一、Flink中的状态
- 无状态的计算观察每个独立事件,并根据最后一个事件输出结果。
- 有状态的计算则会基于多个事件输出结果。
下图展示了无状态流处理和有状态流处理的主要区别:
- 无状态流处理分别接收每条数据记录(图中的黑条),然后根据最新输入的数据生成输出数据(白条)。
- 有状态流处理会维护状态(根据每条输入记录进行更新),并基于最新输入的记录和当前的状态值生成输出记录(灰条)。
图中输入数据由黑条表示。无状态流处理每次只转换一条输入记录,并且仅根据最新的输入记录输出结果(白条)**。有状态流处理维护所有已处理记录的状态值,并根据每条新输入的记录更新状态,因此输出记录(灰条)反映的是综合考虑多个事件之后的结果。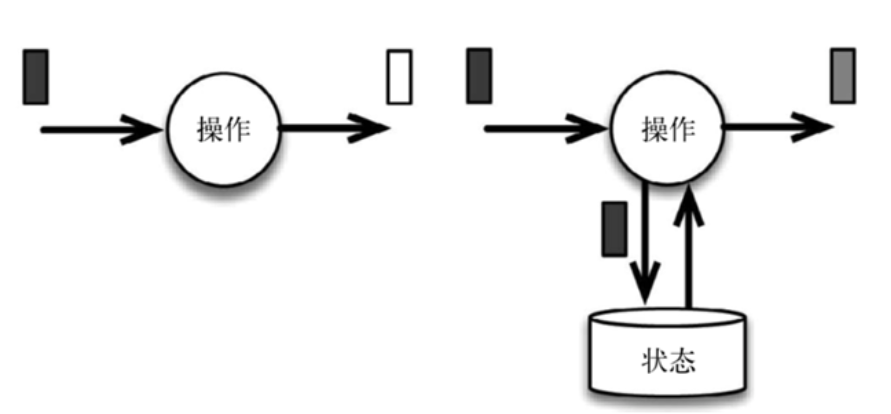
状态的主要概念:**
- 由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态
- 可以认为状态就是一个本地变量,可以被任务的业务逻辑访问
- Flink会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑
- 在Flink中,状态始终与特定的算子相关连在一起
- 为了使运行时的Flink了解算子的状态,算子需要预先注册其状态
状态分类:
1、ManagerState—推荐使用,Flink自动管理/优化,支持多种数据结构
算子的状态,总的有两种:
- 算子状态(Operator State):算子状态的作用范围限定为算子任务,**一个任务一个状态(**即是状态对于同一个任务而言是共享的,每一个并行的子任务共享一个状态;算子状态不能由相同或不同算子的另一个任务访问,相同算子的不同任务之间也不能访问)
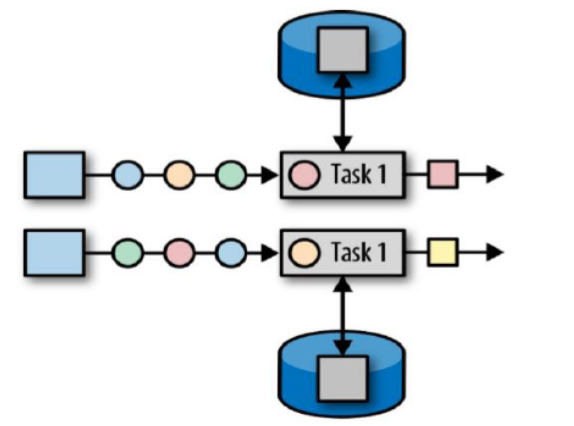
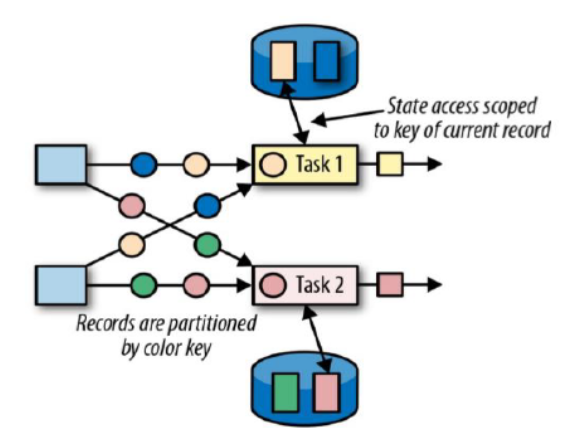
- 键控状态(Keyed State):根据输入数据流中定义的键(Key,在Keyby之后)来维护和访问(**不同的key也是独立访问的,一个key只能访问它自己的状态,不同key之间也不能互相访问**)
2、Raw State—完全由用户自己管理,只支持byte[],只能在自定义Operator上使用
- OperatorState
算子状态提供三种数据结构:
① 列表状态(List state),将状态表示为一组数据的列表;(会根据并行度的调整把之前的状态重新分组重新分配)
② 联合列表状态(Union list state),也将状态表示为数据的列表,它常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复(把之前的每一个状态广播到对应的每个算子中)。
③ 广播状态(Broadcast state),如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态(把同一个状态广播给所有算子子任务)。
键控状态Keyed State 数据结构:
① 值状态(ValueState
- get操作: ValueState.value()
- set操作: ValueState.update(T value)
② 列表状态(ListState
- ListState.add(T value)
- ListState.addAll(List
values) - ListState.get()返回Iterable
- ListState.update(List
values)
③ 映射状态(MapState
- MapState.get(UK key)
- MapState.put(UK key, UV value)
- MapState.contains(UK key)
- MapState.remove(UK key)
④ 聚合状态(ReducingState
二、Demo
package windowimport java.{lang, util}import datasource.SensorReadingimport org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction, RichReduceFunction}import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor, ReducingState, ReducingStateDescriptor, ValueState, ValueStateDescriptor}import org.apache.flink.configuration.Configurationobject StateTest {def main(args: Array[String]): Unit = {}}//状态必须定义在RichFunction中,因为需要运行时上下文class MyRichMapper extends RichMapFunction[SensorReading,String]{//有两种方法定义一个状态//第一种,通过生命周期方法去调用var valueState: ValueState[Double] = _override def open(parameters: Configuration): Unit = {valueState = getRuntimeContext.getState(new ValueStateDescriptor[Double]("valuestate"))}//第二种,通过lazy标识只有在使用到才调用lazy val valueState2: ValueState[Double] = getRuntimeContext.getState(new ValueStateDescriptor[Double]("valuestate",classOf[Double]))//ListState的声明lazy val listState: ListState[Int] = getRuntimeContext.getListState(new ListStateDescriptor[Int]("liststate",classOf[Int]))//MapState的声明lazy val mapState: MapState[String,Double] = getRuntimeContext.getMapState(new MapStateDescriptor[String,Double]("mapstate",classOf[String],classOf[Double]))//ReduceState的声明,参数比其他状态多一个,需要传入一个Reduce函数lazy val reduceState: ReducingState[SensorReading] = getRuntimeContext.getReducingState(new ReducingStateDescriptor[SensorReading]("reducestate",new MyReduce,classOf[SensorReading]))override def map(value: SensorReading): String = {//状态的读写操作val myVal: Double = valueState.value()valueState.update(value.temperature)listState.add(1)listState.update(new util.ArrayList[Int]()(1,2,3))listState.addAll(new util.ArrayList[Int]()(1,2,3))val listIterable: lang.Iterable[Int] = listState.get()mapState.contains("sensor1")mapState.get("sensor1")mapState.put("key",12.33)reduceState.get()//获取聚合完成的值reduceState.add(_)//添加新的值进去reducevalue.id}}class MyReduce extends ReduceFunction[SensorReading]{override def reduce(value1: SensorReading, value2: SensorReading): SensorReading = ???}
三、温度报警Demo
当温度跳变超过10时,输出当前的数据
package stateimport datasource.SensorReadingimport org.apache.flink.api.common.functions.RichFlatMapFunctionimport org.apache.flink.api.common.state.ValueStateDescriptorimport org.apache.flink.streaming.api.scala._import org.apache.flink.util.Collectorobject TempAlarmDemo {def main(args: Array[String]): Unit = {val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(1)val inputData: DataStream[String] = env.socketTextStream("localhost",7777)val dataStream: DataStream[SensorReading] = inputData.map(data=>{val arr: Array[String] = data.split(",")SensorReading(arr(0).trim , arr(1).trim.toLong , arr(2).trim.toDouble)})dataStream.keyBy(_.id).flatMap(new TempAlarmFunction).print("alarm")env.execute("TempAlarm")}}class TempAlarmFunction extends RichFlatMapFunction[SensorReading,SensorReading]{lazy val tempStatevalue = getRuntimeContext.getState(new ValueStateDescriptor[Double]("tempstate",classOf[Double]))override def flatMap(value: SensorReading, out: Collector[SensorReading]): Unit = {val nowData: Double = tempStatevalue.value()if (nowData != null && (nowData - value.temperature).abs > 10){out.collect(value) // 通过该方法输出数据}tempStatevalue.update(value.temperature)}}
//方法三: 带状态的flatMapval processedStream3: DataStream[(String, Double, Double)] = dataStream.keyBy(_.id).flatMapWithState[(String, Double, Double), Double]{//如果没有状态的话,也就是没有数据过来,那么就将当前数据湿度值存入状态case (input: SensorReading, None) => (List.empty, Some(input.temperature))//如果有状态,就应该与上次的温度值比较差值,如果大于阈值就输出报警case(input: SensorReading, lastTemp: Some[Double]) =>val diff = (input.temperature - lastTemp.get).absif (diff > 10.0){(List((input.id, lastTemp.get, input.temperature)), Some(input.temperature))}else{(List.empty, Some(input.temperature))}}
四、状态后端
— 状态管理(存储、访问、维护和检查点)
每传入一条数据,有状态的算子任务都会读取和更新状态;
由于有效的状态访问对于处理数据的低效迟至关重要,因此每个并行任务都会在本地维度其状态,以确保快速的状态访问;
状态的存储、访问以及维度,由一个可插入的组件决定,这个组件就叫做状态后端(State Backends);
状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储;
状态后端的分类
① MemoryStateBackend: 一般用于开发和测试
- 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager的JVM堆上,而将checkpoint存储在JobManager的内存中;
- 特点快速、低延迟,但不稳定;
② FsStateBackend(文件系统状态后端):生产环境
- 将checkpoint存到远程的持久化文件系统(FileSystem),HDFS上,而对于本地状态,跟MemoryStateBackend一样,也会存到TaskManager的JVM堆上。
- 同时拥有内存级的本地访问速度,和更好的容错保证;(如果是超大规模的需要保存还是无法解决,存到本地状态就可能OOM)
③ RocksDBStateBackend:
- 将所有状态序列化后,存入本地的RocksDB(本地数据库硬盘空间,序列化到磁盘)中存储,全部序列化存储到本地。
设置状态后端为FsStateBackend,并配置检查点和重启策略: ```scala StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1);<!-- 需要引入第三方的依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_2.12</artifactId><version>1.10.1</version></dependency>
// 1. 状态后端配置 //env.setStateBackend(new MemoryStateBackend()); //默认的状态后端策略 env.setStateBackend(new FsStateBackend(“路径”, true)) //env.setStateBackend(new RocksDBStateBackend(“路径”,true)) 第二个参数表示增量是否存盘,开启了就表示之前的checkpoint都不能丢
// 2. 检查点配置 开启checkpoint,设置checkpoint生成周期,单位毫秒 env.enableCheckpointing(1000);//等同于env.getCheckpointConfig.setCheckpointInterval(1000)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setCheckpointTimeout(60000);//设置checkpoint超时时间,超时了直接丢弃 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500L);//设置两次checkpoint最小相隔时间 env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//设置checkpoint并行度 env.getCheckpointConfig().setPreferCheckpointForRecovery(true);//是否更倾向使用checkpoint来进行故障恢复,也可以使用savepoint env.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);//设置容忍checkpoints失败次数,如果cp失败也认为是任务失败 env.getCheckpointConfig().setCheckpointInterval(10000L)
// 3. 重启策略配置 // 固定延迟重启(隔一段时间尝试重启一次) env.setRestartStrategy(RestartStrategies.fixedDelayRestart( 3, // 尝试重启次数 100000L // 尝试重启的时间间隔,也可org.apache.flink.api.common.time.Time )); env.setRestartStrategy(RestartStrategies.failureRateRestart(5, Time.minutes(5), Time.seconds(10))) ```
五、Flink的容错机制
5.1、一致性检查点(Checkpoints)
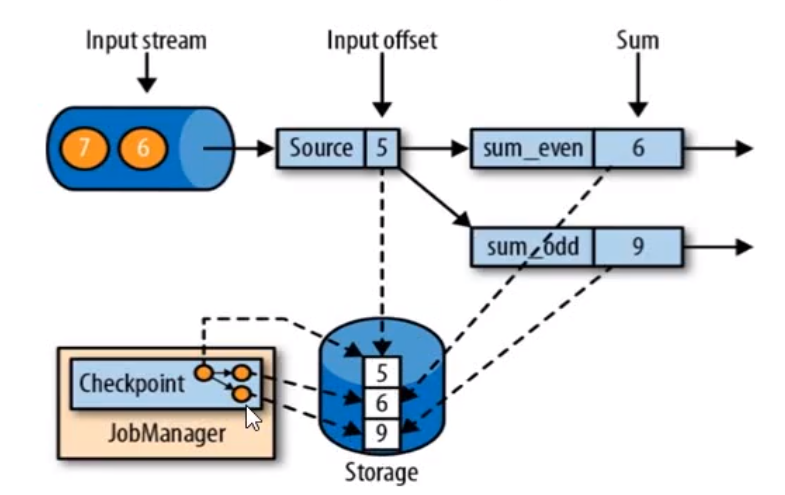
简单来说就是对所有任务进行一个存盘,在某一个时间点把所有任务的状态进行一份拷贝(快照),等到出现故障再把所有状态逐个读出来。当分布式计系统中引入状态计算时,就无可避免一致性的问题(比如故障发生在状态更新前还是更新后,恢复故障时需要恢复到哪一个时间点)。为什么了?因为若是计算过程中出现故障,中间数据咋办了?若是不保存,那就只能重新从头计算了,不然怎么保证计算结果的正确性。这就是要求系统具有容错性了。
难点:不同的任务在同一时间点怎么确定
这个时间点应该是所有任务恰好处理完一个相同的输入数据的时候
5.2、从检查点恢复状态
1、在执行流应用程序期间,Flink会定期保存状态的一致性检查点,不同的任务都会保存一份(如上图三个任务保存的5、6、9)
2、如果发生故障,Flink将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程
3、重启应用,从checkpoint中读取状态,将状态重置;从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
4、开始消费并处理检查点到发生故障之间的所有数据,称之为exactly-one的一致性(对状态来说)
5.3、Flink检查点算法
Flink基于检查点算法的优化实现–基于Chandy-Lamport算法的分布式快照,将检查点的保存和数据分开处理,不需要暂停整个应用。
检查点分界线(Checkpoint Barrier):
- Flink检查点算法用到一种称为分界线(barrier)的特殊数据形式用来把一条流上数据按照不同的检查点分开(类似watermark)
- 分界线之前来到的数据导致的状态更改,都会被包含在当前分界线所属的检查点中;而基于分界线之后的数据导致的所有更改,就会被包含在之后的检查点中
- 通过jobmanager进行管理,只需在source插入就行,数据往下游传递就会收到该checkpoint barrier;但是在多个并行任务的时候,下游的任务需要等待所有上游的checkpoint barrier,等待所有的checkpoint barrier到达才进行checkpoint
算法:
- 首先JobManager会向每一个source任务发生一条带有新检查点(ID为2)的消息,通过该方式来启动检查点
- source将读取的偏移量状态写入检查点为2的状态后端中,并往下游发送一个barrier(检查点的ID对应也为2);状态后端保存成功后通知source,source任务会向jobmanager确定检查点已经完成(此处为异步操作)
- ID为2的barrier会向下游传递,每到达一个分区,该分区中的数据就会被缓存到状态后端中;
- 其中有一个分界线对齐机制,即是barrier向下游传递,下游任务会等待所有上游分区的barrier到达;对于有barrier已经到达的分区,继续到达的数据会被缓存(缓存起来的数据会等到checkpoint完成后继续按顺序处理);而对于那些barrier尚未到达的的分区,数据会被正常处理。
- 当收到所有输入分区的barrier时,任务就将其状态保存到状态后端的checkpoint中,然后继续将barrier下发。
- 直到sink向jobmanager确认状态保存到状态后端完成,此次所有任务的checkpoint就正式完成了。
5.4、保存点(save point)
- Flink提供的可以自定义的镜像保存功能
- 原则上,创建savepoint的算法和checkpoint的算法完全相同,因为savepoint可以认为就是具有一些额外元数据的checkpoint
- Flink不会自动创建savepoint,因此用户必须明确地触发savepoint创建操作
- savepoint处理用于故障恢复,还可以被用于手动备份,更新应用程序,版本迁移,暂停和重启应用等
六、状态一致性
6.1、状态一致性
- 有状态的流处理,内部每个算子任务都可以由自己的状态
- 对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确
- 一条数据不应该被丢失,也不应该重复计算
- 再遇到故障可以恢复状态,恢复后的重新计算,结果也是完全正确的
状态一致性分类:
- AT-MOST-ONCE(最多一次)
- 当任务故障时,最简单的做法就是什么都不做,既不恢复丢失的状态,也不重播丢失的数据;即数据最多只会被计算一次。
- AT-LEAST-ONCE(至少一次)
- 在大多数场景,我们希望不丢失事件,意思就是所有的事件都得到了处理,而一些事件还可能会被多次处理,会造成数据重复计算。
- EXACTLY-ONCE(精确一次)
- 恰好处理一次是最严格的保证,也是最难实现的,不仅仅是事件不能丢失,还需要针对每一个数据,内部状态仅仅更新一次。
6.2、一致性检查点(checkpoint)
6.3、端到端(end-to-end)状态一致性
- 目前看到的一致性保证都是在流处理器内部实现的;但是在真实的应用中,流处理应用除了流处理器以外还包含了数据源source和输出到持久化系统sink的一致性
- 端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终,每一个组件都保证了它自己的一致性
- 整个端到端的一致性级别取决于所有组件中一致性最弱的组件
6.4、端到端的精确一次(exactly-one)保证
- 内部保证-checkpoint
- source端-可重置数据的读取位置
- sink端-从故障恢复时,数据不会重复写入到外部系统
- 幂等写入:就是一个操作,可以重复执行多次,但只导致一次结果更改,也就是说后面的重复操作就不会起作用了(例如hash去重)
- 事务写入:构建事务对应着checkpoint,等到cp真正结束的时候,才把所有对应的结果写入到sink中
- 预写日志,GenericWriteAheadSink模板类
- 两阶段提交,TwoPhaseCommitSinkFunction接口
不同source和sink的一致性保证
| sink\source | 不可重置 | 可重置 |
|---|---|---|
| 任意(Any) | At-most-once | At-least-once |
| 幂等 | At-most-once | Exactly-once(故障恢复时会出现短暂不一致) |
| 预写入日志(WAL) | At-most-once | At-least-once |
| 两阶段提交(2PC) | At-most-once | Exactly-once |
6.5、Flink+fafka端到端状态一致性的保证
- 内部—利用checkpoint机制,把状态存盘,发生故障时进行恢复
- source—可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
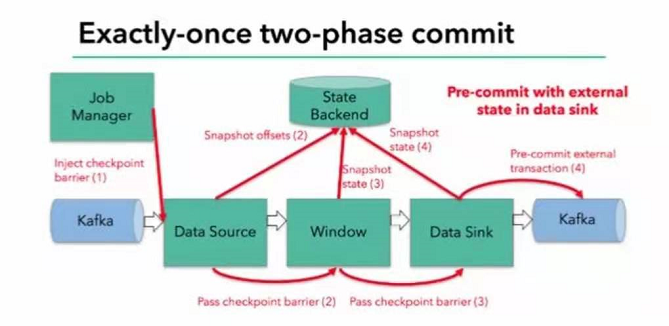
- sink—kafka作为sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction
步骤:
- 第一条数据来了知乎,开启一个kafka的事务,正常写入kafka分区日志但标记为未提交,这就是预提交
- jobmanager触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知jobmanager
- sink连接器收到barrier,保存当前状态,存入checkpoint,通知jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
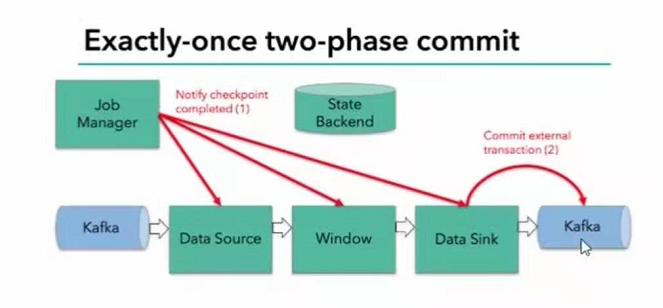
- jobmanager收到所有任务的通知,发出确认信息,表示checkpoint完成
- sink任务收到jobmanager的确认消息,正式提交这个阶段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了

若有收获,就点个赞吧
0 人点赞
