说起文件上传,我们往往停留在type=”file”和 var formData = new FormData()的层次,然而这些还不够,想深入优化,想做更好的安全策略。我们必须更加深入一点,理解我们给后端传递图片到底做了什么。
首先要明确一点,现代浏览器的普遍做法是,我们给后端传递一个二进制的文件流,当然,你也可以用一个对象包裹文件流,并传递其他参数等等。
*文件上传的难点:
在文件上传中,我们往往面临如下问题:
文件过大怎么办-切片?
断点续传怎么实现
- 断点续传如何判断文件的唯一性(MD5\hash值)
断点续传判断文件唯一性的时候,计算md5如何不卡顿(控制并发数量)
控制并发数量时候如何根据网速动态控制包的大小
**上面可简单总结为:并发数量 + 包控制**
切片上传时候出错怎么重试,怎么终止
如何限制文件上传格式-二进制流头文件信息判断
**
下面我们层层递进,按照深度由浅入深来了解一下:
1、判断文件格式
最常用的方法input的accept属性可以限制,以及获取到的file.type可以获取文件格式。其实这两种判断是不准确的,这种判断方式是通过split方法获取的文件后缀名,包括你图片转为base64获取到的字符串头信息也是文件后缀名判断的。
我们可以做一个实验,将一个jpg文件改为png后来获取文件type信息,我们会发现type信息变为png了。然而实际上,文件依然是jpg格式的。因为文件是以二进制形式存储以及给后端传递的。
我们判断文件格式,最正确的方式是先将图片转为二进制流,然后获取文件的二进制头信息来判断,而且转为二进制流的文件是无法进行修改的。具有可靠的安全性。
常见图片的二进制流头信息判断如下:
1)所有png图片的二进制流前八位头信息是一样的-
文件头标识 (8 bytes) 89 50 4E 47 0D 0A 1A 0A
2)jpg的文件头标识 (2 bytes):
开头标识:FF, D8 (SOI) (JPEG 文件标识)
- 文件结束标识 (2 bytes): FF, D9 (EOI)3)GIF - 文件头标识 (6 bytes) 47 49 46 38 39(37) 61
4)BMP文件头标识 (2 bytes) 42 4D
将一个文件转为二进制流
1)文件转为base64字符串
下面列举几种方法:
var fileInput = document.getElementById("image_upload");//选择文件fileInput.addEventListener('change', function () {//如果未传入文件则中断if (fileInput.files[0] == undefined) {return}var file = fileInput.files[0];var reader = new FileReader();reader.readAsDataURL(file);reader.onload = function () {var base64Str = this.result;return base64Str}})
重绘canvas转为base64
function getImgToBase64(url,callback){//将图片转换为Base64var canvas = document.createElement('canvas'),ctx = canvas.getContext('2d'),img = new Image;img.crossOrigin = 'Anonymous';img.onload = function(){canvas.height = img.height;canvas.width = img.width;ctx.drawImage(img,0,0);var dataURL = canvas.toDataURL('image/png');callback(dataURL);canvas = null;};img.src = url;}
具体实现方法很多,自行问度娘。
2)图片转二进制
转二进制对象
// 将base64转为二进制流// 该方法接受一个base64字符串,进行处理function dataURLtoBlob(base64) {var arr = base64.split(','),mime = arr[0].match(/:(.*?);/)[1],bstr = atob(arr[1]),n = bstr.length,u8arr = new Uint8Array(n);while (n--) {u8arr[n] = bstr.charCodeAt(n);}return new Blob([u8arr], {type: mime});}
上面方法得到的是binary对象。
转二进制string
我们需要的是文件转为二进制字符串,方法如下:
// file转二进制stringblobToString = function (blob) {return new Promise(resolve => {const reader = new FileReader()reader.onload = function () {const ret = reader.result.split('').map(v => v.charCodeAt()).map(v => v.toString(16).toUpperCase()).map(v => v.padStart(2, '0')).join(' ')resolve(ret)}reader.readAsBinaryString(blob)})}/**判断方法如下jpg格式的*我们的文件是blob对象,可以直接使用blob.slice方法*/const isJpg = async function (file) {const len = file.sizeconst start = await blobToString(file.slice(0, 2))const tail = await blobToString(file.slice(-2, len))const isjpg = start === 'FF D8' && tail === 'FF D9'return isjpg}// png格式的const isPng = async function (file) {const ret = await this.blobToString(file.slice(0, 8))const ispng = ret === '89 50 4E 47 0D 0A 1A 0A'return ispng}// gif格式的const isGif = async function (file) {const ret = await this.blobToString(file.slice(0, 6))const isgif = (ret === '47 49 46 38 39 61') || (ret === '47 49 46 38 37 61')return isgif// 文件头16进制 47 49 46 38 39 61 或者47 49 46 38 37 61// 分别仕89年和87年的规范// const tmp = '47 49 46 38 39 61'.split(' ')// .map(v=>parseInt(v,16))// .map(v=>String.fromCharCode(v))// console.log('gif头信息',tmp)// // 或者把字符串转为16进制 两个方法用那个都行// const tmp1 = 'GIF89a'.split('')// .map(v=>v.charCodeAt())// .map(v=>v.toString(16))// console.log('gif头信息',tmp1)// return ret ==='GIF89a' || ret==='GIF87a'// 文件头标识 (6 bytes) 47 49 46 38 39(37) 61}
有了上面的判断方法就无惧某些坏小子更改文件后缀绕过校验了。
2、文件切片
对于文件过大的时候,我相信很多人都知道要进行文件切片,我们通过blob.slice方法将切片的数据放入一个数组中(习惯命名为chunks)。然后进行分段上传。
画一个简易的流程图吧: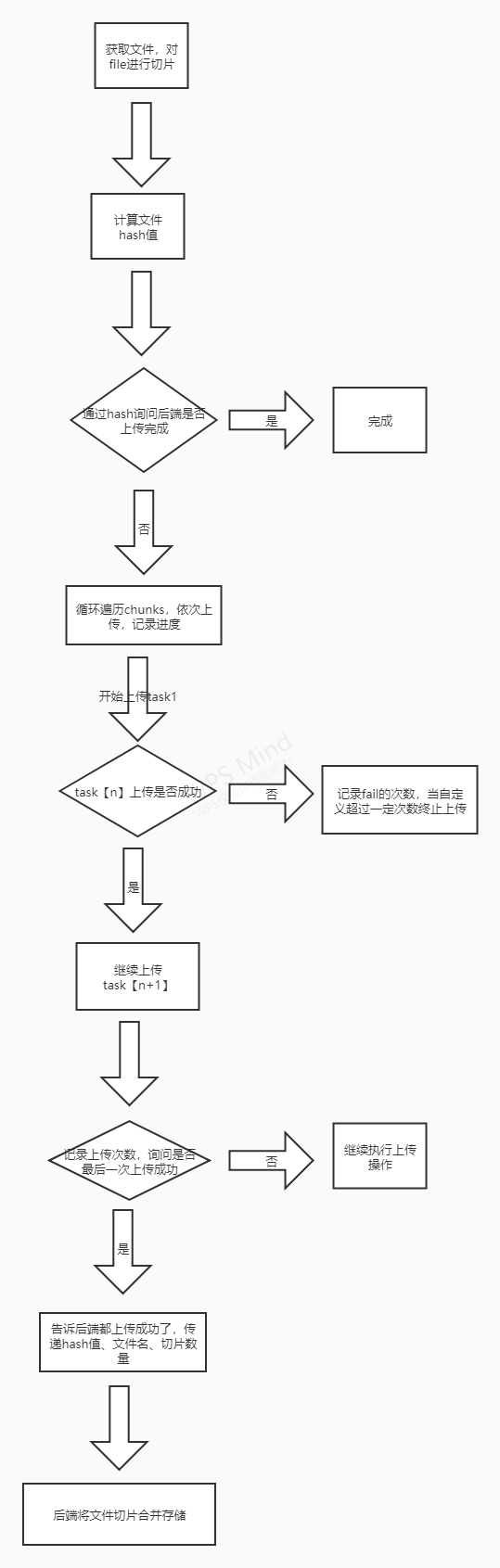
上面流程中,我们设置的文件并发数量为1,也就是每次只进行一个文件的上传。其实,当网速优越,我们是可以一次性上传多个文件的。比如我们设置并发数量limit=4。
那么,问题来了,我们如何控大量并发请求的并发数量?下面会讲到。
1、切片
下面先来看一下简单的实现逻辑,度娘上有很多切片的方法,blob.slice是比较好的。
// 定义每片大小为100kconst CHUNK_SIZE = 0.1 * 1024 * 1024// 按照定义大小进行切片function createFileChunk (file, size = CHUNK_SIZE) {// 生成文件块 Blob.slice语法const chunks = [];let cur = 0;while (cur < file.size) {chunks.push({ index: cur, file: file.slice(cur, cur + size) });cur += size;}return chunks;}
对文件切片后可以得到如下结构的数组:
我们得到了一个blob对象的数组,下一步最简单的做法,便利数组,将blob塞入formdata然后传给后端。但是这种做法是存在隐患的。因为我们无法知道文件是否上传完成,以及每次上传成功或者失败后该做些什么。而hash值就是用来判断文件是否上传完成的,除此之外,我们还需要在formdata放入标识来方便后端进行文件合并。
this.chunks = chunks.map((chunk, index) => {// 每一个切片的名字const chunkName = this.hash + '-' + indexreturn {hash: this.hash,chunk: chunk.file,name: chunkName,index,// 设置进度条progress: uploadedList.indexOf(chunkName) > -1 ? 100 : 0,}})
2、计算文件的hash值
web-worker
通过 Worker对象,配合spark-md5.js插件来实现
**
时间切片(fiber原理)
浏览器的每一帧都有空闲时间,流畅的网页60fps,1帧16.6ms<br /> |渲染绘制16.6ms|更新UI16.6ms|动画16.6ms|16.6ms|<br /> 同步任务,比如计算md5远大于16.6<br /> 我们可以利用空闲时间来计算,一旦有优先级更高的同步任务,返回浏览器控制权,等待下一次空闲
抽样hash
MD5的运算量是很大的,一般采用抽样hash。
算完hash值后,和后端交互,通过hash值作为唯一标识,来看文件是否已经上传完毕。
3、并发量控制

若有收获,就点个赞吧
0 人点赞
