一、简单转换算子
1、map算子
// 将输入数据 一对一处理val streamMap = stream.map{x=>x*2}//用法二、通过Map转换算子把textFile转换为SensorReading类型的DataStreamval dsStream : DataStream[SensorReading] = stream.map(e => {val datas = e.split(",")SensorReading(datas(0).trim.toString, datas(1).trim.toLong, datas(2).trim.toDouble)//返回值})
2、flatMap算子
//把一个集合类型打散变成一个新的集合类型//如:flatMap(List(1,2,3))(i=>List(i,i)),结果是(1,1,2,2,3,3)用法一:flapMap 将输入数据打散成一个Listval stream1 = env.fromCollection(List(SensorReading("1", 1111111111, 21.11),SensorReading("2", 1111111112, 21.22),SensorReading("1", 1111111112, 21.22)))val flapMap = stream1.flatMap(t=> List(t.id, t.timestamps, t.temperature)).map(t=> (t,t.toString.toDouble*2))flapMap.print("flapMap transform:")//用法二:flapMap 将输入的list数据 组合在一起 例如wordcount//(首先把第一个元素进行处理,再进行第二个元素的处理,最后把所有处理后的元素进行合并)val flapMap1 = List("a b c d", "b c f e").flatMap(_.split(" "))print(flapMap1)
3、filter算子
//fliter 过滤出表达式返回true的数据val fil = stream1.filter(t => t.id == "1" && t.id.toInt%2!=0)fil.print("fliter transform:")
二、聚合分组算子
1、keyBy算子和滚动聚合算子
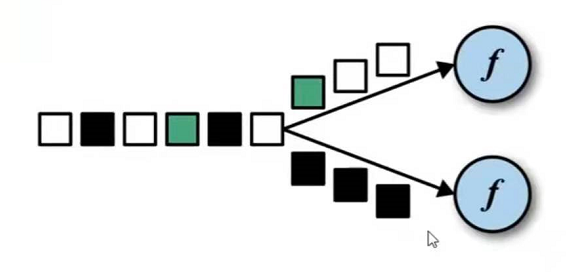
两者需要配合使用
//转换算子四:keyBy DataStream->KeyedStream 分区不分流只是将流对象转换了//数据形式没改变只是可以进行聚合操作了,其实就是分组了,每个分区内部包含相同key的所有元素//数据如下://s1, 1589897275136, 35.980//s1, 1581287812378, 35.980//s2, 1589897275141, 34.543//s3, 1589891285141, 36.789//s4, 1589897221736, 33.134//s4, 1589897221736, 33.134//s4, 1512736712361, 33.134val keyDSStream = dsStream.keyBy(_.id).sum(1) // 每组根据第二个参数进行求和,下标为1,这里keyBy的参数可以指定下标或者属性值keyDSStream.print("------1").setParallelism(1)dsStream.keyBy(_.id).max(1).print("max")dsStream.keyBy(_.id).min(1).print("min")//minBy、maxBy和min、max的区别在于前者会取最小最大的整一条数据,后者只会取指定那个属性值的最小或者最大,其他属性值可能不是那条的//reduce聚合(比较灵活) 当前传感器最新的温度+10 上一次的时间戳+1//第一个参数表示已经规约好了的数据,第二个参数表示当前要处理的数据val reduce: DataStream[SensorReading] = keyBy.reduce((curState, newData)=> SensorReading(curState.id, curState.timestamp+1, newData.temperature+10))reduce.print("reduce transform:").setParallelism(1)
三、多流转换算子
1、Split算子和Select算子
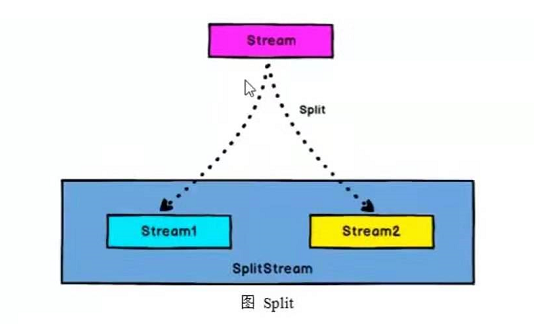
split算子根据某些特征,把一个DataStream分成多个DataStream(DataStream->SplitStream)。
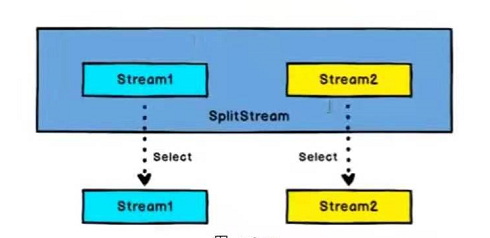
而select算子,是从一个SplitStream中获取一个或者多个DataStream(SplitStream->DataStream)。
Split算子一般配合select算子进行使用
//多流转换算子 map&select//map可以对数据进行分组,select可以从分组的dataStream中获取不同的Streamval splitDStream = dsStream.split(datas => {if (datas.temperature > 35) Seq("higth") else Seq("low")})val low = splitDStream.select("low") // 通过使用select选择哪些流进行处理,可以传多个参数指定多个流val higth = splitDStream.select("higth")val all = splitDStream.select("higth","low")
2、合流算子Connect和CoMap
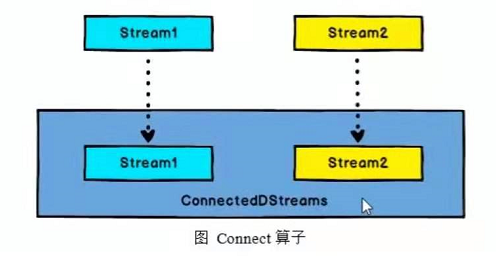
DataStream,DataStream->ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被连接之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。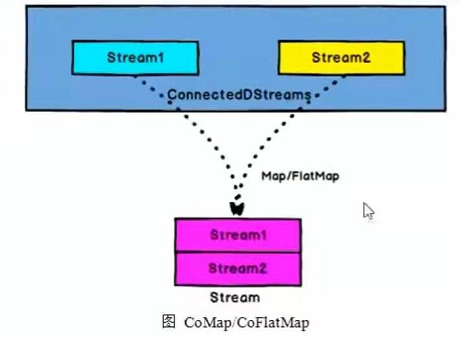
ConnectedStreams->DataStream:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStream中的每一个Stream分别进行map和flatMap处理。
// 例子一:val warning = higth.map( data => (data.id,data.temperature))val connectStream = warning.connect(low) //两个进行connect元素的类型可以不一样val coMapResultStream = connectStream.map( //传入两个参数,第一个参数表示connect前面的元素,第二个参数表示connect后面的元素warningData => (warningData._1,warningData._2), //对一个进行处理lowData => (lowData) //对第二个进行处理).print("connect = ") //输出的类型也可以不一样// 例子二://可以把两个stream进行合并,然后通过map或者flatMap操作val someStream : DataStream[Int] = env.fromCollection(List(1,2,3,4,5,6))val otherStream : DataStream[String] = env.fromCollection(List("A","B","C","D"))val connect = someStream.connect(otherStream)//map方法第一个参数是表示connect前的元素connect.map(x => (x,"Int"),y => (y,"String")).print("connect = ").setParallelism(1)//例子三:union联合算子,可以合并多条流 , 但是流之间的数据结果必须相同val sec : DataStream[String] = env.fromCollection(List("E"))val third : DataStream[String] = env.fromCollection(List("F"))otherStream.union(sec,third).print("UNION = ")//结果 A B C D E F

若有收获,就点个赞吧
0 人点赞
