参考:
https://blog.csdn.net/WYXHAHAHA123/article/details/86099768
https://blog.csdn.net/w55100/article/details/88529029
这一部分主要学习源码中数据加载的部分。
先给出 https://github.com/jwyang/faster-rcnn.pytorch 的代码文件夹结构:
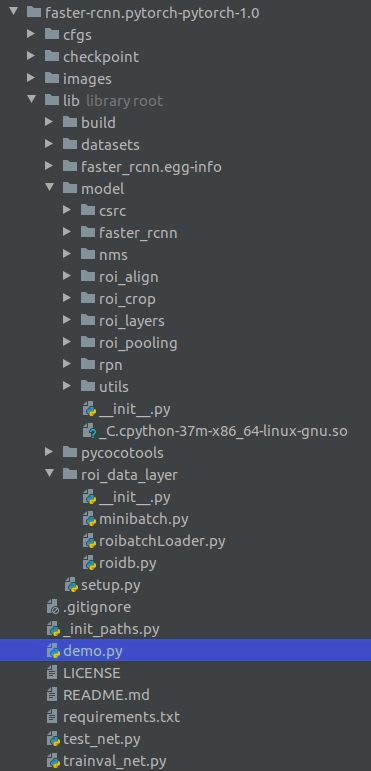
其中faster-rcnn-pytorch-master文件夹直接包含了trainval_net.py和test.py,cfgs文件中给出的是对于网络的配置文件,以cfgs文件夹中的res101.yml为例子:
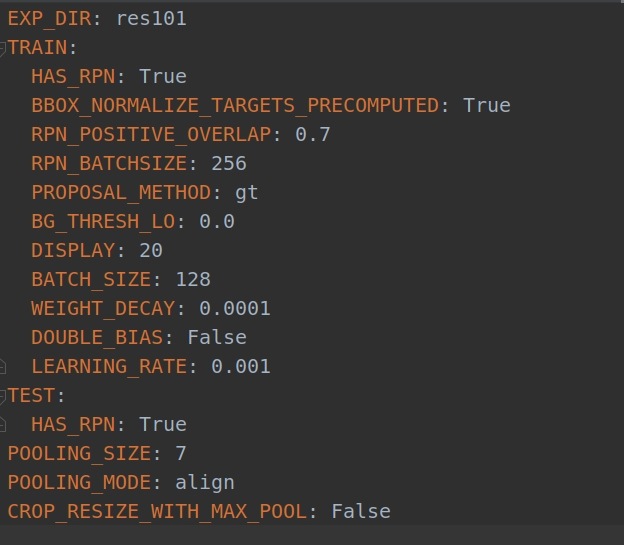
1.RPN_POSITIVE_OVERLAP: 0.7
表示训练RPN时,anchor boxes与ground truth之间的IOU大于0.7则标记为正样本。
2.RPN_BATCHSIZE: 256
表示训练RPN计算损失函数时,将按照faster R-CNN论文中所说,先按照anchor boxes与gt框之间的IOU进行对所有anchor boxes的正负样本划分,所有IOU阈值(overlap)大于0.7被标记为正样本,IOU阈值小于0.3则被标记为负样本,然后随机从所有正样本集和所有负样本集中分别选出128个正样本和128个负样本(比例1:1),计算损失函数。也就是说,对于RPN而言如果是输入一张图像进行训练,则训练RPN的batch size=256,相当于是输入了256个anchor框,而那一张训练图像仅仅是提供所有anchor 框抠取特征的shared feature map。
3.BATCH_SIZE: 128
表示一个batch训练128张图片。
4.POOLING_SIZE: 7
将所有尺寸不同的bounding boxes(这里指的是经过RPN输出后,可以认为此时RPN已经训练好,RPN的功能就类似于selective search算法的作用,为后面fast R-CNN的训练提供大约2000个region proposal)映射到shared feature map,从共享卷积特征图上抠取出特征图后,进行7*7的ROI align或者ROI pooling。
一、def combined_roidb(imdb_names, training=True):
接下来直接看trainval_net.py的main函数部分中的这个函数实现过程:**
imdb, roidb, ratio_list, ratio_index = combined_roidb(args.imdb_name)
使用pycharm的话可以直接用快捷键Ctrl + shift + F 全局查找函数名。
在roidb.py中找到该函数:
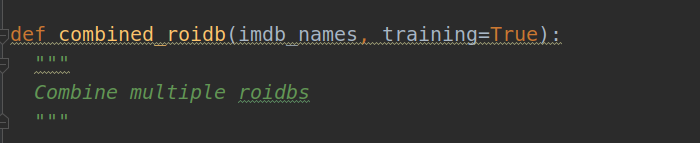
暂且忽略该函数内的def get_training_roidb(imdb)和def get_roidb(imdb_name),先看下面的部分。
此时传入实参在trainval_net.py中

其中def combined_roidb(imdb_names, training=True)的函数操作主要由以下4个部分组成:
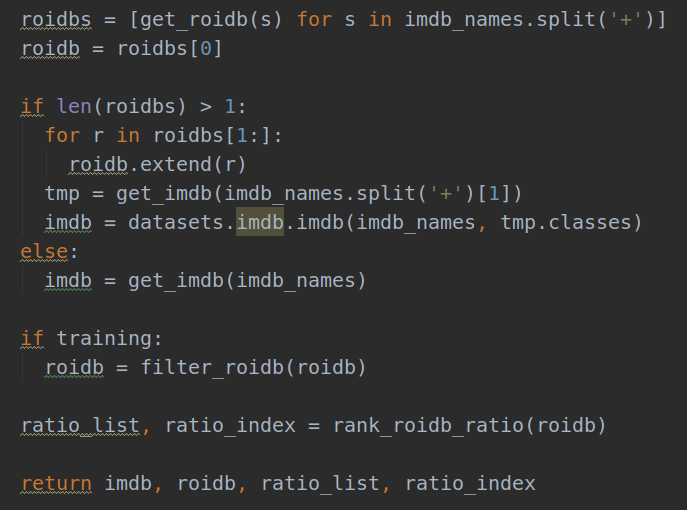
我们按照顺序读下去,第一个函数是:
1. roidbs=get_roidb(imdb_name)
下面是函数get_roidb的代码:
**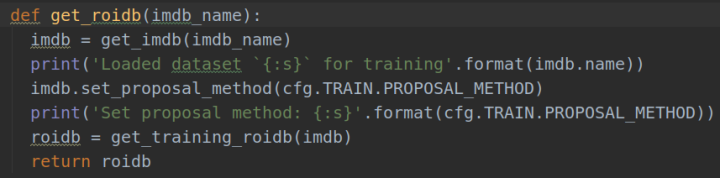
1). imdb = get_imdb(imdb_name) ---factory.py
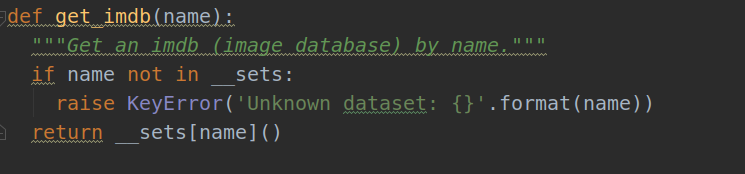
def get_imdb(name):将会返回一个pascal_voc类,在factory.py函数中有一个字典__sets,字典中的key对应与输入的训练数据集名称,value对应于实例化后的数据集类名称。
因为我们传入的实参为:imdb_name = args.imdb_name = 'voc_2007_trainval
所以我们使用的是VOC数据集,我们看factory.py中的代码:
__sets[name] = (lambda split=split, year=year:pascal_voc(split,year))
其中pascal_voc(split, year)就是value所对应的数据集类的名称。
所以imdb = get_imdb(imdb_name)使所有数据集的类class都是imdb class的子
类,能够继承imdb父类的所有方法。
 ,在pascal_voc.py中的class pascal_voc(imdb)是class imdb的子类。
,在pascal_voc.py中的class pascal_voc(imdb)是class imdb的子类。
注意:对于python中的class类,一旦实例化了这个类之后,就会调用class的init方法,在实例化之后的对象的相应属性位置填充content,而不会调用class中所包含的其他方法。
所以我们在imdb.py中找到class imdb(object):所以class pascal_voc(imdb)要继承的是其中的init的方法: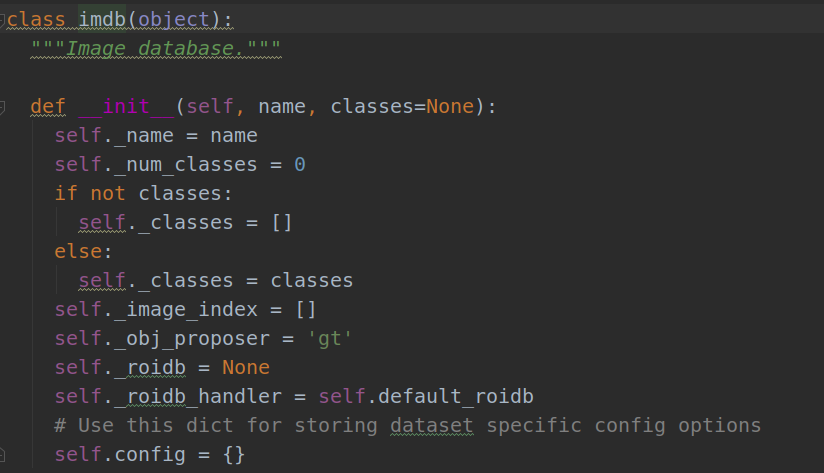
class pascal_voc(imdb):中重要的几个attribution是:
| 类的属性 | 数据类型 | 含义 |
|---|---|---|
| self._data_path | string | 包含训练数据集图像的绝对路径 |
| self._class_to_ind | dict | 在python中将两个列表转换成一个字典将self.classes和xrange(self.numclasses)两个列表合并成一个字典,{‘__background‘:0,aeroplane’:1,’bicycle’:2} |
| self._image_ext | string | 图像后缀名 ‘.jpg’ |
| self._image_index | list | 从包含训练数据集所有图像的txt文件中读取每一行,向列表中append一个表项,列表中的元素顺序与txt文件中行数顺序一致,列表长度为训练数据集中图像数 |
我们看这几个重要的attribution的代码:
1.self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year)
self._devkit_path这个属性的方法是找到数据集存储位置的绝对路径,具体实现方法可以看def _get_default_path(self):的实现方法。再将这些路径合起来之后就是训练数据集所有图像的绝对路径。
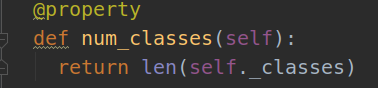
2.self._class_to_ind = dict(zip(self.classes, xrange(self.num_classes)))
xrange(self.num_classes)是生成一个和_classes长度相同的range,具体实现过程在imdb.py中的def num_classes()函数实现。
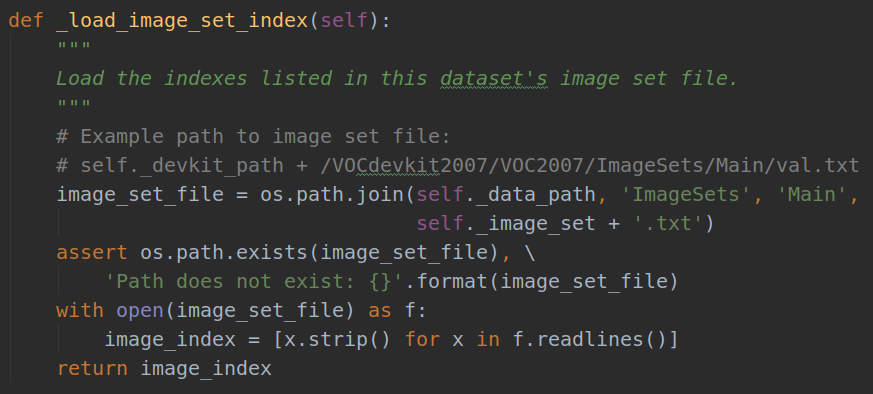
3.self``._image_index = ``self``._load_image_set_index()
2). imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD)
我们将这段代码分开看:
先是调用class imdb(object):中的def set_proposal_method():

传入的参数为cfg.TRAIN.PROPOSAL_METHOD,我们打开文件夹,可以看见cfgs文件夹中的.yml文件,例如打开res101.yml 文件,可以看见PROPOSAL_METHOD: gt,所以整个代码可以改为:
imdb.set_proposal_method(gt)
所以最终该代码执行结果为:self.roidb_handler = self.gt_roidb
这里需要注意,由于self.gt_roidb是类中的方法,则这样的赋值之后是说self.roidb_handler方法与self.gt_roidb方法相同,如果改写成:self.roidb_handler = self.gt_roidb()
则所要表达的意思是self.roidb_handler的值是self.gt_roidb()方法的返回值,则self.roidb_handler可能就是属性而不是方法。
这段代码在阅读时,发现了一个开始没有弄明白的问题,我们仔细看:self.roidb_handler = self.gt_roidb时,发现在父类中self.roidb_handler是调用了其子类pascal_voc(imdb):中的def ``gt_roidb``(``self``):方法,这个好像和之间子类可以继承父类的属性,和调用父类中的方法不太一样,关于这一点可以这样解释:
本身来说class imdb(object):是一个抽象基类,这意味着imbd类只是用作其他类的基础,而不是直接实例化,因此你可以看见在imdb.py代码中的第35行:
self._roidb_handler = self.default_roidb
和后面对类中方法的定义: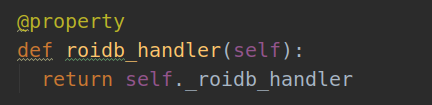
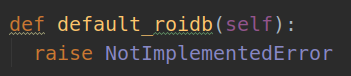
如果直接对该类进行实例化的话,会出现NotImplementedError的报错。
所以说,我们先使用该类中的def ``set_proposal_method``(``self``, ``method):的方法,使得这样赋值self.roidb_handler = self.gt_roidb之后,def roidb_handler():方法不再执行以上会报错的代码,从而完成替换。
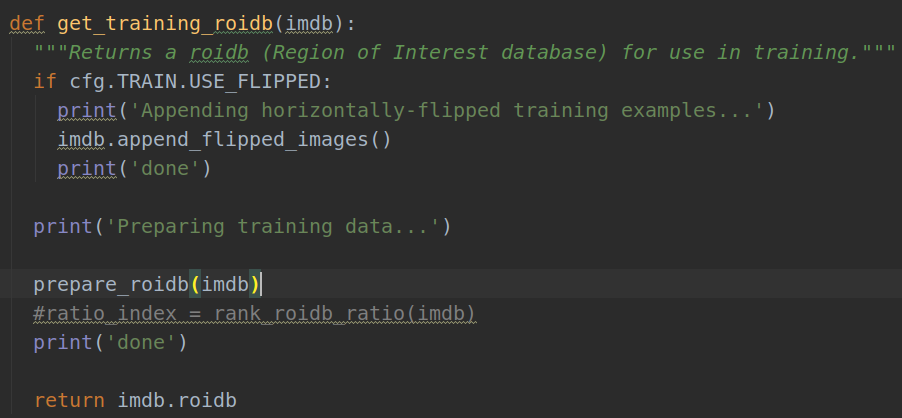
3). roidb = get_training_roidb(imdb)
上面两个步骤已经说明,现在的**imdb**对象是**pascal voc**类,也是**imdb**类的子类。
这句话我是这样理解的,现在的`imdb`类由于之前的赋值(Python中能进行类对类的覆盖赋值,应该是这样?)这段代码:imdb = get_imdb(imdb_name),使得`imdb`对象是`pascal_voc类`,即`imdb`的子类,又由于该代码imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD)**
使得原imdb的一些方法被改变,所以说现在的imdb类可以看做一个新的pascal_voc类,其包含原pascal_voc的属性和方法,继承自父类的属性和方法,以及父类中被修改的新方法。
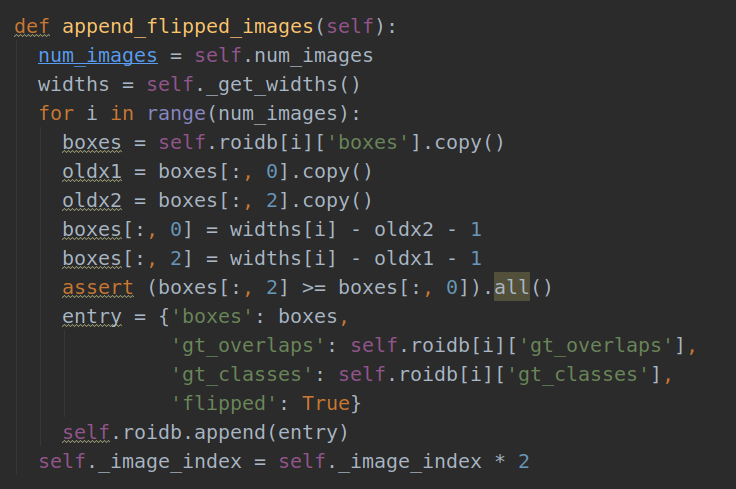
def append_flipped_images(self):是imdb类中的方法,num_images表示当前训练数据集中的图像数。
1.num_images = self.num_images
我们可以看一下这个函数具体的实现过程,可以对上面的解释的理解更加清楚一点:
num_images = self.num_images
调用imdb类中的num_images方法:
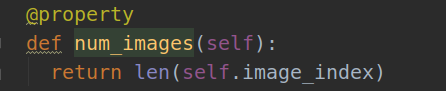
返回值是len(self.image_index),我们再找到此方法:
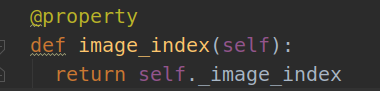
返回self._image_index,那么这个属性又在哪里了?我们可以找到两个分别属于imdb类的属性和pascal_voc类的属性,那么应该是哪一个哪呢?
imdb类中的self._image_index是一个空列表:
pascal_voc类中的self._image_index为:

因为现在的imdb是一个新的pascal_voc类:其包含原pascal_voc的属性和方法,继承自父类的属性和方法,以及父类中被修改的新方法。所以使用imdb中的属性和方法时,如果父类和子类具有相同名称的方法,则实例化子类后的对象调用该方法时,将会调用子类中的相应方法。
即使用self._load_image_set_index()方法:**
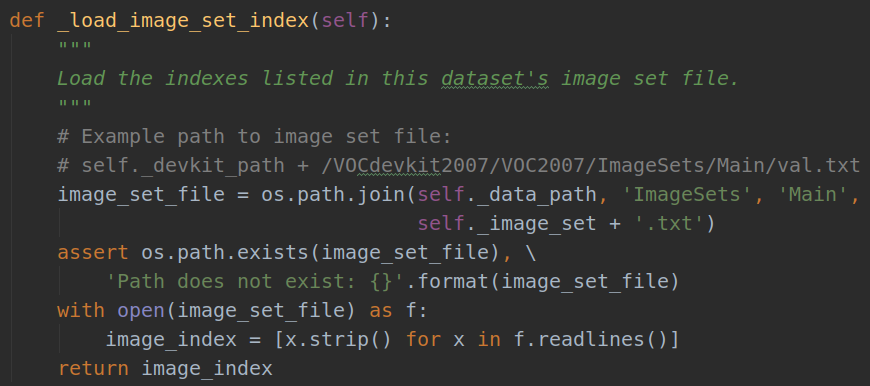
所以num_images表示当前训练数据集中的图像数。
2.widths = ``self``._get_widths()
吐槽一句读这个代码让我想起来一个词——反复横跳!!!!!!!!!
**
去找self._get_widths()方法,就在def def append_flipped_images(self):上面:

So,go to(pascal_voc.py) :def image_path_at(self, i):
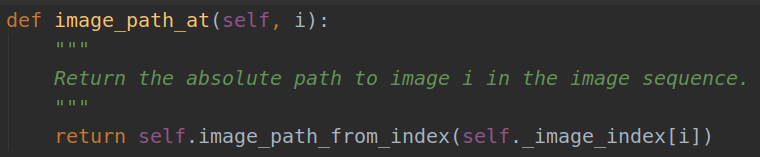
Then go to :def image_path_from_index(self, index):
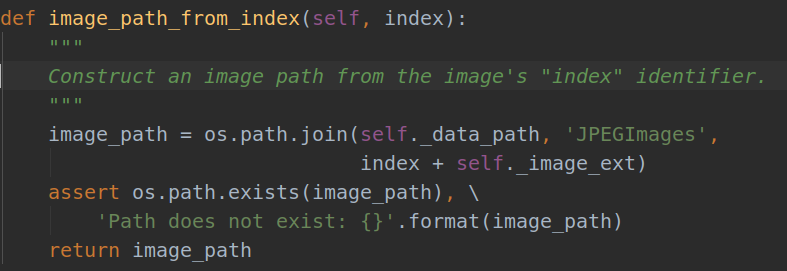
这段代码整个的意思就是:获取每一张图片的绝对路径,然后使用PIL库读取图像的width,组成一个列表。
3.接下来我们来看这个for循环
这里有一个问题:self.roidb是什么时候被填充内容的呢?
此时我们看imdb类中的这段代码:
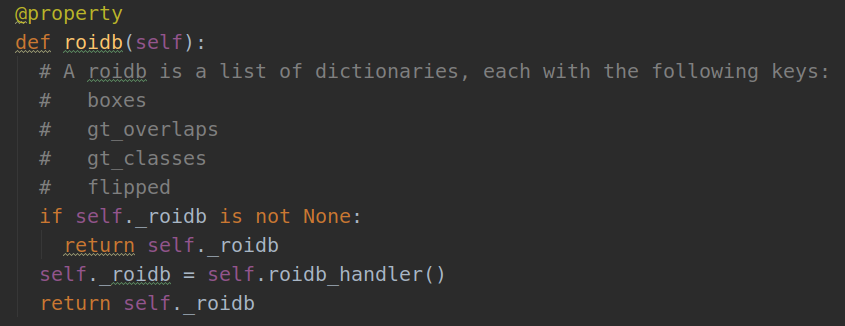
@property 具有将类中的方法封装成属性的功能,虽然封装成属性,但是本质还是方法,属性一般在实例化的时候 如果默认调用的初始化函数没有赋值 那么根据语法给值。虽然方法被封装成了属性,但是每次访问这个属性的时候,都会调用类中的方法。准确的说应该是用了@property 只是让方法能够以属性的语法操作,所以你访问这个属性,其实解释器会调用该方法。每次访问属性,都会调用相应的方法,属性的值是方法的返回值。
如果现在训练数据集中有886张图像,而且每次调用这个@property 方法时都进行计数,则一共会调用886*4=3544次方法。
之前提到imdb对象中self.roidb_handler(imdb类的方法)= self.gt_roidb() (pascal_voc类的方法)
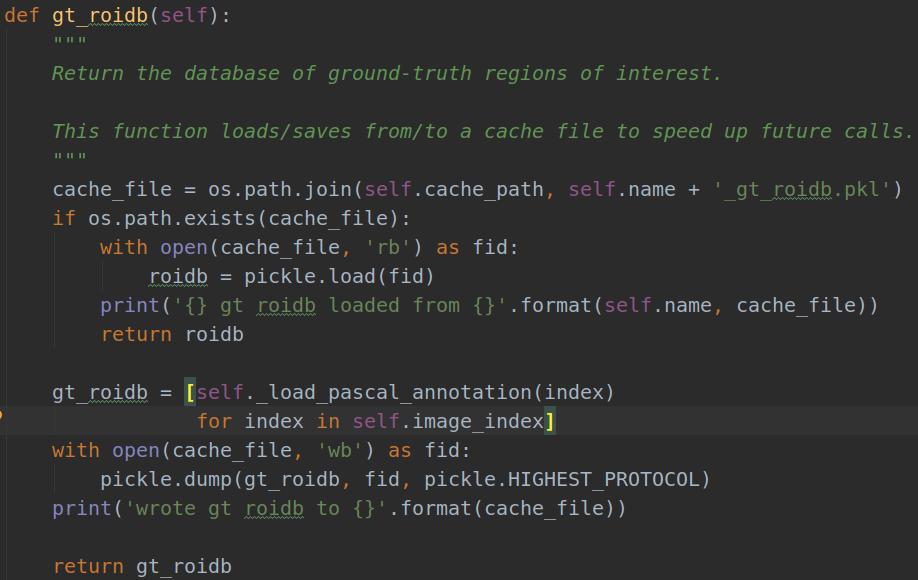
以上代码的意思是:从XML文件中 加载出ground truth的标签数据。我们直接直接看其中的这一段代码:gt_roidb = [self._load_pascal_annotation(index) for index in self.image_index]
So go to: def ``_load_pascal_annotation``(``self``, ``index):
def _load_pascal_annotation(self, index):"""Load image and bounding boxes info from XML file in the PASCAL VOCformat."""filename = os.path.join(self._data_path, 'Annotations', index + '.xml')tree = ET.parse(filename)objs = tree.findall('object')num_objs = len(objs)boxes = np.zeros((num_objs, 4), dtype=np.uint16)gt_classes = np.zeros((num_objs), dtype=np.int32)overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32)# "Seg" area for pascal is just the box areaseg_areas = np.zeros((num_objs), dtype=np.float32)ishards = np.zeros((num_objs), dtype=np.int32)# Load object bounding boxes into a data frame.for ix, obj in enumerate(objs):bbox = obj.find('bndbox')# Make pixel indexes 0-basedx1 = float(bbox.find('xmin').text) - 1y1 = float(bbox.find('ymin').text) - 1x2 = float(bbox.find('xmax').text) - 1y2 = float(bbox.find('ymax').text) - 1diffc = obj.find('difficult')difficult = 0 if diffc == None else int(diffc.text)ishards[ix] = difficultcls = self._class_to_ind[obj.find('name').text.lower().strip()]boxes[ix, :] = [x1, y1, x2, y2]gt_classes[ix] = clsoverlaps[ix, cls] = 1.0seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1)overlaps = scipy.sparse.csr_matrix(overlaps)return {'boxes': boxes,'gt_classes': gt_classes,'gt_ishard': ishards,'gt_overlaps': overlaps,'flipped': False,'seg_areas': seg_areas}
返回值self.roidb是一个字典列表,即还是列表类型,列表中的每个元素是一个字典,列表索引顺序对应的数据集中图像顺序与self.image_index列表一致。列表中的每个元素给出了当前训练图像的ground truth标签信息。
imdb.roidb[i] dict中key value(加入水平flip操作后)
| key | data_type & shape | value |
|---|---|---|
| ‘boxes’ | numpy.ndarray [num_objs, 4] | 表示当前训练图像中所有ground truth包围框的坐标信息,在原始输入图像分辨率上,坐标格式[xmin,ymin,xmax,ymax] |
| ‘gt_classes’ | numpy.ndarray [num_objs] | 表示训练图像中所有ground truth包围框的类别信息,其中数值与imdb._class_to_ind相应数值对应 |
| ‘gt_overlaps’ | numpy.ndarray [num_objs, self.num_classes] | 表示训练图像中每个ground truth包围框的类别,如果某个gt框属于该类别,则数值为1,否则为0,稀疏矩阵 |
| ‘seg_areas’ | numpy.ndarray [num_objs] | 表示训练图像中每个ground truth包围框的面积 |
| ‘flipped’ | bool | 表示训练图像是否需要水平翻转 |
| --------------- | 下面的key和value是在def prepare_roidb(imdb)中产生 |
-------------- |
| ‘img_id’ | scalar | 图像在image_index列表中的序号,经过水平翻转后,self.image_index列表长度是之前的2倍,相当于将之前的列表复制一份,再append到原始的列表后面 |
| ‘image’ | string | 当前训练图像的完整绝对路径(包含后缀名) |
| ‘width’ | scalar | 图像宽度 |
| ‘height’ | scalar | 图像高度 |
经过上述的学习,我们终于把append_flipped_image()这个方法阐述完成了。
下面我们来看prepare_roidb(imd),其作用在函数注释中写的很清楚了:
"""Enrich the imdb's roidb by adding some derived quantities thatare useful for training. This function precomputes the maximumoverlap, taken over ground-truth boxes, between each ROI andeach ground-truth box. The class with maximum overlap is alsorecorded."""
就是对字典列表再增加一些key和value,在以后训练用。
总结:以上是对这个函数的阐述,其实其最终的目的就是ROI 中的database 赋值给roidb.
上述步骤结束后,imdb.roidb就会被赋值给roidb
2.imdb = get_imdb(imdb_names)
这个imdn就是包含所有训练集的图片数据。
3.roidb = filter_roidb(roidb)
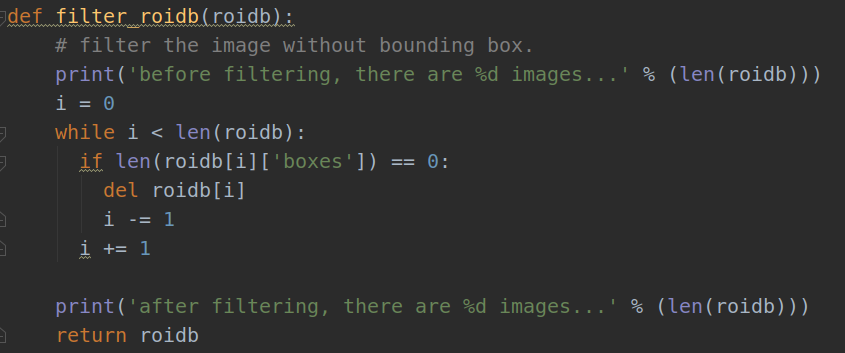
过滤掉所有没有Bounding Box 的图片,排除人工录入txt等环节的错误,注意经过这个环节之后,roidb开始与self._image_index不再一一对应。
4.ratio_list, ratio_index = rank_roidb_ratio(roidb)
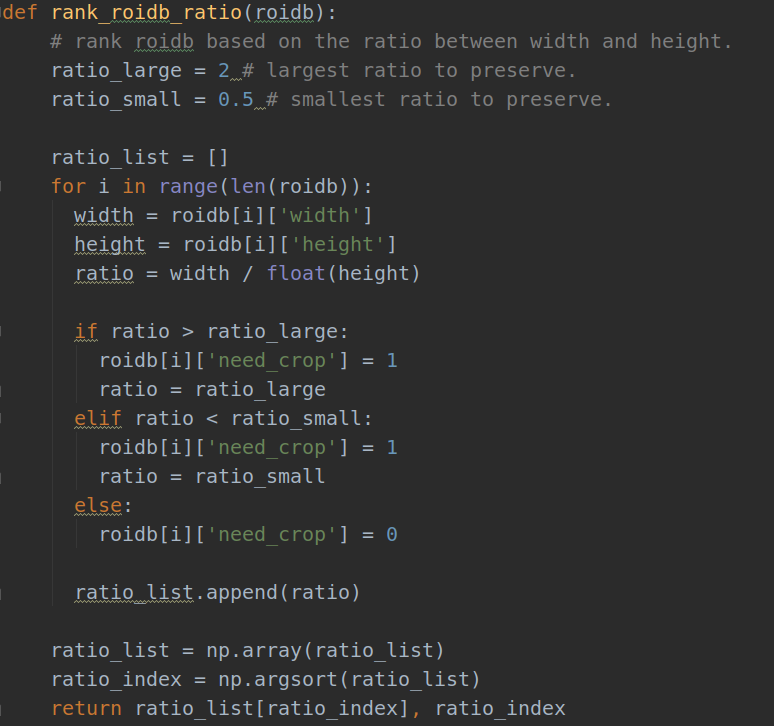
方法的功能是希望训练时,所有输入图像的宽高比能够介于0.5到2之间。
ratio_list返回升序后的宽高比数值,ratio_index为升序后的图像编号(在长度为len(roidb)的编号)。
5.总结
- 上面四个函数组成了完整的预处理roidb功能
- 回顾一下,首先是get_roidb(),在这个函数内调用get_imdb实例化一个Myim类
- 并对这个imdb进行训练化处理get_training_roidb(),在此过程中会prepare_roidb()加几个字段
- 处理好之后,就返回了imdb.roidb

若有收获,就点个赞吧
0 人点赞
