
 有输出的学习才是学习
有输出的学习才是学习
【实践经验】
1、14W 行代码量的前端页面长什么样
https://mp.weixin.qq.com/s/3J8kKArFGjjDFOr4aryNIg
腾讯文档列表页在不久前经历了一次完全重构后,首屏速度其实已经是不错。但是我们仍然可以引入 SSR 来进一步加快速度。这篇文章就是用来记录和整理我最近实现 SSR 遇到的一些问题和思考。本文涉及面甚广,包括Node、React 组件、性能、网络、docker 镜像 、云上部署、灰度和发布等。
2、基于 qiankun 的微前端最佳实践
https://mp.weixin.qq.com/s/5BhiyfP4JtXThz2rO0_P4g
本文分享了如何使用 qiankun 搭建主应用基座,然后接入不同技术栈的微应用,完成微前端架构的从 0 到 1。
3、只使用 CSS 进行用户追踪
https://mp.weixin.qq.com/s/kJG6Kpf2AXqv_wNAp55EPw
在浏览器里进行用户追踪会引发关于隐私和数据保护一次又一次的讨论。类似 Google 分析之类的工具几乎可以抓到所有需要的内容,包括来源,语言,设备,停留时间等等。
但是,想获取一些感兴趣的信息,你可能不需要任何外部追踪器,甚至不需要 JavaScript。本文将向你展示,即便用户禁用了 JavaScript,依然可以跟踪用户的行为。
4、Vue项目打包部署总结
https://mp.weixin.qq.com/s/Iy-ghccRHJNIv5Kxxj3chg
使用Vue做前后端分离项目时,通常前端是单独部署,用户访问的也是前端项目地址,因此前端开发人员很有必要熟悉一下项目部署的流程与各类问题的解决办法了。Vue项目打包部署本身不复杂,不过一些前端同学可能对服务器接触不多,部署过程中还是会遇到这样那样的问题。本文介绍一下使用nginx服务器代理前端项目的方法以及项目部署的相关问题,内容概览: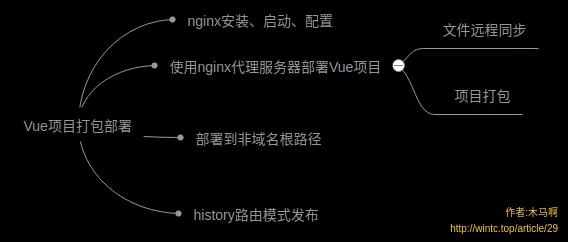
5、NPM 私库从搭建到数据迁移最后容灾备份的一些解决方案
https://www.zoo.team/article/set-up-the-npm-private-library
6、Web 应用高并发的思考与实践
https://mp.weixin.qq.com/s/neRsbfDGfoBG9yoyeVok2A
2020 年初,突如其来的疫情使各行各业都进入紧张状态,互联网产品也各尽其能投入到战“疫”中。健康信息收集是抗疫过程中最基础的工作之一,腾讯问卷平台结合其信息采集、统计分析的特性,快速迭代出“健康打卡”“复学码”等功能。然而,健康码关系着用户能否正常进出社区、公司或校园,计算的时效性和准确性必须有保证。加之用户量大、打卡时间点集中,在开发时间和资源都紧张的情况下,我们是如何应对访问高并发、数据量陡增,从而保障系统的稳定?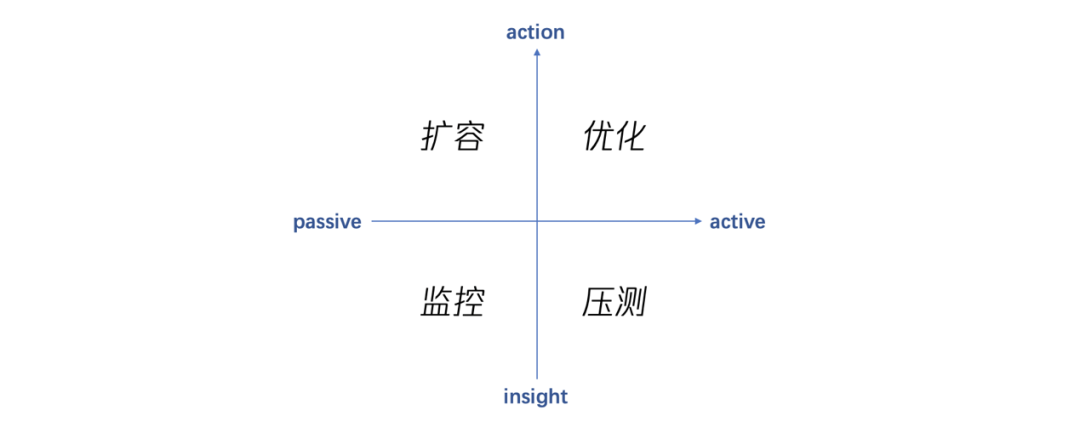
实践围绕图2的四个点,从被动到主动,从发现到治理。这几个方法远远谈不上全面,但可能是短时间内性价比最高的实践。
7、使用Vue自定义指令实现右键菜单
https://juejin.cn/post/6902420248851382285
浏览器里右键时会有一个默认的菜单,在我的开源项目中正好有自定义右键菜单的需求,在npm库找了下与之相关的包,发现都是以组件形式实现的,感觉那种做法太过繁琐。
于是,我就想着能不能像vue的内置指令那样,绑定到元素上,在这个元素上右键就能出现右键菜单,这样做就方便很多了。
看了下vue的自定义指令文档后,经过一番折腾,终于实现我的这个想法,本文就跟大家分享下我的实现思路以及过程,欢迎各位感兴趣的开发者阅读本文。
【基础夯实】
1、万字详文阐释程序员修炼之道
https://mp.weixin.qq.com/s/XIwfj_AdZqX_vHM4VIq9EA
我写过一篇《Code Review 我都 CR 些什么》,讲解了 Code Review 对团队有什么价值,我认为 CR 最重要的原则有哪些。最近我在团队工作中还发现了:
- 原则不清晰。对于代码架构的原则,编码的追求,我的骨干员工对它的认识也不是很全面。当前还是在 review 过程中我对他们口口相传,总有遗漏。
- 从知道到会做需要时间。我需要反复跟他们补充 review 他们漏掉的点,他们才能完成吸收、内化,在后续的 review 过程中,能自己提出这些 review 的点。
过度文档化是有害的,当过多的内容需要被阅读,工程师们最终就会选择不去读,读了也仅仅能吸收很少一部分。在 google,对于代码细节的理解,更多还是口口相传,在实践中去感受和理解。但是,适当的文档、文字宣传,是必要的。特此,我就又输出了这一篇文章,尝试从’知名架构原则’、’工程师的自我修养’、’不能上升到原则的几个常见案例’三大模块,把我个人的经验系统地输出,供其他团队参考。
2、我是如何阅读源码的
https://juejin.cn/post/6903335881227108366
本文介绍了作者阅读React、Vue源码的心得:
有输出的学习才是学习,在阅读源码的过程中,一定得边看边思考,思考的过程中,还需要形成文字记录,如果只是一直盯着代码看,很难理解。
我在看源码的过程中,会一直思考,怎么样才能将这部分讲给别人听,是不是能写个 Demo 之类的,让大家跟着我的思路来学习。这样即让自己学懂了,又可以将学习的过程分享出来帮助到其他人,何乐而不为。
3、TypeScript 核心概念梳理
https://mp.weixin.qq.com/s/A06ljaOWpiQv_o-_TpbdzQ
本文主要是做减法,梳理出核心的点,能够先用起来,然后按工作需要找一些点逐个进行深入学习。
4、你应该知道的前端小知识
https://juejin.cn/post/6898168495591292942
5、【🚨万字警告】了不起的Vue3(上)
https://juejin.cn/post/6898120355781705736
本文主体脉络分为三个部分:Vue3重写的动机、优化的原理,以及Vue3带来了什么值得一看的新东西。
内容方面具体的划分为如下脑图所示:
6、进阶:玩转 CSS 变量
https://mp.weixin.qq.com/s/Wf0mwn0kcKA4joljKu1jHg
【实用工具】
1、求你别再用swagger了,给你推荐几个在线文档生成神器
| 名称 | 优点 | 缺点 |
|---|---|---|
| gitbook | 使用起来非常简单,支持全文搜索,可以跟git完美集成,对代码无任何嵌入性,支持markdown格式的文档编写。 | 需要单独维护一个文档项目,如果接口修改了,需要手动去修改这个文档项目,不然可能会出现接口和文档不一致的情况。并且,不支持在线调试功能。 |
| smart-doc | 基于接口源码分析生成接口文档,零注解侵入,支持html、pdf、markdown格式的文件导出。 | 需要引入额外的jar包,不支持在线调试。个人建议:如果实时生成文档,但是又不想打一些额外的注解,比如:使用swagger时需要打上@Api、@ApiModel等注解,就可以使用这个。 |
| redoc | 非常方便生成文档,三面板设计 | 不支持中文搜索,分为:普通版本 和 付费版本,普通版本不支持在线调试。另外UI交互个人感觉不适合国内大多数程序员的操作习惯。个人建议:如果想快速搭建一个基于swagger的文档,并且不要求在线调试功能,可以使用这个。 |
| knife4j | 基于swagger生成实时在线文档,支持在线调试,全局参数、国际化、访问权限控制等,功能非常强大。 | 界面有一点点丑,需要依赖额外的jar包。个人建议:如果公司对ui要求不太高,可以使用这个文档生成工具,比较功能还是比较强大的。 |
| yapi | 功能非常强大,支持权限管理、在线调试、接口自动化测试、插件开发等,BAT等大厂等在使用,说明功能很好。 | 在线调试功能需要安装插件,用户体检稍微有点不好,主要是为了解决跨域问题,可能有安全性问题。不过要解决这个问题,可以自己实现一个插件,应该不难。个人建议:如果不考虑插件安全的安全性问题,这个在线文档工具还是非常好用的,可以说是一个神器,笔者在这里强烈推荐一下。 |
| apidoc | 基于代码注释生成在线文档,对代码的嵌入性比较小,支持多种语言,跨平台,也可自定义模板。支持搜索和在线调试功能。 | 需要在注释中增加指定注解,如果代码参数或类型有修改,需要同步修改注解相关内容,有一定的维护工作量。个人建议:这种在线文档生成工具提供了另外一种思路,swagger是在代码中加注解,而apidoc是在注解中加数据,代码嵌入性更小,推荐使用。 |
| showdoc | 支持项目权限管理,多种格式文件导入,全文搜索等功能,使用起来还是非常方便的。并且既支持部署自己的服务器,也支持在线托管两种方式。 | 不支持在线调试功能 个人建议:如果不要求在线调试功能,这个在线文档工具值得使用。 |
2、手撸一个在线css三角形生成器
https://juejin.cn/post/6903083072661487624
为了提高 前端开发 效率, 笔者先后写了上百个前端工具, 有些是给公司内部使用的, 有些单纯是因为自己太“懒”, 不想写代码, 所以才“被迫”做的,接下来介绍的一款工具——css三角形生成器也是因为之前想要解放设计师的生产力,自己又懒得切图或者写css代码,所以想来想去还是自己做一个能自动生成css三角形代码的工具吧。接下来笔者就来带大家介绍一下这个工具的用途和实现方案, 方便大家后续可以扩展出更多的“懒人工具”。
【动态与研究关注】
1、Vue Router 4.0 正式发布!
https://mp.weixin.qq.com/s/vdCSZ2inkJ56FiQ8cwMUvw
等不及想试试 Vue Router 4 了?这里有CodeSandbox,还有集成好 Tailwind CSS 的 Vite 模板,或使用CLI来开始你的游玩。
想学习 Vue Router 4 的更多先进理念了?请立刻查看我们的新文档。 如果您是现有的 Vue 2.x 用户,请直接转到迁移指南。
发布地址:https://github.com/vuejs/vue-router-next/releases/tag/v4.0.0
2、Vue3有哪些不向下兼容的改变
https://padaker.com/blog/post/5fc73352cb81362ed96f2fb9
3、Chrome 87浏览器发布!获多年来性能最大提升,还有新图标和新功能
https://mp.weixin.qq.com/s/arJe36fWJh63VOh071yRpw
11月18日,谷歌发布了Chrome 87正式版更新,适配Windows PC、Mac、Linux、Android、iOS等。
Chrome产品总监Matt Waddell在一篇博客文章中写道:该版本是多年来Chrome浏览器性能获得最大提升的一次。
据介绍,Chrome 87在速度、内存占用率方面都进行了重大改进,还增加了一些新UI和有趣的新功能。
值得一提的是,该版本也是2020年的最后一个版本——下个月西方国家就要过圣诞节了。
4、Chrome浏览器Referrer-Policy默认值变更
https://www.yuque.com/alibabaf2e/gt3np7/nbcb65
在Chrome 85中,有个很重要的变化:将Referrer-Policy默认值从no-referrer-when-downgrade改为strict-origin-when-cross-origin,它会对埋点、网站分析等功能造成影响。本文会详细介绍这个变化,文章分为以下几个部分:前置知识、变化原因、影响范围、处理方案。
5、全新的postmessage库特性介绍与源码解析
https://mp.weixin.qq.com/s/p8XZA8lEqms09x6d7Kuw7w
window.postMessage() 方法可以安全地实现跨源通信。通常,对于两个不同页面的脚本,只有当执行它们的页面位于具有相同的协议(通常为 https),端口号(443 为 https 的默认值),以及主机 (两个页面的模数 Document.domain 设置为相同的值) 时,这两个脚本才能相互通信。window.postMessage() 方法提供了一种受控机制来规避此限制,只要正确的使用,这种方法就很安全。
而这篇文章要介绍的是另一个新开源的 postmessage 库:postmessagejs ( npm 包名:postmessage-promise,后文都用此名)。
有人可能会问:用 postmate 不就行了吗,怎么又造一个轮子?看官勿急,且听我细细道来。
6、淘系资深技术专家接受InfoQ采访表示:端智能必将成为驱动业务创新的核心推动力
https://mp.weixin.qq.com/s/bCrH6PZrOcvRlBUNGq7pOw
具体来看,业界端智能的发展可以从以下三个角度来看:
- 从技术角度看,解决的问题是逐步递进的。从最初模型运行基础问题,再到效率和规模应用问题,具体包括:算法模型如何在端侧运行?算法模型如何快速迭代部署?如何降低端 AI 技术门槛实现普及应用?
- 从算法角度看,端侧算法不断成熟和完善。从最初的人脸检测,到人体姿态、手势、OCR 等逐步成熟。除视觉模型外,像搜索推荐深度模型、语音 ASR 模型和 NLP 模型在端侧运行也逐步变得可能,比如:我们今年基于 MNN 实现了移动端实时语音识别方案,并且在双 11 淘宝直播”一猜到底”活动中取得很好的业务效果。
- 从应用角度看,整体应用范围不断拓展和深入。从最初单点场景比如淘宝拍立淘场景,到多 App 和多场景全面铺开,不完全统计,阿里基于 MNN 的端智能应用已经超过 30 个。
【程序之外】
1、体验度量专题|易用度在企业级中后台产品的探索和实践
https://mp.weixin.qq.com/s/sX9SauijjXfQ6bOcJaCluQ
易用度,英文 Customer Effort Score ,简称「易用度」,也有译成「费力度」,指的是用户使用某个产品/服务来解决问题的难易程度。目的是消除或减少用户使用产品过程中的障碍。
该定义来自 2010年 《哈佛商业评论》发表的文章《Stop Trying to Delight Your Customers》。2013年,Gartner 子公司 CEB 发布易用度2.0版本的测量方法,定义为“解决问题的难易程度”(make it easy to handle my issue)。
它的源头可以追溯到美国用户研究专家 Jeff Sauro(2009)提出的单项难易度问卷(Single Ease Question,SEQ),在可用性测试之后,用户需要对一个问题进行打分,问法是“整体上,这个任务是非常困难-非常容易(7分制)”。
为什么说「易用度」更适合技术类的产品?主要基于技术类产品的三大特点。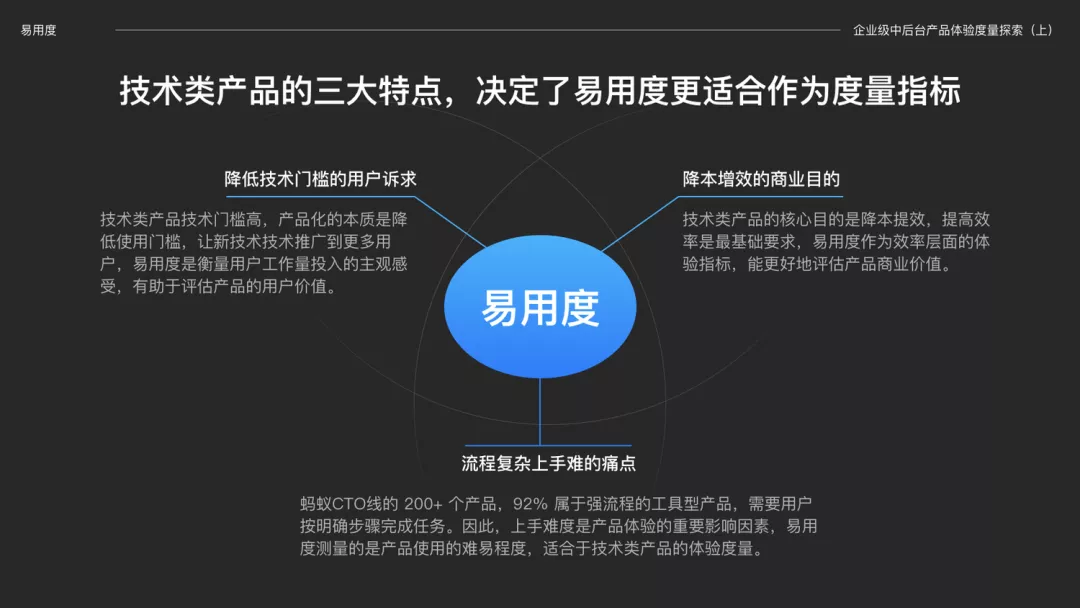
2、使用简单的逻辑方法进行独立思考
https://coolshell.cn/articles/20533.html
这是一个非常复杂的世界,这个世界上有很多各式各样的观点和思维方式,作为一个程序员的我,也会有程序员的思维方式,程序员的思维方式更接近数学的思维方式,数学的思维方式让可以很容易地理清楚这个混乱的世界,其实,并不需要太复杂的数学逻辑,只需要使用一些简单的数学方法,就可以大幅提升自己的认识能力,所以,在这里,记录一篇我自己的思维方式,一方面给大家做个参考,另一方面也供更高阶的人给我进行指正。算是“开源我的思维方式”,开放不仅仅是为了输出,更是为了看看有没有更好的方式。
3、陌生人社交设计引力公式
https://isux.tencent.com/articles/474.html
互联网提供丰富的物质与信息让我们尽情享受自己的空间,让世界近到我们可以触手可及。但没有人是一座孤岛,繁忙的工作让我们接触到的人和圈子是非常有限的,陌生人社交是人们获得陪伴的一剂“良药”,但那个对的人又往往远到遥不可及。
4、IBM研究者教你玩转卡诺模型
Kano模型是由Noriaki Kano教授在20世纪80年代提出的产品研发和客户满意度理论,将用户偏好分为五类。它通过评估每种功能的2套衡量标准:满意度和情感度,来提供帮助我们了解客户对产品功能的看法。这2种衡量标准的组合形成五类属性:魅力属性、期望属性(线性属性)、无差异属性(次要属性)、必备属性和反向属性。
卡诺模型非常擅长对功能进行优先级排序。卡诺模型的基础理论是Daniel Zacarias提出的“喜悦的自然衰减”。创新的想法和产品总会从令人兴奋的新颖功能(在Kano图表的顶部:魅力)转变成预期的功能(在底部:最好的必备,被贬损的,最糟糕的)。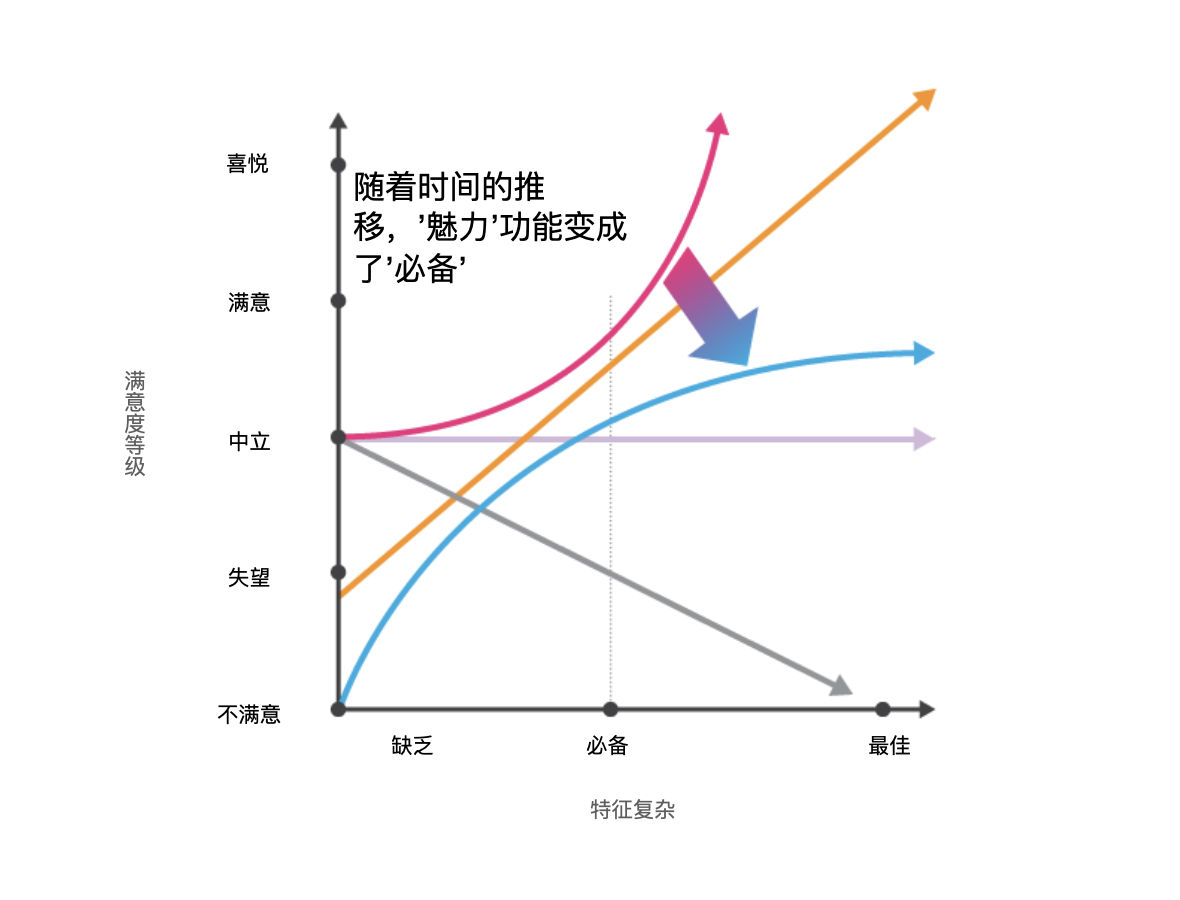
5、用户说的都是真的吗?这些陷阱要避开
https://jdc.jd.com/archives/212987
认知偏误(Cognitive bias)是一种常见的现象,它是指当我们思考问题或做决策时,大脑会有一些固定的思维倾向。这个过程多是无意识的,有时也会带来正面作用,如帮助我们在纷繁复杂的环境中节省思考时间,更高效地做出决定但是在研究中,认知偏误易导致研究结果不准确,降低研究的价值。
我们都希望研究是客观、理性、反映真实情况的,了解常见的认知偏误可以帮助我们在工作中尽量规避它们,得出更准确的结论。
实际上每个人都会有认知偏误,包括用户研究者和用户。
上次我们介绍了研究者的常见认知偏误,今天我们就来谈谈用户的常见认知偏误。
6、大厂的 404 页面都长啥样?看到最后一个,我笑了~

若有收获,就点个赞吧
0 人点赞
