Flink是一个默认就有状态的分析引擎,前面的WordCount案例可以做到单词的数量的累加,其实是因为在内存中保证了每个单词的出现的次数,这些数据其实就是状态数据。但是如果一个Task在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义(At -least-once和Exactly-once)上来说,Flink引入了State和CheckPoint。
- State一般指一个具体的Task/Operator的状态,State数据默认保存在Java的堆内存中。
- CheckPoint(可以理解为CheckPoint是把State数据持久化存储了)则表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有Task/Operator的状态。
一、常用State
Flink有两种常见的State类型,分别是:
- keyed State(键控状态)
- Operator State(算子状态)
1.1、Keyed State(键控状态)
Keyed State:顾名思义就是基于KeyedStream上的状态,这个状态是跟特定的Key绑定的。KeyedStream流上的每一个Key,都对应一个State。Flink针对Keyed State提供了以下可以保存State的数据结构:
ValueState: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过 update(T) 进行更新,通过 T value() 进行获取值。
ListState: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T) 或者 addAll(List ) 进行添加元素,通过 Iterable get() 获得整个列表。还可以通过 update(List ) 覆盖当前的列表。
ReducingState: 保存一个单值,表示添加到状态的所有值的聚合。接口与 ListState 类似,但使用 add(T) 增加元素,会使用提供的 ReduceFunction 进行聚合。
AggregatingState
FoldingState
MapState) 添加映射。 使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映² 射、键和值的可迭代视图。 1.2、Operator State(算子状态)
Operator State与Key无关,而是与Operator绑定,整个Operator只对应一个State。比如:Flink中的Kafka Connector就使用了Operator State,它会在每个Connector实例中,保存该实例消费Topic的所有(partition, offset)映射。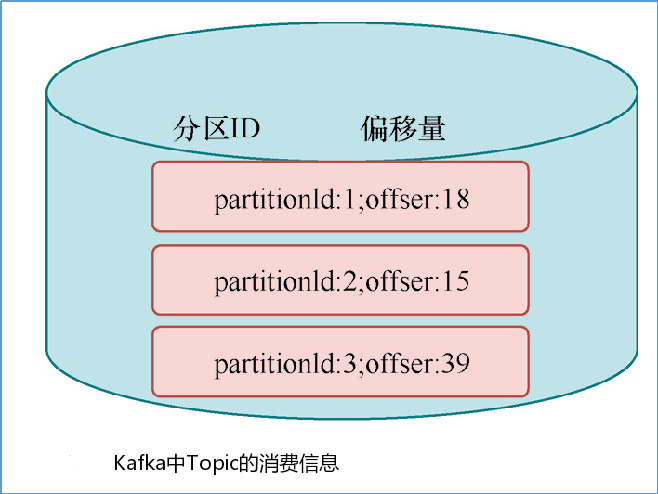
二、Keyed State样例代码
2.1、ValueState
/*** 统计每个手机的呼叫间隔时间,并输出*/object StateExampleWithMap {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.streaming.api.scala._val infos: DataStream[String] = env.socketTextStream("mynode5",9999)val keyStream: KeyedStream[StationLog, String] = infos.map(line => {val arr = line.split(",")StationLog(arr(0), arr(1), arr(2), arr(3), arr(4).toLong, arr(5).toLong)}).keyBy(_.callOut)/*** IN :Type of the input elements.* OUT :Type of the returned elements.*/val result: DataStream[String] = keyStream.map(new RichMapFunction[StationLog, String] {//从上下文环境中获取一个状态来保存对应的主叫呼出时间private lazy val ts: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("timeState", classOf[Long]))override def map(value: StationLog): String = {val phoneNum = value.callOutval preCallOutTime = ts.value()val currentCallOutTime = value.callTimets.update(currentCallOutTime)s"主叫号码:$phoneNum,上次主叫时间:$preCallOutTime,本次主叫时间:$currentCallOutTime,两次间隔:${currentCallOutTime - preCallOutTime}ms"}})result.print()env.execute()}}
2.2、ListState
/*** 通过process算子实现 ,状态使用ListState** 案例需求:统计每个主机号码在20内所有的通话间隔时长*/object StateExampleWithProcess {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentimport org.apache.flink.streaming.api.scala._val infos: DataStream[String] = env.socketTextStream("mynode5",9999)val keyStream: KeyedStream[StationLog, String] = infos.map(line => {val arr = line.split(",")StationLog(arr(0), arr(1), arr(2), arr(3), arr(4).toLong, arr(5).toLong)}).keyBy(_.callOut)/*** K : Type of the key.* I : Type of the input elements.* O : Type of the output elements.*/val result :DataStream[String] = keyStream.process(new KeyedProcessFunction[String, StationLog, String] {//首先获取一个ListState 来存放20s 内每个主叫号码呼叫时间private lazy val listState: ListState[Long] = getRuntimeContext.getListState(new ListStateDescriptor[Long]("listState", classOf[Long]))override def processElement(value: StationLog, ctx: KeyedProcessFunction[String, StationLog, String]#Context, out: Collector[String]): Unit = {//获取当前主叫号码的存储的状态值val stateValueList = IteratorUtils.toList(listState.get().iterator())val currentProcessTime: Long = ctx.timerService().currentProcessingTime() //获取当前数据处理时间if (stateValueList.size() == 0) {//状态中没有数据,第一次呼叫listState.add(currentProcessTime) //向状态中加入当前处理时间ctx.timerService().registerProcessingTimeTimer(currentProcessTime + 20 * 1000) //设置定时器}if (stateValueList.size() != 0) {listState.add(currentProcessTime) //向状态中加入当前处理时间}}//定时器触发时执行onTimeroverride def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, StationLog, String]#OnTimerContext, out: Collector[String]): Unit = {val phoneNum = ctx.getCurrentKey//循环找出状态中的两次间隔,并放入字符串中val builder = new StringBuilder()var preTime = 0Lval iterator: util.Iterator[Long] = listState.get().iterator()while(iterator.hasNext){val elem = iterator.next()if (preTime != 0) {builder.append(s"【pthoneNum = $phoneNum,perTime = ${preTime},currentTime = ${elem},间隔:${elem - preTime}ms】->")}preTime = elem}//将状态重置listState.clear()out.collect(builder.toString().substring(0, builder.toString().length - 2))}})result.print()env.execute()}}
三、CheckPoint
当程序出现问题需要恢复Sate数据的时候,只有程序提供支持才可以实现State的容错。State的容错需要依靠CheckPoint机制,这样才可以保证Exactly-once这种语义,但是注意,它只能保证Flink系统内的Exactly-once,比如Flink内置支持的算子。针对Source和Sink组件,如果想要保证Exactly-once的话,则这些组件本身应支持这种语义。
3.1、CheckPoint原理
Flink中基于异步轻量级的分布式快照技术提供了Checkpoints容错机制,分布式快照可以将同一时间点Task/Operator的状态数据全局统一快照处理,包括前面提到的Keyed State和Operator State。Flink会在输入的数据集上间隔性地生成checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数据划分到相应的checkpoint中。如下图: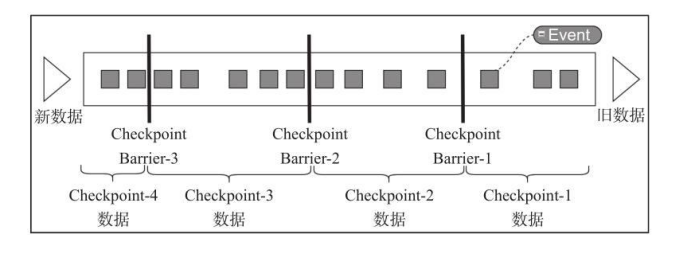
checkpoint barrier会随着数据往后流动,每个算子处理到当前的checkpoint barrier会向JobManager汇报,当所有的算子都处理完成同一个checkpoint barrier时,那这个jobmanager将触发checkpoint,将算子状态持久化到状态后端。flink默认只会保存最后一次checkpoint。
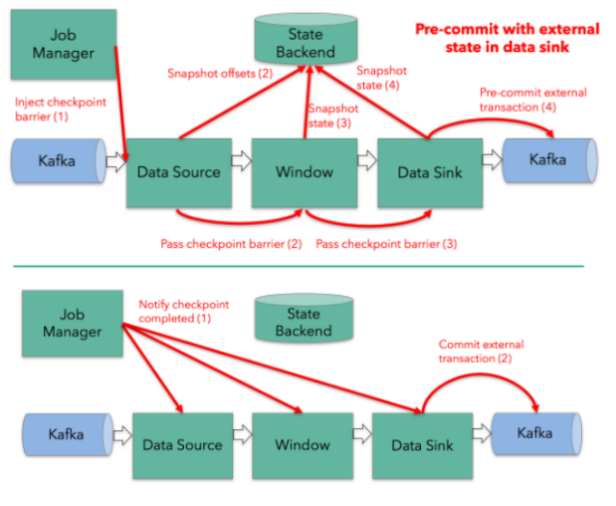
从检查点(CheckPoint)恢复如下图: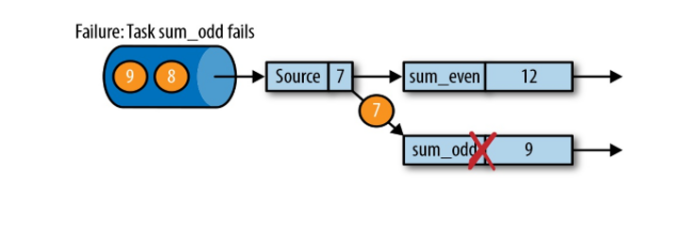
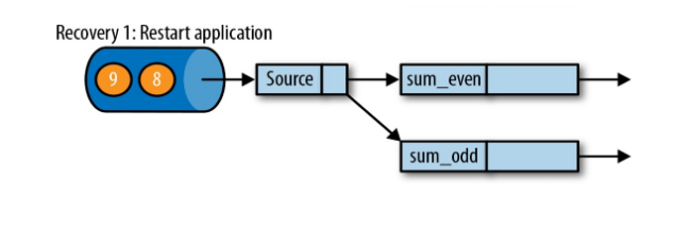
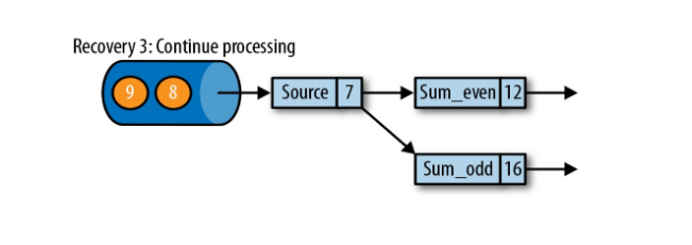
Flink程序挂了重启之后,会寻找保存的checkpoint,从最后一次完整保存的checkpoint恢复(key的状态、数据读取的位置)。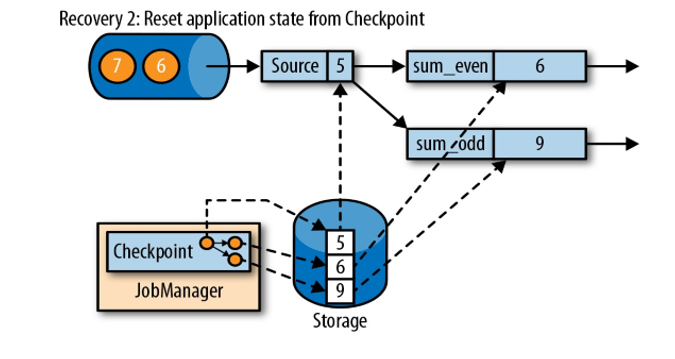
3.2、CheckPoint参数和设置
默认情况下Flink不开启检查点的,用户需要在程序中通过调用方法配置和开启检查点,另外还可以调整其他相关参数:
- Checkpoint开启和时间间隔指定:开启检查点并且指定检查点时间间隔为1000ms,根据实际情况自行选择,如果状态比较大,则建议适当增加该值。streamEnv.enableCheckpointing(1000);
- exactly-once和at-least-once语义选择:
选择exactly-once语义保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复,与此同时,Flink的性能也相对较弱,而at-least-once语义更适合于时廷和吞吐量要求非常高但对数据的一致性要求不高的场景。
如果在Flink内部exactly-once语义涉及到barrier对齐,如果at-least-once语义就是barrier不对齐,只有Flink内部多个流(多个并行度时)才会涉及到barrier对齐问题。
如下通过setCheckpointingMode()方法来设定语义模式,默认情况下使用的是exactly-once模式。
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//或者
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
- Checkpoint超时时间:超时时间指定了每次Checkpoint执行过程中的上限时间范围,一旦Checkpoint执行时间超过该阈值,Flink将会中断Checkpoint过程,并按照超时处理。该指标可以通过setCheckpointTimeout方法设定,默认为10分钟。
streamEnv.getCheckpointConfig.setCheckpointTimeout(50000)
- 检查点之间最小时间间隔:该参数主要目的是设定两个Checkpoint之间的最小时间间隔,防止出现例如状态数据过大而导致Checkpoint执行时间过长,从而导致Checkpoint积压过多,最终Flink应用密集地触发Checkpoint操作,会占用了大量计算资源而影响到整个应用的性能。
streamEnv.getCheckpointConfig.setMinPauseBetweenCheckpoints(600)
- 最大并行执行的检查点数量:通过setMaxConcurrentCheckpoints()方法设定能够最大同时执行的 Checkpoint数量。在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个Checkpoint,进而提升Checkpoint整体的效率。
streamEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
- 是否删除Checkpoint中保存的数据:设置为RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留CheckPoint数据,以便根据实际需要恢复到指定的CheckPoint。设置为DELETE_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会删除CheckPoint数据,只有Job执行失败的时候才会保存CheckPoint。(默认)
//删除 streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION)
//保留 streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
- TolerableCheckpointFailureNumber:checkpoint在执行过程中如果出现失败设置可以容忍的检查的失败数,超过这个数量则系统自动关闭和停止任务。
streamEnv.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
四、保存机制StateBackend(状态后端)
默认情况下,State会保存在TaskManager的内存中,CheckPoint会存储在JobManager的内存中。State和CheckPoint的存储位置取决于StateBackend的配置。Flink一共提供了3种StateBackend。包括基于:
- 内存的MemoryStateBackend
- 基于文件系统的FsStateBackend
- 基于RockDB作为存储介质的RocksDBState-Backend
4.1、MemoryStateBackend
基于内存的状态管理具有非常快速和高效的特点,但也具有非常多的限制,最主要的就是内存的容量限制,一旦存储的状态数据过多就会导致系统内存溢出等问题,从而影响整个应用的正常运行。同时如果机器出现问题,整个主机内存中的状态数据都会丢失,进而无法恢复任务中的状态数据。因此从数据安全的角度建议用户尽可能地避免在生产环境中使用MemoryStateBackend。
streamEnv.setStateBackend(new MemoryStateBackend(1010241024))
4.2、FsStateBackend
和MemoryStateBackend有所不同,FsStateBackend是基于文件系统的一种状态管理器,这里的文件系统可以是本地文件系统,也可以是HDFS分布式文件系统。FsStateBackend更适合任务状态非常大的情况,例如应用中含有时间范围非常长的窗口计算,或Key/value State状态数据量非常大的场景。
streamEnv.setStateBackend(new FsStateBackend(“hdfs://hadoop101:9000/checkpoint/cp1”))
4.3、RocksDBStateBackend
RocksDBStateBackend是Flink中内置的第三方状态管理器,和前面的状态管理器不同,RocksDBStateBackend需要单独引入相关的依赖包到工程中。
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_2.11</artifactId><version>1.9.1</version></dependency>
RocksDBStateBackend采用异步的方式进行状态数据的Snapshot,任务中的状态数据首先被写入本地RockDB中(RockDB是一个高效、高性能的数据库引擎,可以直接使用内存、也可以使用硬盘或者HDFS,支持不同的压缩算法),这样在RockDB仅会存储正在进行计算的热数据,而需要进行CheckPoint的时候,会把本地的数据直接复制到远端的FileSystem中。
与FsStateBackend相比,RocksDBStateBackend在性能上要比FsStateBackend高一些,主要是因为借助于RocksDB在本地存储了最新热数据,然后通过异步的方式再同步到文件系统中,但RocksDBStateBackend和MemoryStateBackend相比性能就会较弱一些。RocksDB克服了State受内存限制的缺点,同时又能够持久化到远端文件系统中,推荐在生产中使用。
4.4、全局配置StateBackend
以上的代码都是单job配置状态后端,也可以全局配置状态后端,需要修改flink-conf.yaml配置文件:state.backend: filesystem
其中:
- filesystem表示使用FsStateBackend,
- jobmanager表示使用MemoryStateBackend
- rocksdb表示使用RocksDBStateBackend。
checkpoint路径:state.checkpoints.dir: hdfs://hadoop101:9000/checkpoints
默认情况下,如果设置了CheckPoint选项,则Flink只保留最近成功生成的1个CheckPoint,而当Flink程序失败时,可以通过最近的CheckPoint来进行恢复。但是,如果希望保留多个CheckPoint,并能够根据实际需要选择其中一个进行恢复,就会更加灵活。添加如下配置,指定最多可以保存的CheckPoint的个数。
state.checkpoints.num-retained: 2
五、案例
当job失败后,通过命令启动Job:
注意:使用 -s 来指定checkpoint目录,需要指定到chk-xxx 目录。
[root@hadoop101 bin]# ./flink run -d -s hdfs://hadoop101:9000/checkpoint/cp1/b38e35788eecf3053d4a87d52e97d22d/chk-272 -c com.bjsxt.flink.state.CheckpointOnFsBackend /home/Flink-Demo-1.0-SNAPSHOT.jar
六、SavePoint
Savepoints 是检查点的一种特殊实现,底层实现其实也是使用Checkpoints的机制。Savepoints是用户以手工命令的方式触发Checkpoint,并将结果持久化到指定的存储路径中,其主要目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实现从端到端的 Excatly-Once 语义保证。
6.1、配置Savepoints的存储路径
在flink-conf.yaml中配置SavePoint存储的位置,设置后,如果要创建指定Job的SavePoint,可以不用在手动执行命令时指定SavePoint的位置。
state.savepoints.dir: hdfs:/hadoop101:9000/savepoints
6.2、在代码中设置算子ID
为了能够在作业的不同版本之间以及Flink的不同版本之间顺利升级,强烈推荐程序员通过手动给算子赋予ID,这些ID将用于确定每一个算子的状态范围。如果不手动给各算子指定ID,则会由Flink自动给每个算子生成一个ID。而这些自动生成的ID依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动设置ID。
//读取数据得到DataStreamval stream: DataStream[String] = streamEnv.socketTextStream("hadoop101",8888).uid("mySource-001")stream.flatMap(_.split(" ")).uid("flatMap-001").map((_,1)).uid("map-001").keyBy(0).sum(1).uid("sum-001").print()
6.3、触发savepoint
//先启动Job[root@hadoop101 bin]# ./flink run -c com.bjsxt.flink.state.TestSavepoints -d /home/Flink-Demo-1.0-SNAPSHOT.jar//触发SavePoint,会返回一个savepoint的路径[root@hadoop101 bin]# ./flink savepoint 6ecb8cfda5a5200016ca6b01260b94ce//再取消Job[root@hadoop101 bin]# ./flink cancel 6ecb8cfda5a5200016ca6b01260b94ce重启格式:./flink savepoint flink-job-id savepointpath -yid application_xxx_0001例如:./flink savepoint cd4192b02d9ce3127b0256525ec83b67 hdfs://mycluster/sv -yid application_1598581537108_0004注意:如果savepointpath在当前提交任务节点的flink-conf.yaml中配置了,就不需要再写上。从SavePoint启动Job./flink run -s hdfs://hadoop101:9000/savepoints/savepoint-6ecb8c-e56ccb88576a -c 类名 -d jar包路径
也可以通过Web UI启动Job: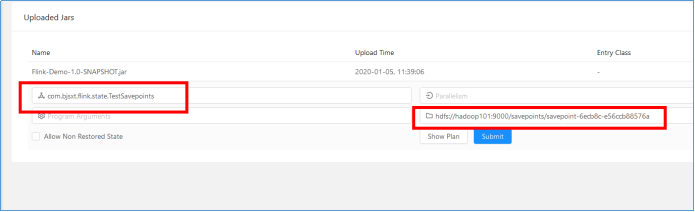

若有收获,就点个赞吧
0 人点赞
