1.什么是 LRU 算法
就是一种缓存淘汰策略。
计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新内容腾位置。但问题是,删除哪些内容呢?我们肯定希望删掉哪些没什么用的缓存,而把有用的数据继续留在缓存里,方便之后继续使用。那么,什么样的数据,我们判定为「有用的」的数据呢?
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
Leetcode-146.LRU缓存机制
运用你所掌握的数据结构,设计和实现一个LRU(最近最少使用)缓存机制.它应该支持以下操作:获取数据get和写入数据put.
获取数据get(key)-如果关键字(key)存在于缓存中,则获取关键字的值(总是正数),否则返回 -1.
写入数据put(key,value)-如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组关键字和值。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 / 缓存容量 / );
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得关键字 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得关键字 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
leetcode官方解法
使用语言本身的数据结构
1.python3——有一种结合了哈希表与双向链表的数据结构 OrderedDict
class LRUCache(collections.OrderedDict):def __init__(self, capacity: int):super().__init__()self.capacity = capacitydef get(self, key: int) -> int:if key not in self:return -1self.move_to_end(key)return self[key]def put(self, key: int, value: int) -> None:if key in self:self.move_to_end(key)self[key] = valueif len(self) > self.capacity:self.popitem(last=False)
2.java——在 Java 语言中,同样有类似的数据结构 LinkedHashMap
class LRUCache extends LinkedHashMap<Integer, Integer>{private int capacity;public LRUCache(int capacity) {super(capacity, 0.75F, true);this.capacity = capacity;}public int get(int key) {return super.getOrDefault(key, -1);}public void put(int key, int value) {super.put(key, value);}@Overrideprotected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {return size() > capacity;}}
2.LRU 算法设计
分析上面的操作过程,要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:查找快,插入快,删除快,有顺序之分。
因为显然 cache 必须有顺序之分,以区分最近使用的和久未使用的数据;而且我们要在 cache 中查找键是否已存在;如果容量满了要删除最后一个数据;每次访问还要把数据插入到队头。
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样: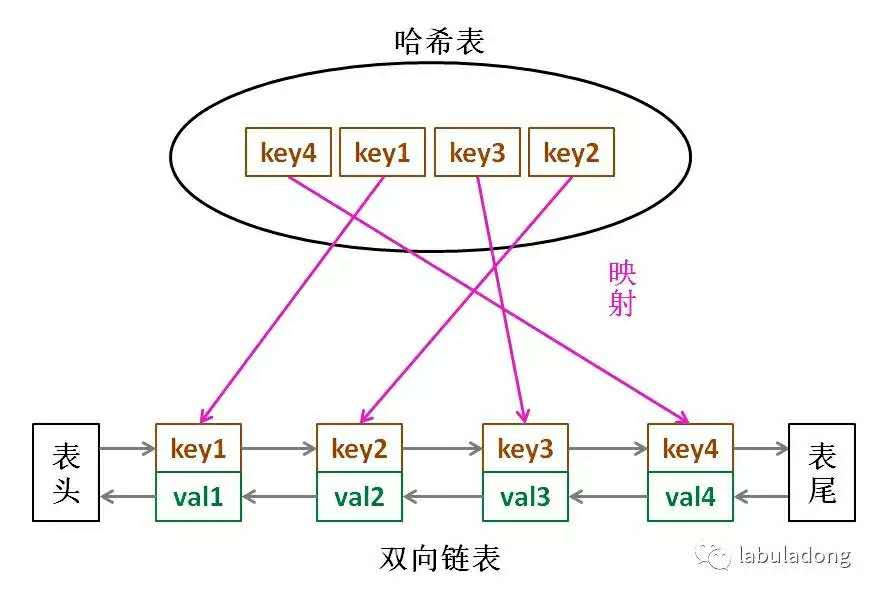
3.如何实现一个生产环境使用的LRU缓存
需求:抽象出一个限定大小的LRU缓存,与之配套的有一个抽象的的低速存储(数据库或者第三方服务)
实现查找,更新,新增的时间复杂度都为O(1),并且实现LRU的缓存淘汰策略
创建一个Key,Value存储抽象
/*** KV存储抽象*/public interface Storage<K,V> {/*** 根据提供的Key来访问数据* @param key* @return*/V get(K key);}
/*** LRU缓存,你需要继承这个抽象类来实现LRU缓存* @param <K>* @param <V>*/public abstract class LruCache<K,V> implements Storage<K,V>{//缓存容量,你能使用的最大缓存容量protected final int capacity;//低速存储,所有的数据都能从这里读到(对应的是数据库或者是第三方服务抽象)protected final Storage<K,V> lowSpeedStorage;public LruCache(int capacity, Storage<K, V> lowSpeedStorage) {this.capacity = capacity;this.lowSpeedStorage = lowSpeedStorage;}}
/*** Google面试题* Design an LRU cache with all the operations to be done in O(1)** 使所有操作的的时间复杂度都为O(1),包括插入,替换,查找* 利用双向链表+哈希表:前者支持插入和替换都为O(1),后者支持查询O(1)* @param <K>* @param <V>*/public class LruCacheImpl<K,V> extends LruCache<K,V>{HashMap<K,Node> map = new HashMap<K, Node>();//声明一个头节点和一个尾节点Node head = null;Node end = null;public LruCacheImpl(int capacity, Storage<K, V> lowSpeedStorage) {super(capacity, lowSpeedStorage);}@Overridepublic V get(K key){//查询缓存是否存在V v1 = getValue(key);//缓存不存在if(v1 == null) {//查询lowSpeedStorage(类似磁盘)V v2 = lowSpeedStorage.get(key);if(v2 != null){//lowSpeedStorage存在,将它放入缓存中set(key,v2);}return v2;}return v1;}//获取一个缓存后,应该把这个数据在当前位置移除,并重新添加到头的位置,这些都是在返回数据之前完成的public V getValue(K key){if(map.containsKey(key)){Node n = map.get(key);remove(n);setHead(n);return n.value;}return null;}//移除元素分为,N前面和N后面都要看是怎么样的情况public void remove (Node n){if(n.pre != null){//将链表需要移除的前一个节点的尾指针指向需要移除的节点的尾指针的节点n.pre.next = n.next;}else {//否则说明需要移除的是头节点head = n.next;}if(n.next != null){//将链表需要移除的前一个节点的头指针指向需要移除的节点的头指针的节点n.next.pre = n.pre;}else {//否则说明需要移除的是尾节点end = n.pre;}}//设置成头节点public void setHead(Node n){n.next = head;n.pre = null;if(head !=null){head.pre = n;}head = n;//判断头尾都空的情况if(end == null){end = head;}}//查看原位置是否有元素,如果有的话就替换,证明使用过了,然后将其替换为头节点的元素,如果是一个新的节点就要判断它的大小是否符合规范public void set (K key, V value){if(map.containsKey(key)){Node old = map.get(key);old.value = value;//将元素从原本位置放到头部remove(old);setHead(old);}else {//如果是从低速存储中拿到的新元素,就创建一个NodeNode created = new Node(key,value);//判断当插入这个新有元素的时候,map现在的使用情况是否已经超过了缓存的上限,超过就移除尾节点if(map.size() >= capacity){map.remove(end.key);remove(end);setHead(created);}else {setHead(created);}//把新的节点放入map中map.put(key,created);}}//节点,双向链表的基本实现class Node {K key;V value;Node pre;Node next;public Node(K key,V value){this.key = key;this.value = value;}}
2.LRU进阶LRU-K和LRU-2Q
LRU-K
LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。也就是说没有到达K次访问的数据并不会被缓存,这也意味着需要对于缓存数据的访问次数进行计数,并且访问记录不能无限记录,也需要使用替换算法进行替换。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
简单的描述就是:当访问次数达到K次后,将数据索引从历史队列移到缓存队列中(缓存队列时间降序);缓存数据队列中被访问后重新排序;需要淘汰数据时,淘汰缓存队列中排在末尾的数据。
相比于LRU-1(即LRU),缓存数据更不容易被替换,而且偶发性的数据不易被缓存。在保证了缓存数据纯净的同时还提高了热点数据命中率。
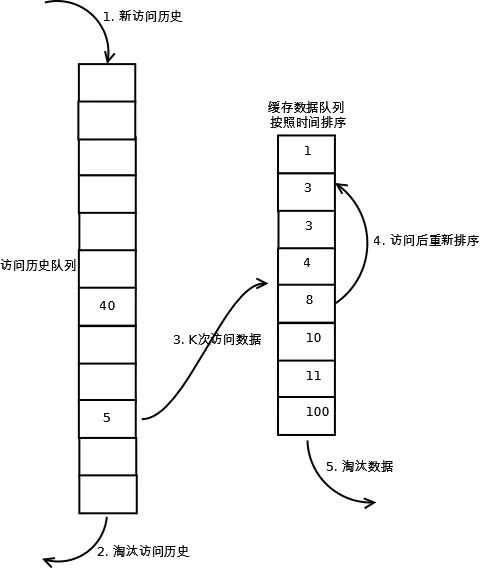
(1). 数据第一次被访问,加入到访问历史列表;
(2). 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
(3). 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
(4). 缓存数据队列中被再次访问后,重新排序;
(5). 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-2Q
1、算法思想
该算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
2、工作原理
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下: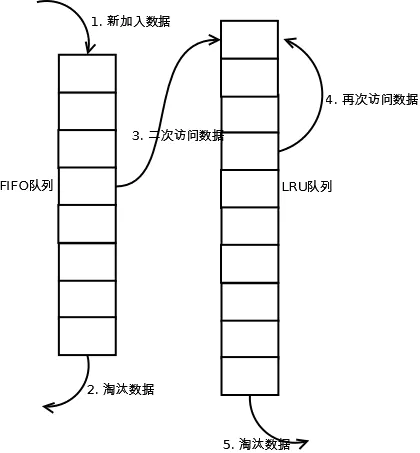
(1). 新访问的数据插入到FIFO队列;
(2). 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
(3). 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
(4). 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
(5). LRU队列淘汰末尾的数据。

若有收获,就点个赞吧
0 人点赞
