Docker-ubuntu 构建系统
FROM ubuntuCOPY ./get-pip.py /tmp/get-pip.py#COPY /usr/share/zoneinfoAsia/Shanghai /etc/localtimeCOPY ./Shanghai /etc/localtimeRUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list \&& apt-get update \&& apt-get -y install software-properties-common \&& apt-get install --reinstall ca-certificates \&& add-apt-repository -y ppa:openjdk-r/ppa \&& add-apt-repository -y ppa:deadsnakes/ppa \&& apt-get -y install openjdk-8-jdk openssh-server vim python3.7 python3-pip python3.7-dev \&& rm -f /usr/bin/python \&& ln -s /usr/bin/python3.7 /usr/bin/python \&& python /tmp/get-pip.pyRUN mkdir /var/run/sshd \&& echo 'root:123456' |chpasswd \&& sed -ri 's/^PermitRootLogin\s+.*/PermitRootLogin yes/' /etc/ssh/sshd_config \&& sed -ri 's/UsePAM yes/#UsePAM yes/g' /etc/ssh/sshd_configENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64EXPOSE 22CMD ["/usr/sbin/sshd", "-D"]
Docker 构建spark + hive环境
FROM registry.cn-hangzhou.aliyuncs.com/pqchen/cpq_ubuntu:1.0COPY ./mysql-connector-java-5.1.45.tar.gz /tmp/mysql-connector-java-5.1.45.tar.gzCOPY ./apache-hive-2.3.7-bin.tar.gz /tmp/apache-hive-2.3.7-bin.tar.gzCOPY ./spark-2.4.7-bin-hadoop2.7.tgz /tmp/spark-2.4.7-bin-hadoop2.7.tgzCOPY ./hadoop-2.7.4.tar.gz /tmp/hadoop-2.7.4.tar.gzRUN mkdir /shared_data# -- install Hadoop#RUN wget -P /tmp https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gzRUN tar xf /tmp/hadoop-2.7.4.tar.gz -C /tmp \&& mv /tmp/hadoop-2.7.4 /opt/hadoop \&& rm /tmp/hadoop-2.7.4.tar.gzENV HADOOP_HOME /opt/hadoopENV HADOOP_COMMON_LIB_NATIVE_DIR $HADOOP_HOME/lib/nativeENV HADOOP_OPTS "-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64# -- install spark#RUN wget -P /tmp https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.7/spark-2.4.7-bin-hadoop2.7.tgzRUN tar xf /tmp/spark-2.4.7-bin-hadoop2.7.tgz -C /tmp \&& mv /tmp/spark-2.4.7-bin-hadoop2.7 /opt/spark \&& rm /tmp/spark-2.4.7-bin-hadoop2.7.tgz \&& echo 'export PATH=$PATH:$SPARK_HOME/bin' >> ~/.bashrcENV SPARK_HOME /opt/sparkENV LD_LIBRARY_PATH $HADOOP_HOME/lib/native/# -- install Hive#RUN wget -P /tmp http://apache.claz.org/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gzRUN tar xf /tmp/apache-hive-2.3.7-bin.tar.gz -C /tmp \&& mv /tmp/apache-hive-2.3.7-bin /opt/hive \&& echo 'export PATH=$PATH:$HIVE_HOME/bin' >> ~/.bashrc \&& rm /tmp/apache-hive-2.3.7-bin.tar.gzENV HIVE_HOME /opt/hive# -- install MySQL client jar for Hive#RUN wget -P /tmp https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.45.tar.gzRUN tar xf /tmp/mysql-connector-java-5.1.45.tar.gz -C /tmp \&& cp -r /tmp/mysql-connector-java-5.1.45/mysql-connector-java-5.1.45-bin.jar /opt/hive/lib \&& mv /tmp/mysql-connector-java-5.1.45/mysql-connector-java-5.1.45-bin.jar /opt/spark/jars \&& rm /tmp/mysql-connector-java-5.1.45.tar.gzEXPOSE 22CMD ["/usr/sbin/sshd", "-D"]
部署前要参考docker-compose.yml的挂载路径。其中用到一个hive-site.xml文件,将该文件放置相应位置即可。hive-site.xml文件内容如下。配置了mysql的ip、账号密码等,根据需要修改。
<configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://192.168.200.172:13306/hive_metastore?createDatabaseIfNotExist=true&useSSL=false</value><description>metadata is stored in a MySQL server</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>MySQL JDBC driver class</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>user name for connecting to mysql server</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password for connecting to mysql server</description></property><property><name>hive.metastore.warehouse.dir</name><value>/home/spark/env/container_data/warehouse</value><description>location of default database for the warehouse</description></property><property><name>hive.metastore.schema.verification</name><value>false</value></property></configuration>
部署可以直接使用docker-compose.yml
version: '2'services:mysql:image: mysql:5.7container_name: mysql_hiveenvironment:MYSQL_ROOT_PASSWORD: 123456MYSQL_DATABASE: hiveMYSQL_USER: hiveMYSQL_PASSWORD: hiveports:- 13306:3306volumes:- ./env/container_data/mysql:/var/lib/mysqlrestart: alwayspyspark:image: registry.cn-hangzhou.aliyuncs.com/pqchen/pyspark-hive:1.0container_name: pyspark-hiveports:- 14040:4040- 18080-18090:8080-8090- 10000:10000volumes:- ./env/conf:/opt/spark/conf- ./env/container_data/spark/warehouse:/shared_data/hive/warehouse- ./env/table_data:/shared_data/table_data- ./env/conf/hive-site.xml:/opt/hive/conf/hive-site.xml- ./:/home/userprofilelinks:- "mysql:mysql"stdin_open: truetty: trueworking_dir: /home/userprofilesecurity_opt:- seccomp=unconfinedcap_add:- SYS_PTRACE
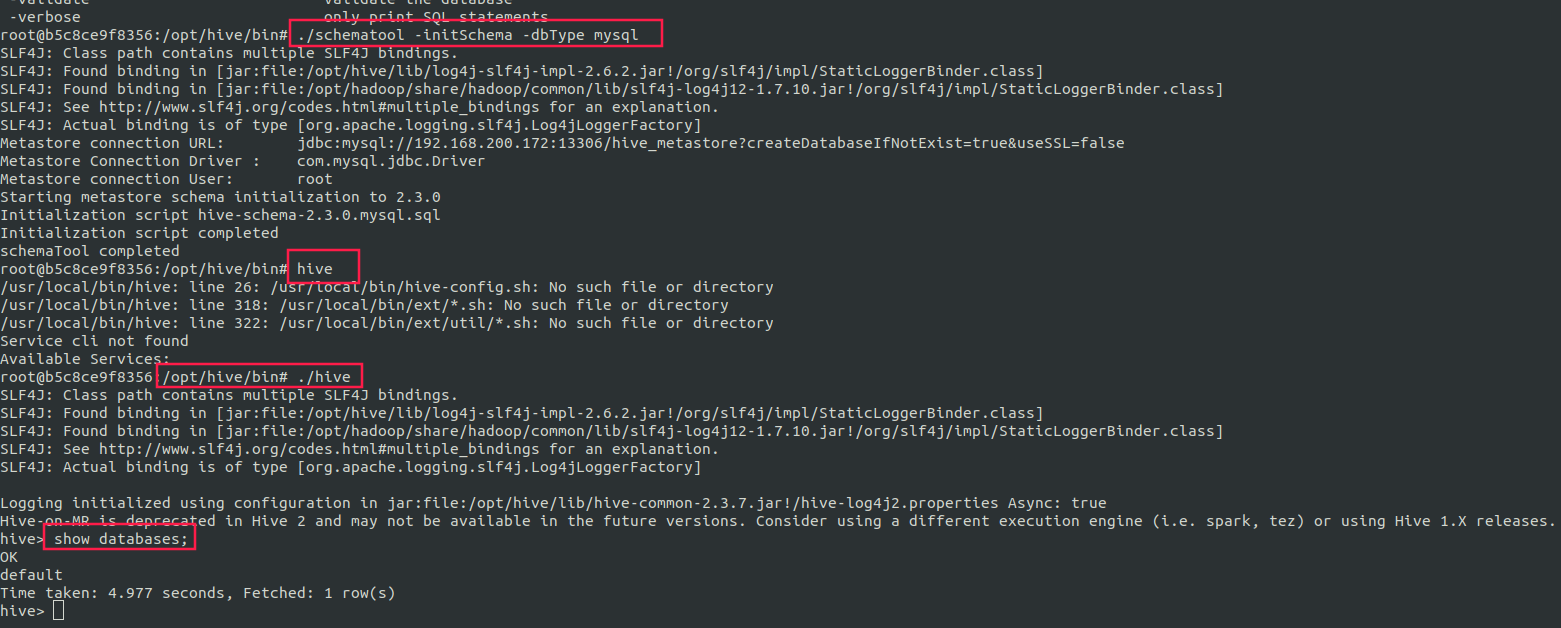
hive 初始化
# metastore 初始化./schematool -initSchema -dbType mysql# hive启动 注:不要直接使用hive启动/opt/hive/bin/hive# 测试启动成功,没有报错且返回数据库名即可。show databases;
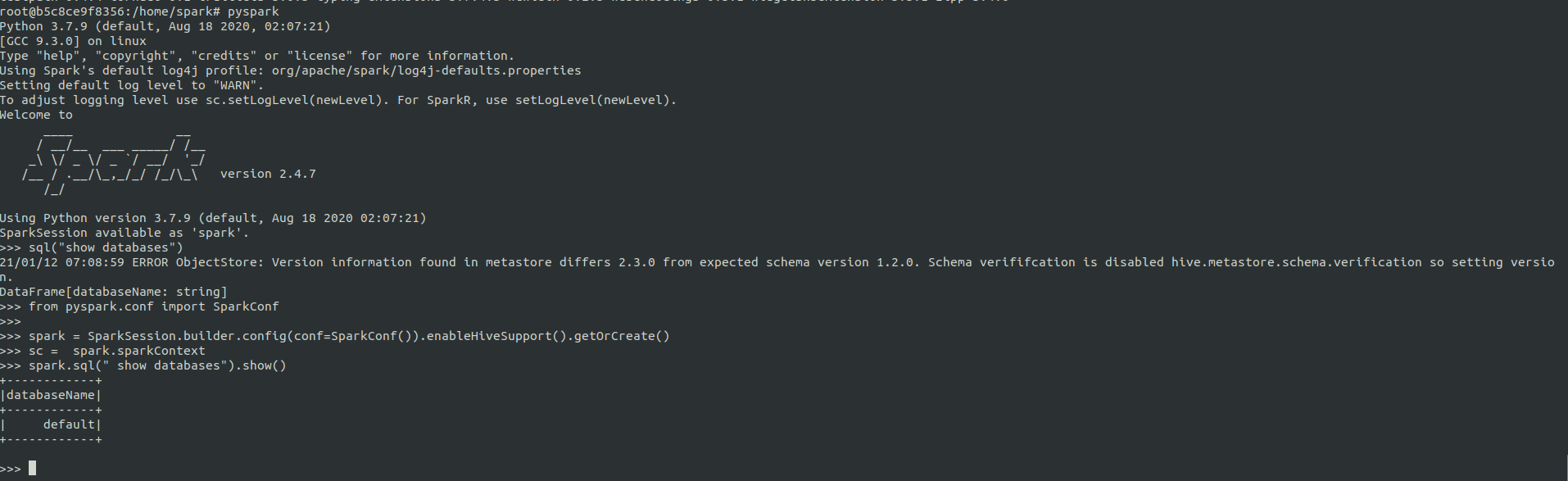
测试spark 访问hive表
from pyspark.conf import SparkConfspark = SparkSession.builder.config(conf=SparkConf()).enableHiveSupport().getOrCreate()sc = spark.sparkContextspark.sql(" show databases").show()

若有收获,就点个赞吧
0 人点赞
