该节博客主要讲解网络的训练流程,以及其中的代码阅读与学习。主要涉及数据的读取与处理和模型的训练,涉及文件有data_loaders.py。
首先我们先来阅读data_loaders.py文件中的代码,了解整个数据读取和处理的流程。
1. 数据的处理流程(data_loaders.py)
def mch(**kwargs):return munch.Munch(dict(**kwargs))def configure_metadata(metadata_root):metadata = mch()metadata.image_ids = os.path.join(metadata_root, 'image_ids.txt')metadata.image_ids_proxy = os.path.join(metadata_root,'image_ids_proxy.txt')metadata.class_labels = os.path.join(metadata_root, 'class_labels.txt')metadata.image_sizes = os.path.join(metadata_root, 'image_sizes.txt')metadata.localization = os.path.join(metadata_root, 'localization.txt')return metadata
以上是读取数据.txt文件的函数,一般txt文本存储着图片的路径,名称(id),标签(label)等的数据形式,截图如下: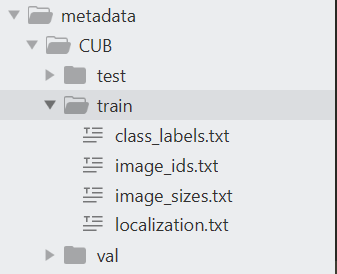
以上的代码就是把路径复制给字典变量。
1)def get_image_ids(metadata, proxy=False)
def get_image_ids(metadata, proxy=False):"""image_ids.txt has the structure<path>path/to/image1.jpgpath/to/image2.jpgpath/to/image3.jpg..."""image_ids = []suffix = '_proxy' if proxy else ''with open(metadata['image_ids' + suffix]) as f:for line in f.readlines():image_ids.append(line.strip('\n'))return image_ids
处理image_ids.txt文件,内容如下: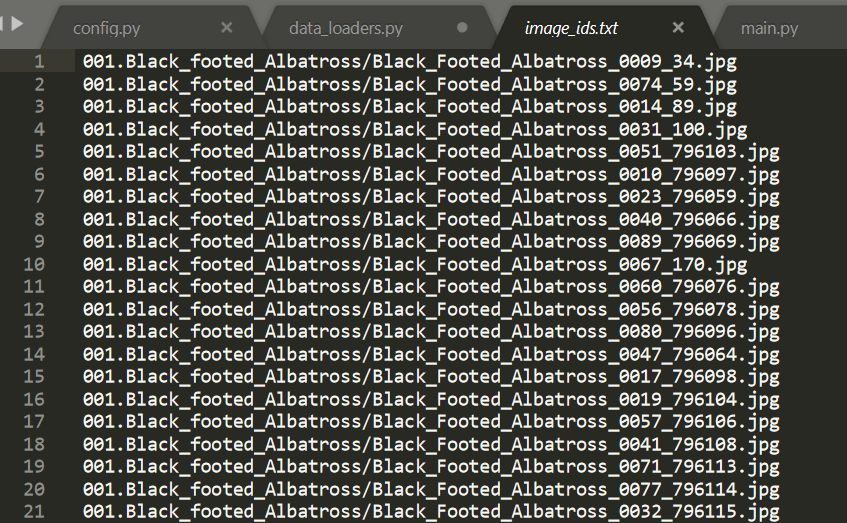
把每一行的图片的id存储到一个list里面。这里都比较简单。
2)def get_class_labels(metadata)
def get_class_labels(metadata):"""image_ids.txt has the structure<path>,<integer_class_label>path/to/image1.jpg,0path/to/image2.jpg,1path/to/image3.jpg,1..."""class_labels = {}with open(metadata.class_labels) as f:for line in f.readlines():image_id, class_label_string = line.strip('\n').split(',')class_labels[image_id] = int(class_label_string)return class_labels
返回数据类型为一个字典,字典的key为image_id,value为class_labels。如图所示:
3)def get_bounding_boxes(metadata)
def get_bounding_boxes(metadata):"""localization.txt (for bounding box) has the structure<path>,<x0>,<y0>,<x1>,<y1>path/to/image1.jpg,156,163,318,230path/to/image1.jpg,23,12,101,259path/to/image2.jpg,143,142,394,248path/to/image3.jpg,28,94,485,303...One image may contain multiple boxes (multiple boxes for the same path)."""boxes = {}with open(metadata.localization) as f:for line in f.readlines():image_id, x0s, x1s, y0s, y1s = line.strip('\n').split(',')x0, x1, y0, y1 = int(x0s), int(x1s), int(y0s), int(y1s)if image_id in boxes:boxes[image_id].append((x0, x1, y0, y1))else:boxes[image_id] = [(x0, x1, y0, y1)]return boxes
这个函数应该是在evaluate的时候用于检测模型的效果,在train的过程中用不到。
返回的boxes也是一个字典,其形式为: {image_id: [(x0, x1, y0, y1)]}
4)def get_mask_paths(metadata)
def get_mask_paths(metadata):"""localization.txt (for masks) has the structure<path>,<link_to_mask_file>,<link_to_ignore_mask_file>path/to/image1.jpg,path/to/mask1a.png,path/to/ignore1.pngpath/to/image1.jpg,path/to/mask1b.png,path/to/image2.jpg,path/to/mask2a.png,path/to/ignore2.pngpath/to/image3.jpg,path/to/mask3a.png,path/to/ignore3.png...One image may contain multiple masks (multiple mask paths for same image).One image contains only one ignore mask."""mask_paths = {}ignore_paths = {}with open(metadata.localization) as f:for line in f.readlines():image_id, mask_path, ignore_path = line.strip('\n').split(',')if image_id in mask_paths:mask_paths[image_id].append(mask_path)assert (len(ignore_path) == 0)else:mask_paths[image_id] = [mask_path]ignore_paths[image_id] = ignore_pathreturn mask_paths, ignore_paths
在训练的过程中用不到,在后面的笔记中看到了再学习,Mark一下!!!!
5)def get_image_sizes
def get_image_sizes(metadata):"""image_sizes.txt has the structure<path>,<w>,<h>path/to/image1.jpg,500,300path/to/image2.jpg,1000,600path/to/image3.jpg,500,300..."""image_sizes = {}with open(metadata.image_sizes) as f:for line in f.readlines():image_id, ws, hs = line.strip('\n').split(',')w, h = int(ws), int(hs)image_sizes[image_id] = (w, h)return image_sizes# 返回同样是一个字典:# type: {image_id:(w, h)}
6)Class WSOLImageLabelDataset(Dataset)
这里才是真正的数据的加载过程。
# 继承自Pytorch的Dataset类class WSOLImageLabelDataset(Dataset):def __init__(self, data_root, metadata_root, transform, proxy,num_sample_per_class=0):self.data_root = data_rootself.metadata = configure_metadata(metadata_root)self.transform = transformself.image_ids = get_image_ids(self.metadata, proxy=proxy)self.image_labels = get_class_labels(self.metadata)self.num_sample_per_class = num_sample_per_classself._adjust_samples_per_class()def _adjust_samples_per_class(self):if self.num_sample_per_class == 0:returnimage_ids = np.array(self.image_ids)image_labels = np.array([self.image_labels[_image_id]for _image_id in self.image_ids])# 把对应image_id的图像标签全部提取出来,构成一个arrayunique_labels = np.unique(image_labels)# np.unique 该函数是去除数组中的重复数字,并进行排序之后输出# 相当于unique_labels里面保存着多少类别的标签new_image_ids = []new_image_labels = {}for _label in unique_labels:indices = np.where(image_labels == _label)[0]# np.where(condition): 返回image_labels 符合condition的array# 对每一个类的数据进行随机抽样sampled_indices = np.random.choice(indices, self.num_sample_per_class, replace=False)sampled_image_ids = image_ids[sampled_indices].tolist()# 对每一类随机抽取的图片id进行收集sampled_image_labels = image_labels[sampled_indices].tolist()# 对每一类随机抽取的图片label进行收集new_image_ids += sampled_image_idsnew_image_labels.update(**dict(zip(sampled_image_ids, sampled_image_labels)))# 将随机抽取的图片的id和label进行整合成字典self.image_ids = new_image_idsself.image_labels = new_image_labelsdef __getitem__(self, idx):image_id = self.image_ids[idx]image_label = self.image_labels[image_id]image = Image.open(os.path.join(self.data_root, image_id))image = image.convert('RGB')image = self.transform(image)return image, image_label, image_iddef __len__(self):return len(self.image_ids)
7)def get_data_loader
def get_data_loader(data_roots, metadata_root, batch_size, workers,resize_size, crop_size, proxy_training_set,num_val_sample_per_class=0):dataset_transforms = dict(train=transforms.Compose([transforms.Resize((resize_size, resize_size)),transforms.RandomCrop(crop_size),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(_IMAGE_MEAN_VALUE, _IMAGE_STD_VALUE)]),val=transforms.Compose([transforms.Resize((crop_size, crop_size)),transforms.ToTensor(),transforms.Normalize(_IMAGE_MEAN_VALUE, _IMAGE_STD_VALUE)]),test=transforms.Compose([transforms.Resize((crop_size, crop_size)),transforms.ToTensor(),transforms.Normalize(_IMAGE_MEAN_VALUE, _IMAGE_STD_VALUE)]))loaders = {split: DataLoader(WSOLImageLabelDataset(data_root=data_roots[split],metadata_root=os.path.join(metadata_root, split),transform=dataset_transforms[split],proxy=proxy_training_set and split == 'train',num_sample_per_class=(num_val_sample_per_classif split == 'val' else 0)),batch_size=batch_size,shuffle=split == 'train',num_workers=workers)for split in _SPLITS}return loaders

若有收获,就点个赞吧
0 人点赞
