult>0</difficult> //目标是否难以识别(0表示容易识别)<bndbox> //bounding-box(包含左下角和右上角xy坐标)<xmin>100</xmin><ymin>96</ymin><xmax>355</xmax><ymax>324</ymax></bndbox></object><object> //检测到多个物体<name>person</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>198</xmin><ymin>58</ymin><xmax>286</xmax><ymax>197</ymax></bndbox></object></annotation>
2.JPEGImages
**
JPEGImages内部存放了PASCAL VOC所提供的所有的图片信息,包括了训练图片与测试图片
图片的像素尺寸不一样。(在我的数据中由于是裁剪的图片,所以图片大小都是600x1000)
3.ImageSets
**
由于我们只是关注目标检测,所以只需要知道Main文件夹中各个文件的含义:
Main文件夹下包含了每个分类的train.txt、val.txt和trainval.txt。
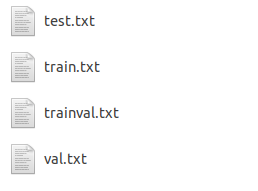
我们制作数据集时也是需要将图片的名称划分为这几个。
二、制作PASCAL VOC形式的数据集
制作自己的VOC2007格式数据集其实不需要那么多内容,我们只要做三个部分即可:Annotations文件夹、JPEGImages文件夹、ImageSets文件夹下的Main文件。
Step 1 : JPEGImages
**
首先我们需要在faster-rcnn.pytorch-pytorch-1.0这个文件下面创建一个data文件夹,然后在data文件夹下面创建一个VOCdevkit2007的文件夹,然后再在这个文件夹中创建VOC2007的文件夹。
/**faster-rcnn.pytorch-pytorch-1.0/data/VOCdevkit2007/**VOC2007/
**
然后再VOC2007这个文件夹下面,创建Annotations、JPEGImages、ImageSets三个文件夹,最后在ImageSets文件夹下再创建一个Main文件夹。
创建好所有文件夹后,我们将自己的数据集图片都放到JPEGImages文件夹下。
注意:按照习惯,最好将所有的图片按照一定的规则重写命名,这样更好进行处理。一般,如果名称在后续没有什么特殊使用,可以按照原数据集里的名称规则命名。
代码:
import ospath = "E:\\image" # 写你图片存储的位置filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)count=0for file in filelist:print(file)for file in filelist: #遍历所有文件Olddir=os.path.join(path,file) #原来的文件路径if os.path.isdir(Olddir): #如果是文件夹则跳过continuefilename=os.path.splitext(file)[0] #文件名filetype=os.path.splitext(file)[1] #文件扩展名Newdir=os.path.join(path,str(count).zfill(6)+filetype)#用字符串函数zfill 以0补全所需位数os.rename(Olddir,Newdir)#重命名count+=1
Step 2 : Annotations
**
标注工具我推荐:LabelImg
github地址:https://github.com/tzutalin/labelImg,有详细安装教程。
下载后进入下载目录,copy到home目录下解压,解压后进入目录:
cd labelImgpython labelImg.py
即可打开界面,进入你存储图片的文件夹,设置标注文件的保存位置Annotations。
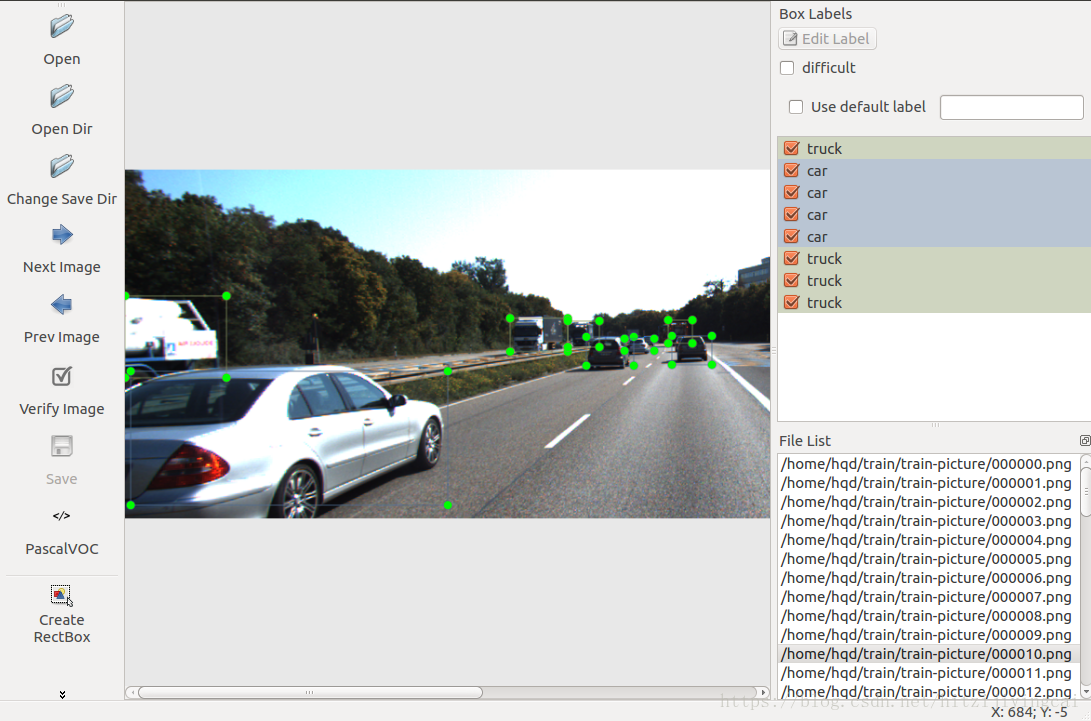
此软件的使用方法:
**
修改默认的XML文件保存位置,使用快捷键“Ctrl+R”,改为自定义位置,这里的路径一定不能包含中文,否则无法保存。
源码文件夹中使用notepad++打开data/predefined_classes.txt,修改默认类别,比如改成person、car、motorcycle三个类别。
“Open Dir”打开图片文件夹,选择第一张图片开始进行标注,使用“Create RectBox”或者“Ctrl+N”开始画框,单击结束画框,再双击选择类别。完成一张图片后点击“Save”保存,此时XML文件已经保存到本地了。点击“Next Image”转到下一张图片。
标注过程中可随时返回进行修改,后保存的文件会覆盖之前的。
完成标注后打开XML文件,发现确实和PASCAL VOC所用格式一样。
step 3:ImageSets
接下来为制作ImageSets文件夹下Main文件夹中的4个文件(test.txt、train.txt、trainval.txt、val.txt)。
首先说明一下这四个文件到底是干什么用的:
test.txt:测试集
train.txt:训练集
val.txt:验证集
trainval.txt:训练和验证集
在原始VOC2007数据集中,trainval大约占整个数据集的50%,test大约为整个数据集的50%;train大约是trainval的50%,val大约为trainval的50%。所以我们可参考以下代码来生成这4个txt文件:
# !/usr/bin/python# -*- coding: utf-8 -*-import osimport randompath = '/home/hans/Documents/optical surface data/Pre_processing data/'trainval_percent = 0.8 # trainval占比例多少train_percent = 0.7 # test数据集占比例多少xmlfilepath = path + 'Annotations'txtsavepath = path + 'ImageSets\Main'total_xml = os.listdir(xmlfilepath)num = len(total_xml)list = range(num)tv = int(num * trainval_percent)tr = int(tv * train_percent)trainval = random.sample(list, tv)train = random.sample(trainval, tr)ftrainval = open(path + 'ImageSets/Main/trainval.txt', 'w')ftest = open(path + 'ImageSets/Main/test.txt', 'w')ftrain = open(path + 'ImageSets/Main/train.txt', 'w')fval = open(path + 'ImageSets/Main/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else:fval.write(name)else:ftest.write(name)ftrainval.close()ftrain.close()fval.close()ftest.close()
Step 4 : 统计相关数据
在制作自己的数据集成功过后,如果想要统计以下你图片中的标注种类,以及Bounding Box的数量时,可以使用并且修改以下代码进行统计:
import reimport osimport xml.etree.ElementTree as ETclass1 = 'xxxxx'class2 = 'xxxxx'annotation_folder = '/Annotations'def file_name(file_dir):L = []for root, dirs, files in os.walk(file_dir):for file in files:if os.path.splitext(file)[1] == '.xml':L.append(os.path.join(root, file))return Ltotal_number1 = 0total_number2 = 0total = 0total_pic = 0pic_num1 = 0pic_num2 = 0flag1 = 0flag2 = 0xml_dirs = file_name(annotation_folder)for i in range(0, len(xml_dirs)):# print(xml_dirs[i])annotation_folder = open(xml_dirs[i]).read()root = ET.fromstring(annotation_folder)total_pic = total_pic + 1for obj in root.findall('object'):label = obj.find('name').textif label == class1:total_number1 = total_number1 + 1flag1 = 1total = total + 1if label == class2:total_number2 = total_number2 + 1flag2 = 1total = total + 1if flag1 == 1:pic_num1 = pic_num1 + 1flag1 = 0if flag2 == 1:pic_num2 = pic_num2 + 1flag2 = 0print("class:", class1, "pic_num:", pic_num1, "BB_num", total_number1)print("class:", class2, "pic_num:", pic_num2, "BB_num", total_number2)print("total_pic", total_pic, "total_BB:", total)
三、使用Pytorch版Faster R-CNN训练自己数据集
使用代码来自:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
确保已经编译好相关的代码,能够直接训练。
我们在回到/**faster-rcnn.pytorch-pytorch-1.0/data**文件夹中,在这个文件夹里面主要存储的是
- 训练数据集 ----VOCdevkit2007
- 骨干网络的预训练模型 ---- pretrained_model
- Faster R-CNN模型参数的保存 ---- cache (进行训练之后才会被创建)
骨干网络的预训练模型下载:
vgg16 :https://filebox.ece.vt.edu/~jw2yang/faster-rcnn/pretrained-base-models/vgg16_caffe.pth
Resnet101:https://filebox.ece.vt.edu/~jw2yang/faster-rcnn/pretrained-basemodels/resnet101_caffe.pth
训练命令示例(单GPU训练):
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py \--dataset pascal_voc --net res101 \--bs $BATCH_SIZE --nw $WORKER_NUMBER \--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP \--cuda'''GPU_ID : 有的电脑默认为0,有点电脑默认为1--dataset pascal_voc : 训练数据集类型pascal_voc--net : 骨干网络选择VGG16,ResNet101--bs : batch_size 默认为1–nw : worker number,取决于你的Gpu能力--lr : learning rate : 一般选取默认值就行,也可以自己选取--lr_decay_step : 同上'''
如果使用多GPU训练:
python trainval_net.py --dataset pascal_voc --net vgg16 \--bs 24 --nw 8 \--lr $LEARNING_RATE --lr_decay_step $DECAY_STEP \--cuda --mGPUs
训好的model会存到models文件夹底下。
如果想要训练自己的数据集,开始前一定要确保data/cache中没有文件,因为这里要保存一些训练用的中间数据。
最后我们只需要将/faster-rcnn.pytorch/lib/datasets/pascal_voc.py中的这行代码:
//类别self._classes = ('__background__', # always index 0'aeroplane', 'bicycle', 'bird', 'boat','bottle', 'bus', 'car', 'cat', 'chair','cow', 'diningtable', 'dog', 'horse','motorbike', 'person', 'pottedplant','sheep', 'sofa', 'train', 'tvmonitor','plane')
除了第一个background之外,将自己数据的标注类别填写上去,就能够进行训练了。

若有收获,就点个赞吧
0 人点赞
