一、基本概念
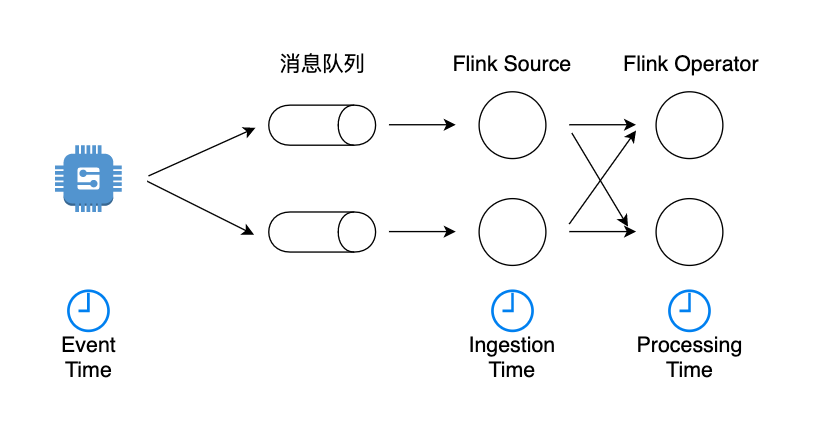
- Event Time:事件创建事件
Event Time指的是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间。由于事件从发生到进入Flink时间算子之间有很多环节,一个较早发生的事件因为延迟可能较晚到达,因此使用Event Time意味着事件到达有可能是乱序的。
使用Event Time时,最理想的情况下,我们可以一直等待所有的事件到达后再进行时间窗口的处理。假设一个时间窗口内的所有数据都已经到达,基于Event Time的流处理会得到正确且一致的结果:无论我们是将同一个程序部署在不同的计算环境还是在相同的环境下多次计算同一份数据,都能够得到同样的计算结果。我们根本不同担心乱序到达的问题。但这只是理想情况,现实中无法实现,因为我们既不知道究竟要等多长时间才能确认所有事件都已经到达,更不可能无限地一直等待下去。在实际应用中,当涉及到对事件按照时间窗口进行统计时,Flink会将窗口内的事件缓存下来,直到接收到一个Watermark,以确认不会有更晚数据的到达。Watermark意味着在一个时间窗口下,Flink会等待一个有限的时间,这在一定程度上降低了计算结果的绝对准确性,而且增加了系统的延迟。在流处理领域,比起其他几种时间语义,使用Event Time的好处是某个事件的时间是确定的,这样能够保证计算结果在一定程度上的可预测性。
一个基于Event Time的Flink程序中必须定义Event Time,以及如何生成Watermark。我们可以使用元素中自带的时间,也可以在元素到达Flink后人为给Event Time赋值。
使用Event Time的优势是结果的可预测性,缺点是缓存较大,增加了延迟,且调试和定位问题更复杂。
- Ingestion Time:涉入时间,数据进入Flink的时间
Ingestion Time是事件到达Flink Souce的时间。从Source到下游各个算子中间可能有很多计算环节,任何一个算子的处理速度快慢可能影响到下游算子的Processing Time。而Ingestion Time定义的是数据流最早进入Flink的时间,因此不会被算子处理速度影响。
Ingestion Time通常是Event Time和Processing Time之间的一个折中方案。比起Event Time,Ingestion Time可以不需要设置复杂的Watermark,因此也不需要太多缓存,延迟较低。比起Processing Time,Ingestion Time的时间是Souce赋值的,一个事件在整个处理过程从头至尾都使用这个时间,而且后续算子不受前序算子处理速度的影响,计算结果相对准确一些,但计算成本稍高。
- Processing Time:默认的,处理时间,执行操作算子的本地系统时间,与机器相关
对于某个算子来说,Processing Time指算子使用当前机器的系统时钟来定义时间。在Processing Time的时间窗口场景下,无论事件什么时候发生,只要该事件在某个时间段达到了某个算子,就会被归结到该窗口下,不需要Watermark机制。对于一个程序在同一个计算环境来说,每个算子都有一定的耗时,同一个事件的Processing Time,第n个算子和第n+1个算子不同。如果一个程序在不同的集群和环境下执行时,限于软硬件因素,不同环境下前序算子处理速度不同,对于下游算子来说,事件的Processing Time也会不同,不同环境下时间窗口的计算结果会发生变化。因此,Processing Time在时间窗口下的计算会有不确定性。
Processing Time只依赖当前执行机器的系统时钟,不需要依赖Watermark,无需缓存。Processing Time是实现起来非常简单也是延迟最小的一种时间语义。
二、不同的应用场景
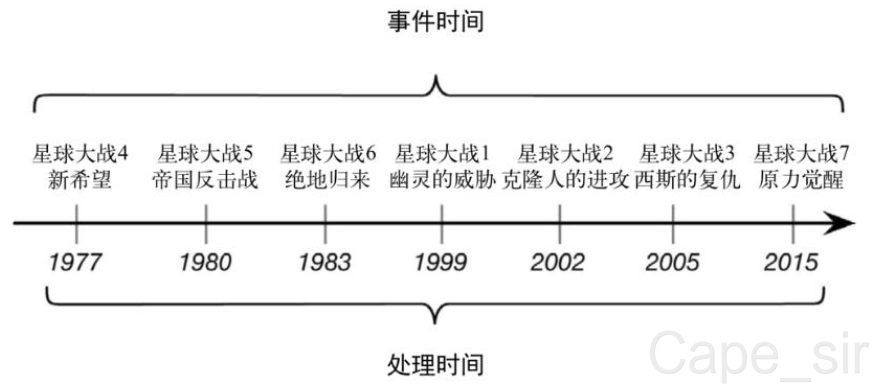
- 不同的时间语义有不同的应用场合,如对故事情节关注应该注重事件时间,如对电影票房影响应该关注处理时间。
- 往往更关心事件时间(Event Time)
三、API使用
package windowimport datasource.SensorReadingimport org.apache.flink.streaming.api.TimeCharacteristicimport org.apache.flink.streaming.api.windowing.time.Timeimport org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractorimport org.apache.flink.streaming.api.scala._object WaterMarkDemo {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironment//从调用时刻开始给env创建一个stream追加一个时间特性,但是在后续数据源还需指定哪个字段为EventTimeenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)// env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)env.getConfig.setAutoWatermarkInterval(500) //设置watermark的延迟时间/*** Flink是时间驱动的,但是在分布式系统中,数据生成时间和数据处理时间会出现乱序,所以Flink定义了如下三个时间对此进行区分。** Event Time:时间创建时间* Ingestion Time:数据进入Flink的时间* Processing Time:执行操作算子的本地系统时间,与机器有关** 对于不同的场景需要使用到不同的是按语义。*//*** watermark:衡量Event Time进展的机制,可以设定延迟触发** 用于表示timeStamo小于watermark的数据都已经到达了** watermark特定是单调递增*//*** 一般的转换算子并不可以访问事件的时间和水位线信息的,* 所以Flink提供了一系列Low-Level转换算子,可以访问时间、watermark以及注册定时事件,还可以输出一些事件,如超时事件等。** 即Process Function:(Flink提供了8个Process Function)* 1、ProcessFunction* 2、KeyedProcessFunction* 3、CoProcessFunction* 4、ProcessJoinFunction* 5、BroadcastProcessFunction* 6、KeyedBroadcastProcessFunction* 7、ProcessWindowFunction* 8、ProcessAllWindowFunction*/val inputStream: DataStream[String] = env.socketTextStream("127.0.0.1",7777)val dataStream = inputStream.map(data=>{var arr = data.split(",")SensorReading(arr(0),arr(1).trim.toLong,arr(2).trim.toDouble)})// .assignAscendingTimestamps(_.timestamp * 1000L) //此api表示来源数据是已经按照升序排好了的数据,就不需要另外设置watermark.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.minutes(1)) { //Time.minutes(1)设置延迟一分钟override def extractTimestamp(element: SensorReading): Long = element.timestamp //指定以哪个属性作为时间语义}) //用于处理乱序的数据,分为周期性watermark(AssignerWithPeriodicWatermarks) 和 间断式的watermark(AssignerWithPunctuatedWatermarks).keyBy(_.id).timeWindow(Time.seconds(15)).reduce((curData,nowData)=>{SensorReading(curData.id, curData.timestamp.max(nowData.timestamp) , nowData.temperature.min(curData.temperature))}) //必须在设置水位线后才能进行keyBy操作}}
四、乱序的数据
由于网络、分布式等原因,生产的数据会乱序,如果以Event Time来处理数据且以简单的一个时间1来到就默认时间1之前的数据都已经到达,这样就会造成数据丢失、不准确的问题。
此时就需要引入Watermark机制(是Flink插入到数据流中的一种特殊的数据结构,它包含一个时间戳,并假设后续不会有小于该时间戳的数据),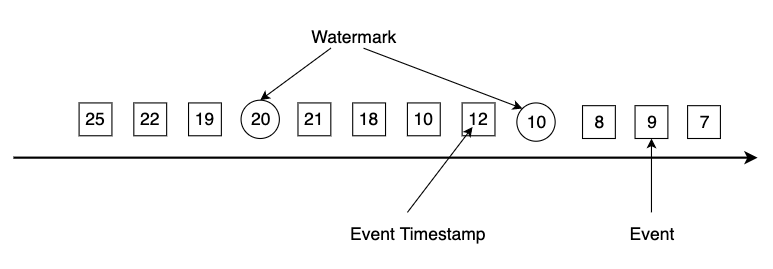
- Watermark与事件的时间戳紧密相关。一个时间戳为T的Watermark假设后续到达的事件时间戳都大于T。
- 假如Flink算子接收到一个违背上述规则的事件,该事件将被认定为迟到数据,如上图中时间戳为19的事件比Watermark(20)更晚到达。Flink提供了一些其他机制来处理迟到数据。
- Watermark时间戳必须单调递增,以保证时间不会倒流(已经到达数据的时间最大值,一般WaterMark设置比最大时间小一点,可以保证有点延迟)。
- Watermark机制允许用户来控制准确度和延迟。Watermark设置得与事件时间戳相距紧凑,会产生不少迟到数据,影响计算结果的准确度,整个应用的延迟很低;Watermark设置得非常宽松,准确度能够得到提升,但应用的延迟较高,因为Flink必须等待更长的时间才进行计算。
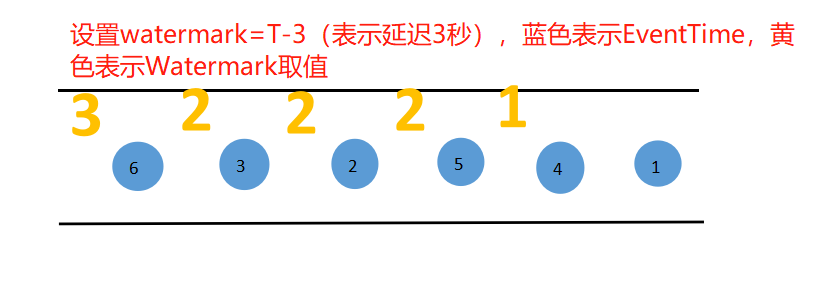
上图每次watermark的取值表示次之之前的数据已经到齐,可以关闭窗口。当WaterMark的取值为5时,表示0-5的窗口需要关闭,即可以进行计算输出。
五、WaterMark的传递
在实际计算过程中,Flink的算子一般分布在多个并行的分区(或者称为实例)上,Flink需要将Watermark在并行环境下向前传播。如下图所示,Flink的每个并行算子子任务会维护针对该子任务的Event Time时钟,这个时钟记录了这个算子子任务Watermark处理进度,随着上游Watermark数据不断向下发送,算子子任务的Event Time时钟也要不断向前更新。由于上游各分区的处理速度不同,到达当前算子的Watermark也会有先后快慢之分,每个算子子任务会维护来自上游不同分区的Watermark信息(会根据并行流的不同维护在不同的分区里),这是一个列表,列表内对应上游算子各分区的Watermark时间戳等信息。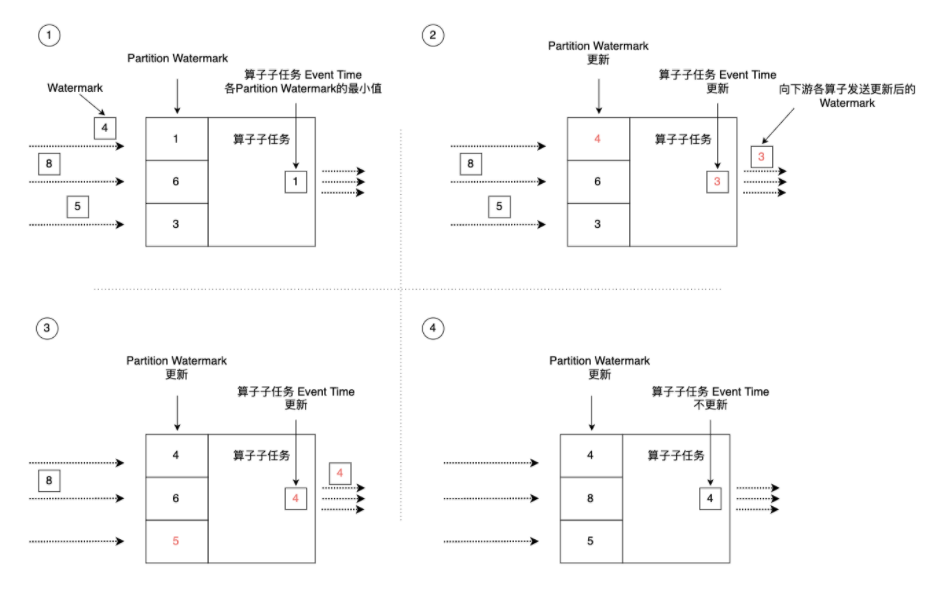
当上游某分区有Watermark进入该算子子任务后,Flink先判断新流入的Watermark时间戳是否大于Partition Watermark列表内记录的该分区的历史Watermark时间戳,如果新流入的更大,则更新该分区的Watermark。例如,某个分区新流入的Watermark时间戳为4,算子子任务维护的该分区Watermark为1,那么Flink会更新Partition Watermark列表为最新的时间戳4。接着,Flink会遍历Partition Watermark列表中的所有时间戳,选择最小的一个作为该算子子任务的Event Time。同时,Flink会将更新的Event Time作为Watermark发送给下游所有算子子任务。算子子任务Event Time的更新意味着该子任务将时间推进到了这个时间,该时间之前的事件已经被处理并发送到下游。例如,图中第二步和第三步,Partition Watermark列表更新后,导致列表中最小时间戳发生了变化,算子子任务的Event Time时钟也相应进行了更新。整个过程完成了数据流中的Watermark推动算子子任务Watermark的时钟更新过程。Watermark像一个幕后推动者,不断将流处理系统的Event Time向前推进。我们可以将这种机制总结为:
- Flink某算子子任务根据各上游流入的Watermark来更新Partition Watermark列表。
- 选取Partition Watermark列表中最小的时间作为该算子的Event Time,并将这个时间发送给下游算子。
这样的设计机制满足了并行环境下Watermark在各算子中的传播问题,但是假如某个上游分区的Watermark一直不更新,Partition Watermark列表其他地方都在正常更新,唯独个别分区的时间停留在很早的某个时间,这会导致算子的Event Time时钟不更新,相应的时间窗口计算也不会被触发,大量的数据积压在算子内部得不到处理,整个流处理处于空转状态。这种问题可能出现在使用数据流自带的Watermark,自带的Watermark在某些分区下没有及时更新。针对这种问题,一种解决办法是根据机器当前的时钟周期性地生成Watermark。
此外,在union等多数据流处理时,Flink也使用上述Watermark更新机制,那就意味着,多个数据流的时间必须对齐,如果一方的Watermark时间较老,那整个应用的Event Time时钟也会使用这个较老的时间,其他数据流的数据会被积压。一旦发现某个数据流不再生成新的Watermark,我们要在SourceFunction中的SourceContext里调用markAsTemporarilyIdle设置该数据流为空闲状态。

若有收获,就点个赞吧
0 人点赞
