一、local本地模式
原理:
1、Flink程序由JobClient进行提交
2、JobClient将作业提交给JobManager
3、JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager
4、TaskManager启动一个线程以开始执行,TaskManager会向JobManager报告状态更改,如开始执行、正在执行或已完成
5、作业执行完成后,结果将发送回客户端(JobClient)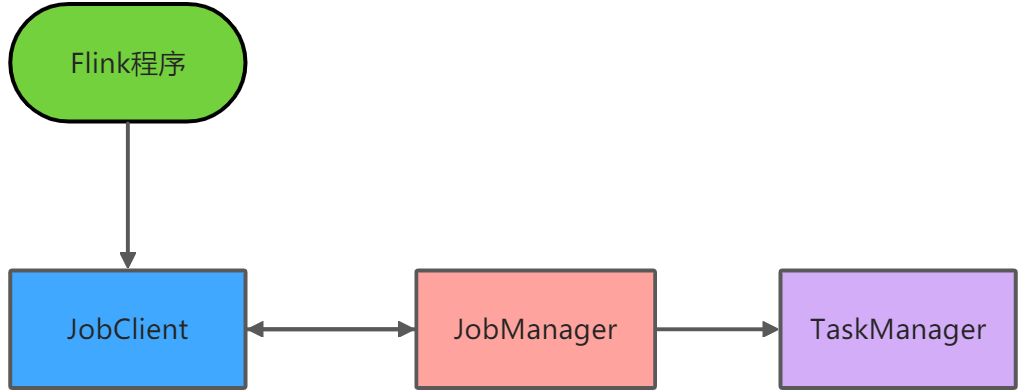
执行命令:
1、启动:./bin/start-cluster.sh
2、可以看到两个进程TaskManager、StandaloneSessionClusterEntrypoint
3、可以在webui看到flink集群管理界面,默认8081端口
5、停止:./bin.stop-cluster.sh
二、Standalone独立集群模式
原理:
1、client客户端提交任务给JobManager
2、JobManager负责申请任务运行所需的资源并管理任务和资源
3、JobManager分发任务给TaskManager执行
4、TaskManager定期向JobManager汇报状态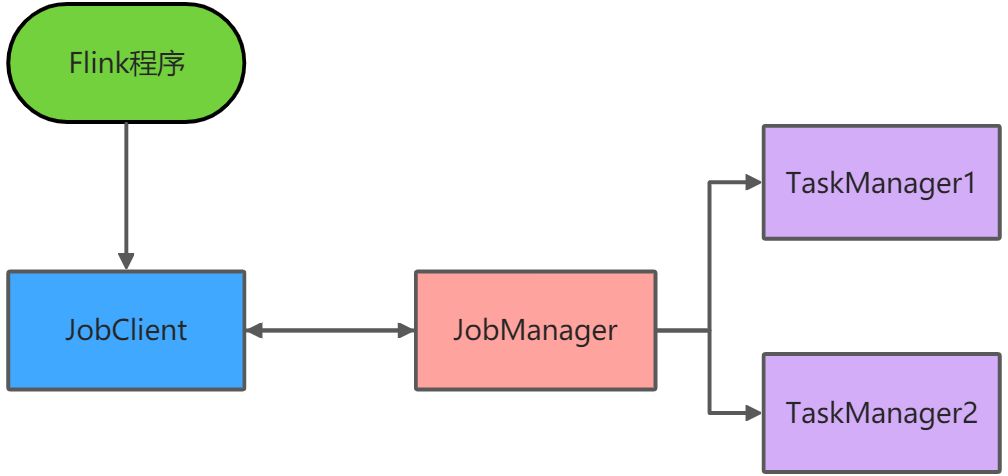
集群规划:
-服务器:node1(Master+Slave):JobManager+TaskManager
-服务器:node2(Slave):TaskManager
-服务器:node3(Slave):TaskManager
修改配置:
./conf/flink-conf.yaml
jobmanager.rpc.address: node1taskmanager.numberOfTaskSlots: 2 --taskmanager的slot数量(加起来就是可用slot数量)web.submit.enable: true --允许在webui提交任务#历史服务器jobmanager.archive.fs.dir: hdfs://node1:8020/flink/completed-jobs/historyserver.web.address: node1historyserver.web.port: 8082 --历史服务器webui端口historyserver.archive.fs.dir: hdfs://node1:8020/flink/completed-jobs/
./conf/masters
node1:8081 --webui的通信端口
./conf/workers或者./conf/slaves
node1node2node3
添加hadoop环境变量:
vim /etc/profileexport HADOOP_CONF_DIR=../hadoopsource /etc/profile
执行命令:
1、启动:./bin/start-cluster.sh
2、启动历史服务器:./bin/historyserver.sh start
3、停止:./bin.stop-cluster.sh
三、Standalone-HA高可用集群模式
原理:
jobManager协调每个flink任务部署。它负责调度和资源管理。
默认情况下,每个flink集群只有一个JobManager,这将导致一个单点故障(SPOF):如果JobManager挂了,则不能提交新的任务,并且运行中的程序也会失败。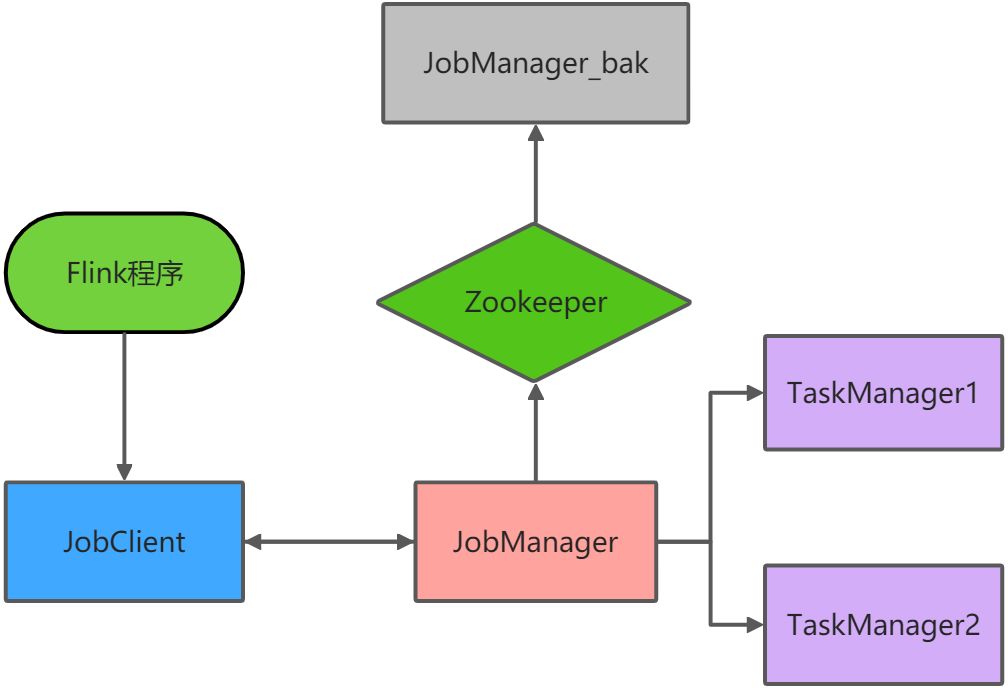
集群规划:
-服务器:node1(Master+Slave):JobManager+TaskManager
-服务器:node2(Master_bak+Slave):JobManager_bak+TaskManager
-服务器:node3(Slave):TaskManager
操作:
需要启动zk和hdfs
./zkServer.sh start
./hadoop/sbin/start-dfs.sh
修改配置:
增加如下./conf/flink-conf.yaml
state.backend: filesystemstate.backend.fs.checkpointdir: hdfs://node1:8020/flink-checkpointshigh-availability: zookeeperhigh-availability.storageDir: hdfs://node1:8020/flink/ha --JobManager的元数据保存在文件系统存储目录high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181 --zk的地址high-availability.zookeeper.path.root: /flink --ZooKeeper节点根目录,其下放置所有集群节点的namespace
./conf/masters
node1:8081 --webui的通信端口node1:8082
四、Flink-On-Yarn模式
原理: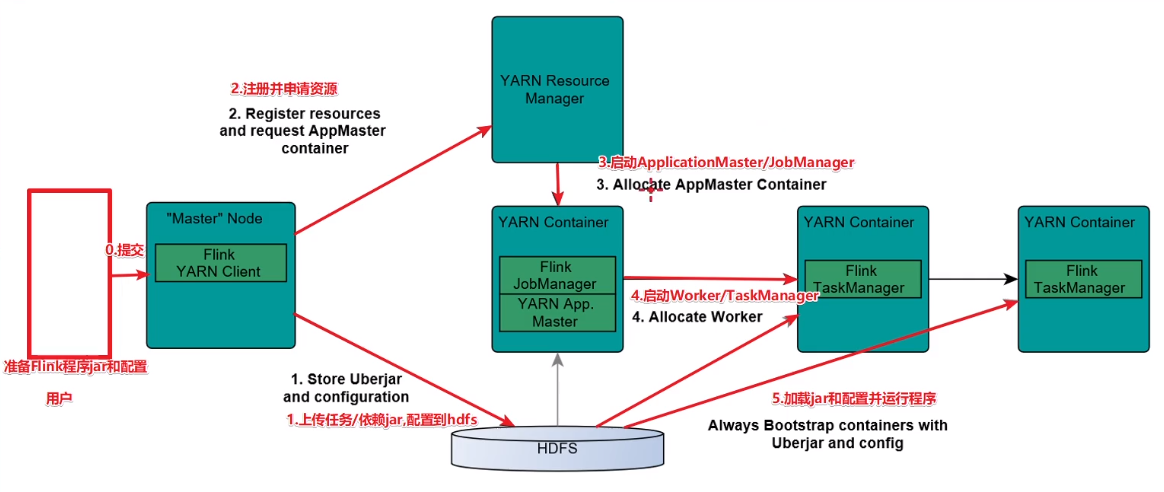
两种模式:
1、Session模式:在yarn集群中启动一个Flink集群,并重复使用它
(Start a long-running Flink cluster on YARN)这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交。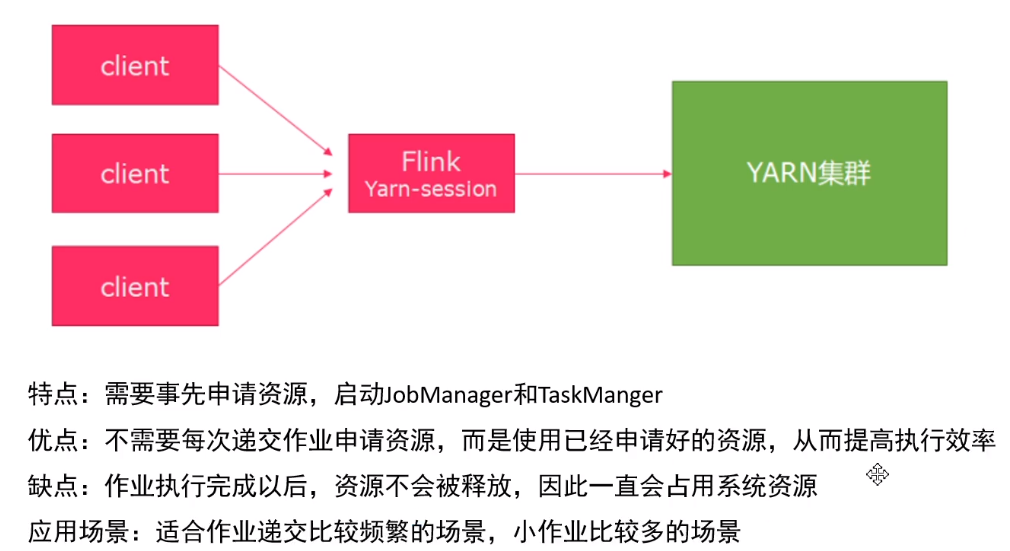
2、Pre-Job模式:针对每个Flink任务都去启动一个独立的Flink集群
直接在YARN上提交运行Flink作业(Run a Flink job on YARN),这种方式的好处是一个任务会对应一个job,即没提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。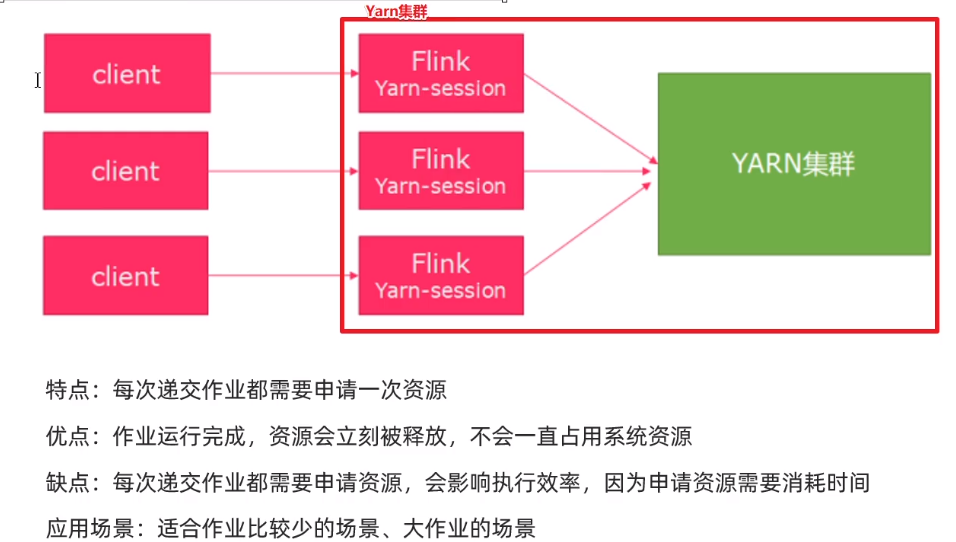
注意事项:如果是平时的本地测试或者开发,可以采用第一种方案;如果是生产环境推荐使用第二种方案。
操作:
启动yarn:./hadoop/sbin/start-yarn.sh
session模式:./bin/yarn-session.sh
默认参数为:{masterMemoryMB=1024, taskManagerMemoryMB=1024,numberTaskManagers=1, slotsPerTaskManager=1}yarn-session的参数介绍-n : 指定TaskManager的数量;-d: 以分离模式运行;-id:指定yarn的任务ID;-j:Flink jar文件的路径;-jm:JobManager容器的内存(默认值:MB);-nl:为YARN应用程序指定YARN节点标签;-nm:在YARN上为应用程序设置自定义名称;-q:显示可用的YARN资源(内存,内核);-qu:指定YARN队列;-s:指定TaskManager中slot的数量;-st:以流模式启动Flink;-tm:每个TaskManager容器的内存(默认值:MB);-z:命名空间,用于为高可用性模式创建Zookeeper子路径;例子:启动一个yarn-session有2个Taskmanager,jobmanager内存2GB,taskManager2GB内存,那么脚本编写应该是这样的./bin/yarn-session.sh -n 2 -jm 1024 -tm 1024客户端模式而言,你可以启动多个yarn session,一个yarn session模式对应一个JobManager,并按照需求提交作业,同一个Session中可以提交多个Flink作业提交job:./bin/flink run -c com.flink.StreamWordCount /home/Flink-Demo-1.0-SNAPSHOT.jar指定提交到哪个yarn-session(使用yid参数指定):./flink run -yid application_1598346048136_0002 -c com.flink.StreamWordCount /home/Flink-Demo-1.0-SNAPSHOT.jar如果想要停止Flink Yarn Application,需要通过yarn application -kill命令来停止yarn application -kill application_1550836652097_0002
pre-job模式:
./bin/flink run -m yarn-cluster -yn 1 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar参数说明:-c:如果没有在jar包中指定入口类,则需要在这里通过这个参数指定;-m:指定需要连接的jobmanager(主节点)地址,使用这个参数可以指定一个不同于配置文件中的jobmanager,可以说是yarn集群名称;-p:指定程序的并行度。可以覆盖配置文件中的默认值;-n:允许跳过保存点状态无法恢复。 你需要允许如果您从中删除了一个运算符你的程序是的一部分保存点时的程序触发;-q:如果存在,则禁止将日志记录输出标准出来;-s:保存点的路径以还原作业来自(例如hdfs:///flink/savepoint-1537);还有参数如果在yarn-session当中没有指定,可以在yarn-session参数的基础上前面加“y”,即可控制所有的资源,这里就不獒述了。-m: 指定jobmanager的地址-yjm:指定jobmanager的内存信息-ytm:指定taskmanager的内存信息

若有收获,就点个赞吧
0 人点赞
