一、sampler_batch = sampler(train_size, args.batch_size)
class sampler(Sampler):def __init__(self, train_size, batch_size):self.num_data = train_size # 输入训练集的图片数量由train_size = len(roidb)传入self.num_per_batch = int(train_size / batch_size) #要执行batch的次数self.batch_size = batch_sizeself.range = torch.arange(0,batch_size).view(1, batch_size).long()'''self.range torch.tensor shape [1,batch_size], [[0,1,2,3, ....]]'''self.leftover_flag = Falseif train_size % batch_size:self.leftover = torch.arange(self.num_per_batch*batch_size, train_size).long()self.leftover_flag = Truedef __iter__(self):rand_num = torch.randperm(self.num_per_batch).view(-1,1) * self.batch_size'''randperm功能是随机打乱一个数字序列。语法格式: y = torch.randperm(n) y是把1到n这些数随机打乱得到的一个数字序列。'''self.rand_num = rand_num.expand(self.num_per_batch, self.batch_size) + self.rangeself.rand_num_view = self.rand_num.view(-1)if self.leftover_flag:self.rand_num_view = torch.cat((self.rand_num_view, self.leftover),0)return iter(self.rand_num_view)'''返回的是一个迭代器,长度为训练数据集中的图像总数/batch_size,任意取出一个元素实际上取出来的是连续的4个数值,代表了当前想要选择的训练图像在整个训练数据集中的索引序号iter() 函数用来生成迭代器。可以理解为现在有一个列表,列表中的元素个数是1772/4=443然后列表中的每个元素也是列表,长度为4,而且这4个数值连续,表示从所有参与训练的图像中随机的选择连续的4个序号'''def __len__(self):return self.num_data
二、dataset = roibatchLoader(roidb, ratio_list, ratio_index, args.batch_size, \ imdb.num_classes, training=True)
\faster-rcnn-pytorch-master\lib\roi_data_layer\roibatchLoader.py
class roibatchLoader(data.Dataset):可以看作是torch中dataset的子类
1. roibatchLoader def init()
1).self.ratiolist_batch = torch.Tensor(self.data_size).zero()
长度为1772的torch.tensor 这样得到的torch.tensor中每连续batch size个数值都是相同的, 表示在同一个batch size中的图像设置怎样的宽高比(aspect ratios)
'''给定升序的训练图像集宽高比列表,希望在同一个batch size中的图像具有相同的宽高比'''for i in range(num_batch):left_idx = i*batch_sizeright_idx = min((i+1)*batch_size-1, self.data_size-1)if ratio_list[right_idx] < 1:'''for ratio < 1, we preserve the leftmost in each batch.如果在宽高比列表的升序排列中,最大的宽高比值都小于1,这说明一个连续的batch size都小于1如果原始的输入图像是瘦瘦高高的,那就让他更加瘦瘦高高'''target_ratio = ratio_list[left_idx]elif ratio_list[left_idx] > 1:'''for ratio > 1, we preserve the rightmost in each batch.如果在宽高比例列表的升序排列中,最小的宽高比例值都大于1,说明这一个连续的batch size都大于1如果原始的输入图像是矮矮胖胖的,那就让它更加矮矮胖胖'''target_ratio = ratio_list[right_idx]else:'''for ratio cross 1, we make it to be 1.如果在一个连续batch size的宽高比中,最小的宽高比小于1,最大的宽高比大于1,则就让这一个batch size的宽高比都设定为1'''target_ratio = 1self.ratio_list_batch[left_idx:(right_idx+1)] = target_ratio'''self.ratio_list_batch 长度为1772的torch.tensor这样得到的torch.tensor中每连续batch size个数值都是相同的,表示在同一个batch size中的图像设置怎样的宽高比(aspect ratios)再反观Sampler迭代器,每次产生的列表都是随机,长度为4的连续,且第一个数值必然是4的整数倍就是说能够现在需要保证同一个batch size中的目标宽高比一致'''
2.roibatchLoader def len(self): len(self._roidb)
实际参与的训练图像总数,传入roibatchLoader的实参roidb(列表结构,列表中的每个元素是一个字典)并没有包含完整的图像数据,只是通过roidb[i][‘image’]属性保存了训练图像的完整绝对路径,而通过roidb[i][‘gt_boxes’]属性保存了ground truth 包围框在原始图像上的坐标值。
3.roibatchLoader def getitem(self, index):
1).blobs = get_minibatch(minibatch_db, self._num_classes)
# 在\faster-rcnn-pytorch-master\lib\roi_data_layer\minibatch.pydef get_minibatch(roidb, num_classes):'''param:roidb:一张训练图像的dict信息 imdb.roidb[i]num_classes: 训练数据集中的物体类别return:'''"""Given a roidb, construct a minibatch sampled from it."""num_images = len(roidb)'''因为torch.utilis.data.dataset class的__getitem__方法每次输入一个随机序号故而get_minibatch每次只能处理一张训练图像所对应的gt信息无论训练RPN的batch size设置成多少,num_images=1'''# Sample random scales to use for each image in this batch# npr: import numpy.random as nprrandom_scale_inds = npr.randint(0, high=len(cfg.TRAIN.SCALES),size=num_images)'''numpy.random.randint(low, high=None, size=None, dtype)生成在半开半闭区间[low, high)上离散均匀分布的整数值random_scale_inds 为从0~600中随机选出num_images个的整数值'''assert(cfg.TRAIN.BATCH_SIZE % num_images == 0), \'num_images ({}) must divide BATCH_SIZE ({})'. \format(num_images, cfg.TRAIN.BATCH_SIZE)# Get the input image blob, formatted for caffeim_blob, im_scales = _get_image_blob(roidb, random_scale_inds)'''im_blob 进行减去均值和尺度缩放后的BGR图像,并通过padding方式填充成方形图像BGR 3个通道的均值设定: cfg.PIXEL_MEANS尺度缩放 按照将最短边尺度缩放到600像素的原则,对原始图像进行不改变宽高比例的缩放padding 以缩放后的图像最长边为标准,初始化方形图,将原始图像放在方形图左上角,其他部分以0填充im_scale 缩放尺度'''blobs = {'data': im_blob}assert len(im_scales) == 1, "Single batch only"assert len(roidb) == 1, "Single batch only"'''这里的1并不是只RPN输入图像的batch size,由于对图像进行blob变换是在torch.utils.data.Dataset中的__getitem__()方法中出现的,故而只能对于batch size中的每张图像一张一张地进行处理'''# gt boxes: (x1, y1, x2, y2, cls)if cfg.TRAIN.USE_ALL_GT:# Include all ground truth boxesgt_inds = np.where(roidb[0]['gt_classes'] != 0)[0]'''numpy where 返回满足条件的索引下标,这取决于框的标记形式,我用的数据集中并没有标注背景框,故而就是使用了所有的ground truth包围框对于EAD数据集在标签annotation.txt文件中的类别标签从0到6共有7个类别我人为将标签都加1,让0表示背景'''else:# For the COCO ground truth boxes, exclude the ones that are ''iscrowd''gt_inds = np.where((roidb[0]['gt_classes'] != 0) & np.all(roidb[0]['gt_overlaps'].toarray() > -1.0, axis=1))[0]gt_boxes = np.empty((len(gt_inds), 5), dtype=np.float32)gt_boxes[:, 0:4] = roidb[0]['boxes'][gt_inds, :] * im_scales[0]gt_boxes[:, 4] = roidb[0]['gt_classes'][gt_inds]'''将当前训练图像roidb中的'boxes'和'gt_classes'合并成gt_boxes并将'boxes'中的[xmin ymin xmax ymax]格式的坐标信息变换到新的图像上对gt框的坐标乘以缩放倍数,由于对训练图像进行的变换不仅仅是缩放还包含了paste(paste可以理解成把图像粘贴到一个分辨率更大的画布上)原始图像被粘贴到左上角,其他区域padding 0到这一步为止,不同的输入图像虽然能保证都是方形图,但是分辨率还是可能不相等因为paste操作只是按照尺度缩放后图像的最长边填充的gt_boxes numpy.ndarray shape [#gt_boxes,5]行数为当前图像中的ground truth框个数前四列表示在变换后图像上的gt坐标值最后一列表示包围框的类别(我是根据annotation.txt信息+1)'''blobs['gt_boxes'] = gt_boxesblobs['im_info'] = np.array([[im_blob.shape[1], im_blob.shape[2], im_scales[0]]],dtype=np.float32)blobs['img_id'] = roidb[0]['img_id']return blobs
①.im_blob, im_scales = _get_image_blob(roidb, random_scale_inds)
def _get_image_blob(roidb, scale_inds):"""Builds an input blob from the images in the roidb at the specifiedscales."""num_images = len(roidb)processed_ims = []im_scales = []for i in range(num_images):#im = cv2.imread(roidb[i]['image'])im = imread(roidb[i]['image'])if len(im.shape) == 2:im = im[:,:,np.newaxis]im = np.concatenate((im,im,im), axis=2)# flip the channel, since the original one using cv2# RGB -> BGRim = im[:,:,::-1]'''PIL Image 读取的图像是RGB彩色空间,现在将其转换为 BGR这是因为使用的网络预训练参数caffe pretrained model需要输入图像在BGR彩色空间中如果是pytorch pretrained model,则需要在RGB彩色空间'''if roidb[i]['flipped']:im = im[:, ::-1, :]target_size = cfg.TRAIN.SCALES[scale_inds[i]] # 600im, im_scale = prep_im_for_blob(im, cfg.PIXEL_MEANS, target_size,```` im_scales.append(im_scale) # 关于prep_im_for_blob函数下面解析processed_ims.append(im)# Create a blob to hold the input imagesblob = im_list_to_blob(processed_ims) # 关于im_list_to_blob()函数下面解析return blob, im_scales
blob dict属性及取值
| key | 数据类型 | value |
|---|---|---|
| ‘data’ | numpy.ndarray shape[1,new_height,new_width,3] |
对原始输入图像先变换到BGR彩色空间,再减去3个通道均值,再以将最短边尺度缩放到600为原则对图像缩放(不改变图像的宽高比) |
| ‘gt_boxes’ | numpy.ndarray shape[#num_obgs,5] | 将当前训练图像roidb中的’boxes’和’gt_classes’合并成gt_boxes并将’boxes’中的[xmin ymin xmax ymax]格式的坐标信息变换到新的图像上,对gt框的坐标乘以缩放倍数,最后一列为包围框的类别(我是根据annotation.txt信息+1) |
| ‘im_info’ | numpy.ndarray shape (1, 3) | blob[‘data’] 图像缩放和paste操作后的高度,宽度,以及所放的尺寸。这时图像宽度和高度可能不相等,还是原始输入图像的宽高比 |
| ‘img_id’ | scalar | roidb[0][‘img_id’] |
【1】.def prep_im_for_blob(im, pixel_means, target_size, max_size):
def prep_im_for_blob(im, pixel_means, target_size, max_size):"""Mean subtract and scale an image for use in a blob."""im = im.astype(np.float32, copy=False)im -= pixel_means# im = im[:, :, ::-1]im_shape = im.shapeim_size_min = np.min(im_shape[0:2])im_size_max = np.max(im_shape[0:2])im_scale = float(target_size) / float(im_size_min)# Prevent the biggest axis from being more than MAX_SIZE# if np.round(im_scale * im_size_max) > max_size:# im_scale = float(max_size) / float(im_size_max)# im = imresize(im, im_scale)im = cv2.resize(im, None, None, fx=im_scale, fy=im_scale,interpolation=cv2.INTER_LINEAR)return im, im_scale
这里的返回的 im 是减去三个通道均值与尺度缩放后的image,同时将每张图片的缩放比例的保存在列表im_scale中。
【2】.def im_list_to_blob(ims):
def im_list_to_blob(ims):"""Convert a list of images into a network input.Assumes images are already prepared (means subtracted, BGR order, ...)."""max_shape = np.array([im.shape for im in ims]).max(axis=0)num_images = len(ims)blob = np.zeros((num_images, max_shape[0], max_shape[1], 3),dtype=np.float32)for i in xrange(num_images):im = ims[i]blob[i, 0:im.shape[0], 0:im.shape[1], :] = imreturn blob
(2).index_ratio = int(self.ratio_index[index])
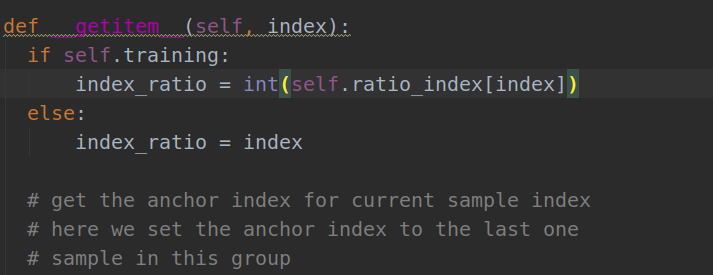
接下来继续看def __getitem__(self. index)方法,到以下函数:
np.random.shuffle的作用:
https://blog.csdn.net/jasonzzj/article/details/53932645
由于我自己的数据集准备时,都是切割成为600x1000的图像所以不需要裁剪,我们直接看到下面尺度缩放部分代码:
# based on the ratio, padding the image.'''将尺度缩放后的宽高比(其实还是原始输入图像的宽高比)通过padding方式转换成目标的宽高比'''if ratio < 1: #ratio=width/height<1 宽度小于高度 high thin image# this means that data_width < data_height# 输入图象是瘦瘦高高的,让它更加瘦瘦高高,# 如果当前图像的width/height<1 则它的目标ratio会更小,说明要对高度进行paddingtrim_size = int(np.floor(data_width / ratio))padding_data = torch.FloatTensor(int(np.ceil(data_width / ratio)), \data_width, 3).zero_()padding_data[:data_height, :, :] = data[0]# update im_infoim_info[0, 0] = padding_data.size(0)# print("height %d %d \n" %(index, anchor_idx))elif ratio > 1:# this means that data_width > data_height# if the image need to crop.# 目标宽高比width/heigth>1 说明原始的输入图像是矮矮胖胖的,则它的目标ratio会更大# 为了让它变得更加矮矮胖胖,就填充宽度,将原始图像paste到左边padding_data = torch.FloatTensor(data_height, \int(np.ceil(data_height * ratio)), 3).zero_()padding_data[:, :data_width, :] = data[0]im_info[0, 1] = padding_data.size(1)else:'''说明目标宽高比=1,输入图像的宽高比就可能小于1也可能大于1,由于经过尺度缩放后图像的最短边成变成了600则现在将图像裁剪到600*600'''trim_size = min(data_height, data_width)padding_data = torch.FloatTensor(trim_size, trim_size, 3).zero_()padding_data = data[0][:trim_size, :trim_size, :]# gt_boxes.clamp_(0, trim_size)gt_boxes[:, :4].clamp_(0, trim_size)im_info[0, 0] = trim_sizeim_info[0, 1] = trim_size
getitem() 输出
| 变量 | 类型 | value |
|---|---|---|
| data | torch.tensor shape [3,H,W] | 其中的数值范围仅仅是BGR图像减去3个通道的均值,并没有归一化到(-1,1)之间 |
| im_info | orch.tensor shape [3] | 真正用于训练的图像高度,宽度,和对图像进行的尺度缩放倍数 |
| gt_boxes | torch.tensor shape [20,5] | 对于当前训练图像的ground truth包围框,是在尺度变换和padding变换之后的图像上的坐标值,最后一列表示包围框的类别 |
| num_boxes | int | gt包围框数量 |
三、总结对输入图像进行的变换
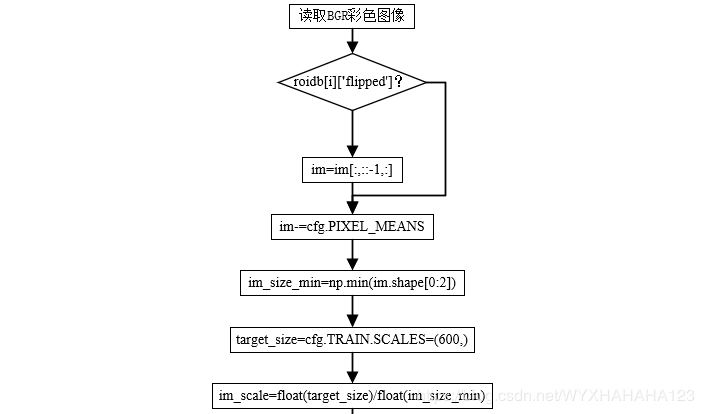
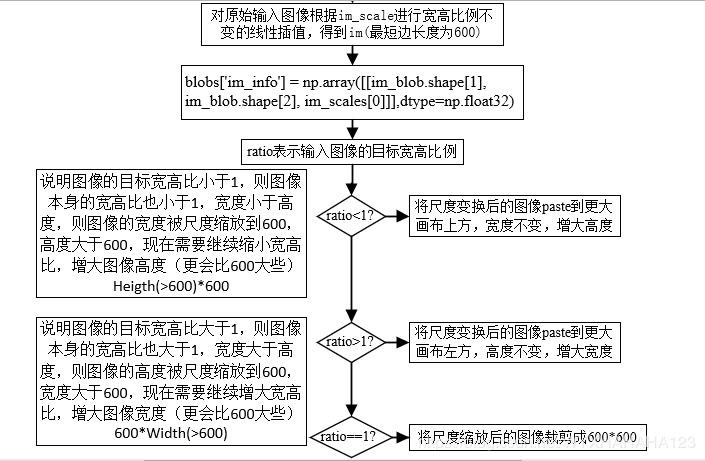
可以看出,这一些列操作后,既要保证同一个batch size的输入图像宽高比相同,又要保证图像的最短边等于600,则能够保证同一batch size的输入图像分辨率完全相同。
关于数据加载的所有内容都结束了,但是整个代码看下来花了几天时间,断断续续,明天在重新整体看下来,画画流程图,复习一下!!!!

若有收获,就点个赞吧
0 人点赞
