几乎所有的业务项目都会涉及数据存储,虽然当前各种 NoSQL 和文件系统大行其道,但 MySQL 等关系型数据库因为满足 ACID、可靠性高、对开发友好等特点,仍然最常被用于存储重要数据。在关系型数据库中,索引是优化查询性能的重要手段之一。<br />
一、介绍
1.什么是索引
举个字典的例子来比喻最好不过了,数据库的索引就好比是一本字典上的目录,当你想查看字典中的某个汉字时,就可以通过目录快速定位到这个汉字,其实数据库的索引也类似。
2.为什么要有索引呢?
- 索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。
- 索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
- 索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
二、索引的原理
1.索引的原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等<br />**本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。**
2.索引的数据结构
任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。<br />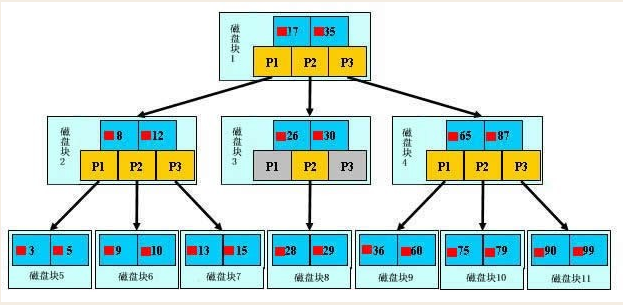<br /> 如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
2.1 b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
2.2 b+树性质
1.索引字段要尽量的小 通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.索引的最左匹配特性(即从左往右匹配) 当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
三、mysql索引分类
1.普通索引index :加速查找
2.唯一索引
- 主键索引:primary key :加速查找+约束(不为空且唯一)
- 唯一索引:unique:加速查找+约束 (唯一)
3.联合索引
四、正确使用索引
1.索引覆盖
select * from s1 where id=123;
该sql命中了索引,但未覆盖索引。
利用id=123到索引的数据结构中定位到该id在硬盘中的位置,或者说再数据表中的位置。
但是我们select的字段为*,除了id以外还需要其他字段,这就意味着,我们通过索引结构取到id还不够,
还需要利用该id再去找到该id所在行的其他字段值,这是需要时间的,很明显,如果我们只select id,
就减去了这份苦恼,如下
select id from s1 where id=123;
这条就是覆盖索引了,命中索引,且从索引的数据结构直接就取到了id在硬盘的地址,速度很快
2.索引的代价
2.1维护代价
创建了索引,当新增、修改、删除数据时,需要维护索引的数据结构。
2.2 空间代价
并不是创建越多的索引越好,创建索引需要占用空间,创建越多,占用的空间越多。
2.3 回表的代价
首先引入一个概念,二级索引,也叫非聚簇索引,所指的是非主键字段的索引。
如上图上的叶子结点保存的并不是实际数据,而是主键,获得主键后再去主键索引中获取数据行,这个过程叫做回表。
五、总结
- 避免使用select *
- count(1)或count(列) 代替 count(*)
- 创建表时尽量时 char 代替 varchar
- 表的字段顺序固定长度的字段优先
- 组合索引代替多个单列索引(经常使用多个条件查询时)
- 尽量使用短索引
- 使用连接(JOIN)来代替子查询(Sub-Queries)
- 定位并删除表中的重复和冗余索引
- 索引散列值(重复少)不适合建索引,例:性别不适合
- 尽量使用覆盖索引进行查询,避免回表带来的性能损耗。

若有收获,就点个赞吧
0 人点赞
