go语言的前世今生
go语言的演化历史
go语言的设计哲学
一.简单
1.仅有 25 个关键字,主流编程语言最少;
2.内置垃圾收集,降低开发人员内存管理的心智负担;
3.首字母大小写决定可见性,无需通过额外关键字修饰;
4.变量初始为类型零值,避免以随机值作为初值的问题;
5.内置数组边界检查,极大减少越界访问带来的安全隐患;
6.内置并发支持,简化并发程序设计;
7.内置接口类型,为组合的设计哲学奠定基础;原生提供完善的工具链,开箱即用;
二.显式
1.在 Go 语言中,不同类型变量是不能在一起进行混合计算的,这是因为 Go 希望开发人员明确知道自己在做什么,这与 C 语言的“信任程序员”原则完全不同,因此你需要以显式的方式通过转型统一参与计算各个变量的类型。
2.除此之外,Go 设计者所崇尚的显式哲学还直接决定了 Go 语言错误处理的形态:Go 语言采用了显式的基于值比较的错误处理方案,函数 / 方法中的错误都会通过 return 语句显式地返回,并且通常调用者不能忽略对返回的错误的处理。
三.组合
四.并发
五.面向工程
Go 语言设计的初衷,就是面向解决真实世界中 Google 内部大规模软件开发存在的各种问题,为这些问题提供答案,这些问题包括:程序构建慢、依赖管理失控、代码难于理解、跨语言构建难等。
- 重新设计编译单元和目标文件格式,实现 Go 源码快速构建,让大工程的构建时间缩短到类似动态语言的交互式解释的编译速度;
- 如果源文件导入它不使用的包,则程序将无法编译。这可以充分保证任何 Go 程序的依赖树是精确的。这也可以保证在构建程序时不会编译额外的代码,从而最大限度地缩短编译时间;
- 去除包的循环依赖,循环依赖会在大规模的代码中引发问题,因为它们要求编译器同时处理更大的源文件集,这会减慢增量构建;
- 包路径是唯一的,而包名不必唯一的。导入路径必须唯一标识要导入的包,而名称只是包的使用者如何引用其内容的约定。“包名称不必是唯一的”这个约定,大大降低了开发人员给包起唯一名字的心智负担;
- 故意不支持默认函数参数。因为在规模工程中,很多开发者利用默认函数参数机制,向函数添加过多的参数以弥补函数 API 的设计缺陷,这会导致函数拥有太多的参数,降低清晰度和可读性;
- 增加类型别名(type alias),支持大规模代码库的重构;
在标准库方面,Go 被称为“自带电池”的编程语言。如果说一门编程语言是“自带电池”,则说明这门语言标准库功能丰富,多数功能不需要依赖外部的第三方包或库,Go 语言恰恰就是这类编程语言。
由于诞生年代较晚,而且目标比较明确,Go 在标准库中提供了各类高质量且性能优良的功能包,其中的net/http、crypto、encoding等包充分迎合了云原生时代的关于 API/RPC Web 服务的构建需求,Go 开发者可以直接基于标准库提供的这些包实现一个满足生产要求的 API 服务,从而减少对外部第三方包或库的依赖,降低工程代码依赖管理的复杂性,也降低了开发人员学习第三方库的心理负担。
而且,开发人员在工程过程中肯定是需要使用工具的,Go 语言就提供了足以让所有其它主流语言开发人员羡慕的工具链,工具链涵盖了编译构建、代码格式化、包依赖管理、静态代码检查、测试、文档生成与查看、性能剖析、语言服务器、运行时程序跟踪等方方面面。
这里值得重点介绍的是 gofmt,它统一了 Go 语言的代码风格,在其他语言开发者还在为代码风格争论不休的时候,Go 开发者可以更加专注于领域业务中。同时,相同的代码风格让以往困扰开发者的代码阅读、理解和评审工作变得容易了很多,至少 Go 开发者再也不会有那种因代码风格的不同而产生的陌生感。Go 的这种统一代码风格思路也在开始影响着后续新编程语言的设计,并且一些现有的主流编程语言也在借鉴 Go 的一些设计。
在提供丰富的工具链的同时,Go 在标准库中提供了官方的词法分析器、语法解析器和类型检查器相关包,开发者可以基于这些包快速构建并扩展 Go 工具链。
在这一讲中,我和你一起了解了 Go 语言的设计哲学:简单、显式、组合、并发和面向工程。
- 简单是指 Go 语言特性始终保持在少且足够的水平,不走语言特性融合的道路,但又不乏生产力。简单是 Go 生产力的源泉,也是 Go 对开发者的最大吸引力;
- 显式是指任何代码行为都需开发者明确知晓,不存在因“暗箱操作”而导致可维护性降低和不安全的结果;
- 组合是构建 Go 程序骨架的主要方式,它可以大幅降低程序元素间的耦合,提高程序的可扩展性和灵活性;
- 并发是 Go 敏锐地把握了 CPU 向多核方向发展这一趋势的结果,可以让开发人员在多核时代更容易写出充分利用系统资源、支持性能随 CPU 核数增加而自然提升的应用程序;
- 面向工程是 Go 语言在语言设计上的一个重大创新,它将语言要解决的问题域扩展到那些原本并不是由编程语言去解决的领域,从而覆盖了更多开发者在开发过程遇到的“痛点”,为开发者提供了更好的使用体验。
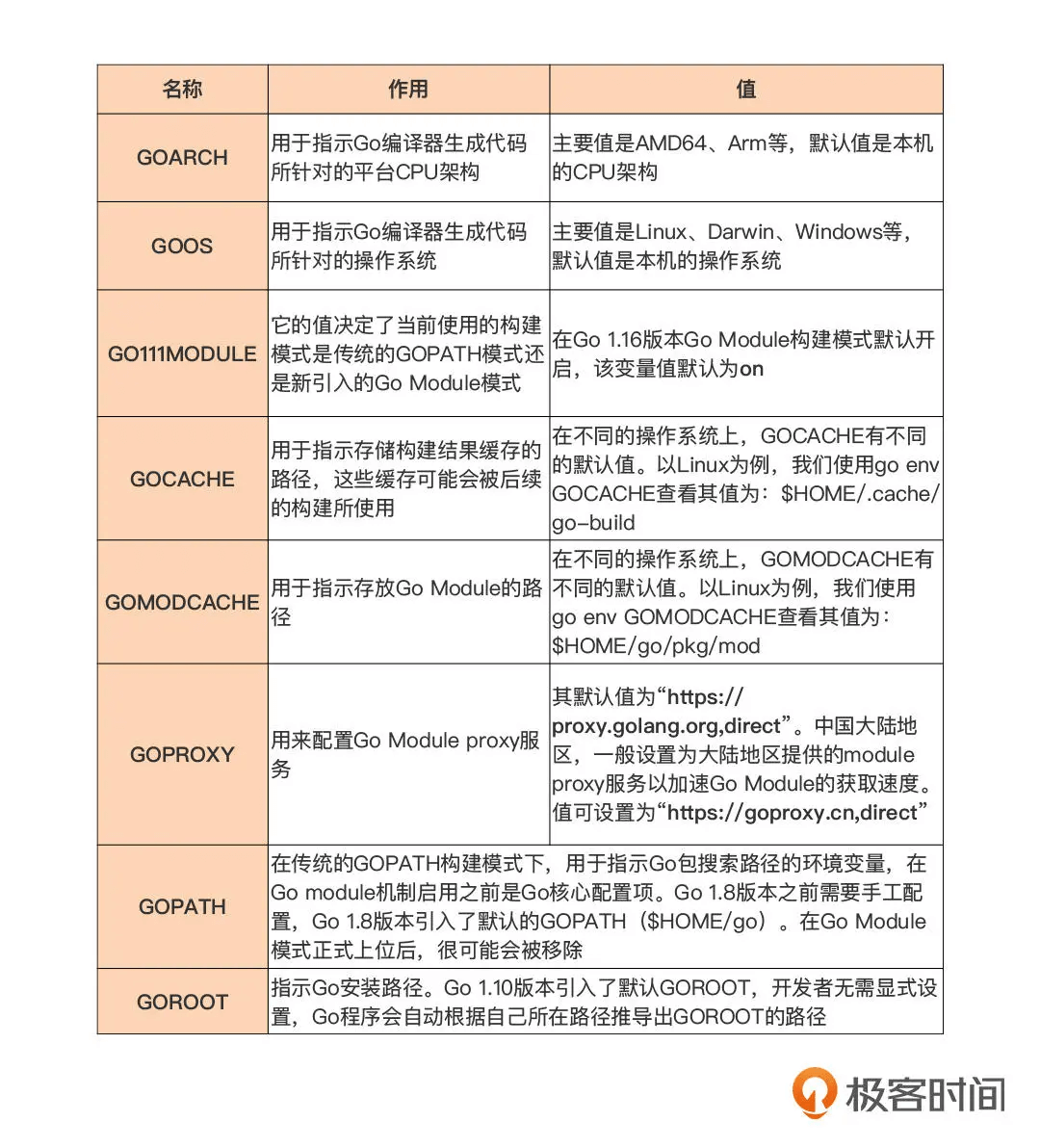
go语言配置环境
在这一节课中我们首先讲解了三种 Go 版本的选择策略:第一种,也是我们推荐的一种,那就是使用 Go 最新的版本,这样你可以体验到 Go 的最新语言特性,应用到标准库的最新 API 以及 Go 工具链的最新功能,并且很多老版本中的 bug 在最新版本中都会得到及时修复;如果你还是对最新版本的稳定性有一丝担忧,你也可以选择使用次新版;最后,如果你要考虑现存生产项目或开源项目,那你按照需要选择,与项目策略保持一致就好了。
go语言规范
这里,我需要跟你啰嗦一下 Go 的命名规则。Go 源文件总是用全小写字母形式的短小单词命名,并且以.go 扩展名结尾。如果要在源文件的名字中使用多个单词,我们通常直接是将多个单词连接起来作为源文件名,而不是使用其他分隔符,比如下划线。也就是说,我们通常使用 helloworld.go 作为文件名而不是 hello_world.go。
最后,不知道你有没有发现,我们整个示例程序源码中,都没有使用过分号来标识语句的结束,这与 C、C++、Java 那些传统编译型语言好像不太一样呀?不过,其实 Go 语言的正式语法规范是使用分号“;”来做结尾标识符的。那为什么我们很少在 Go 代码中使用和看到分号呢?这是因为,大多数分号都是可选的,常常被省略,不过在源码编译时,Go 编译器会自动插入这些被省略的分号。
我们给上面的“hello,world”示例程序加上分号也是完全合法的,是可以直接通过 Go 编译器编译并正常运行的。不过,gofmt 在按约定格式化代码时,会自动删除这些被我们手工加入的分号的。
如果你之前更熟悉某种类似于 Ruby、Python 或 JavaScript 之类的动态语言,你可能还不太习惯在运行之前需要先进行编译的情况。Go 是一种编译型语言,这意味着只有你编译完 Go 程序之后,才可以将生成的可执行文件交付于其他人,并运行在没有安装 Go 的环境中。
而如果你交付给其他人的是一份.rb、.py 或.js 的动态语言的源文件,那么他们的目标环境中就必须要拥有对应的 Ruby、Python 或 JavaScript 实现才能解释执行这些源文件。
深入理解Go Module
首先我们看一下 Go Module 的语义导入版本机制。在上面的例子中,我们看到 go.mod 的 require 段中依赖的版本号,都符合 vX.Y.Z 的格式。在 Go Module 构建模式下,一个符合 Go Module 要求的版本号,由前缀 v 和一个满足语义版本规范的版本号组成。你可以看看下面这张图,语义版本号分成 3 部分:主版本号 (major)、次版本号 (minor) 和补丁版本号 (patch)。例如上面的 logrus module 的版本号是 v1.8.1,这就表示它的主版本号为 1,次版本号为 8,补丁版本号为 1。
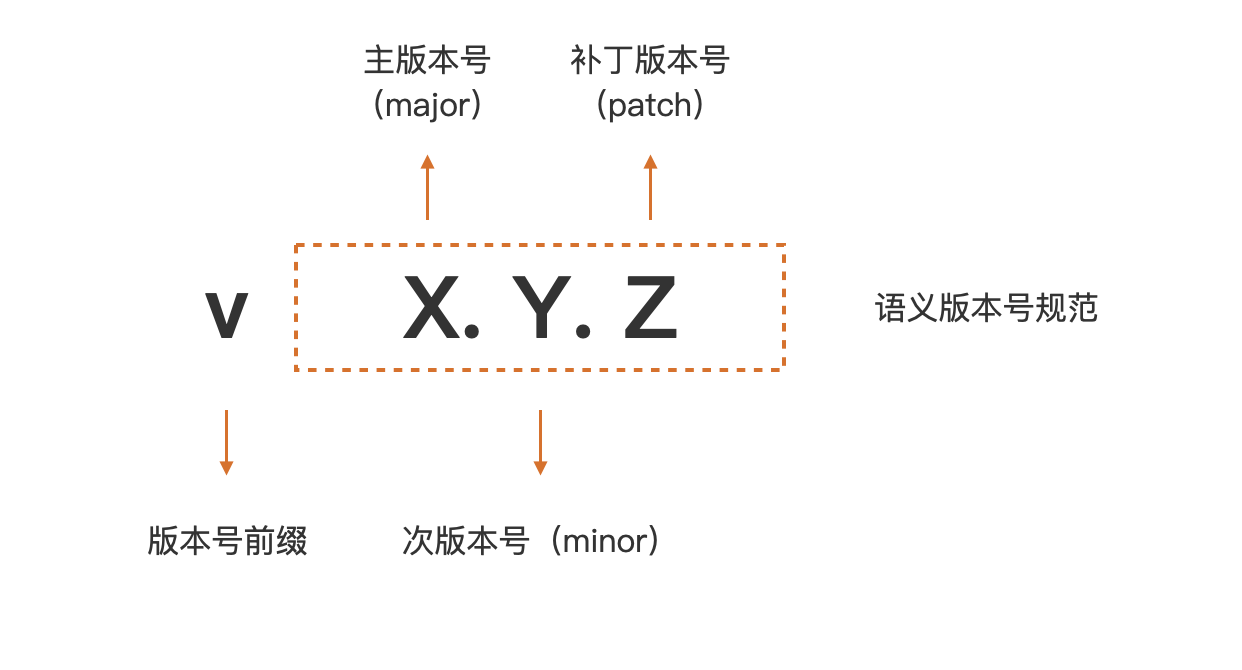
Go 命令和 go.mod 文件都使用上面这种符合语义版本规范的版本号,作为描述 Go Module 版本的标准形式。借助于语义版本规范,Go 命令可以确定同一 module 的两个版本发布的先后次序,而且可以确定它们是否兼容。按照语义版本规范,主版本号不同的两个版本是相互不兼容的。而且,在主版本号相同的情况下,次版本号大都是向后兼容次版本号小的版本。补丁版本号也不影响兼容性。而且,Go Module 规定:如果同一个包的新旧版本是兼容的,那么它们的包导入路径应该是相同的。
怎么理解呢?我们来举个简单示例。我们就以 logrus 为例,它有很多发布版本,我们从中选出两个版本 v1.7.0 和 v1.8.1.。按照上面的语义版本规则,这两个版本的主版本号相同,新版本 v1.8.1 是兼容老版本 v1.7.0 的。那么,我们就可以知道,如果一个项目依赖 logrus,无论它使用的是 v1.7.0 版本还是 v1.8.1 版本,它都可以使用下面的包导入语
句导入 logrus 包:
import "github.com/sirupsen/logrus"
那么问题又来了,假如在未来的某一天,logrus 的作者发布了 logrus v2.0.0 版本。那么根据语义版本规则,该版本的主版本号为 2,已经与 v1.7.0、v1.8.1 的主版本号不同了,那么 v2.0.0 与 v1.7.0、v1.8.1 就是不兼容的包版本。然后我们再按照 Go Module 的规定,如果一个项目依赖 logrus v2.0.0 版本,那么它的包导入路径就不能再与上面的导入方式相同了。那我们应该使用什么方式导入 logrus v2.0.0 版本呢?Go Module 创新性地给出了一个方法:将包主版本号引入到包导入路径中,我们可以像下面这样导入 logrus v2.0.0 版本依赖包:
import "github.com/sirupsen/logrus/v2"
这就是 Go 的“语义导入版本”机制,也就是说通过在包导入路径中引入主版本号的方式,来区别同一个包的不兼容版本,这样一来我们甚至可以同时依赖一个包的两个不兼容版本:
import ("github.com/sirupsen/logrus"logv2 "github.com/sirupsen/logrus/v2")
go包的执行顺序
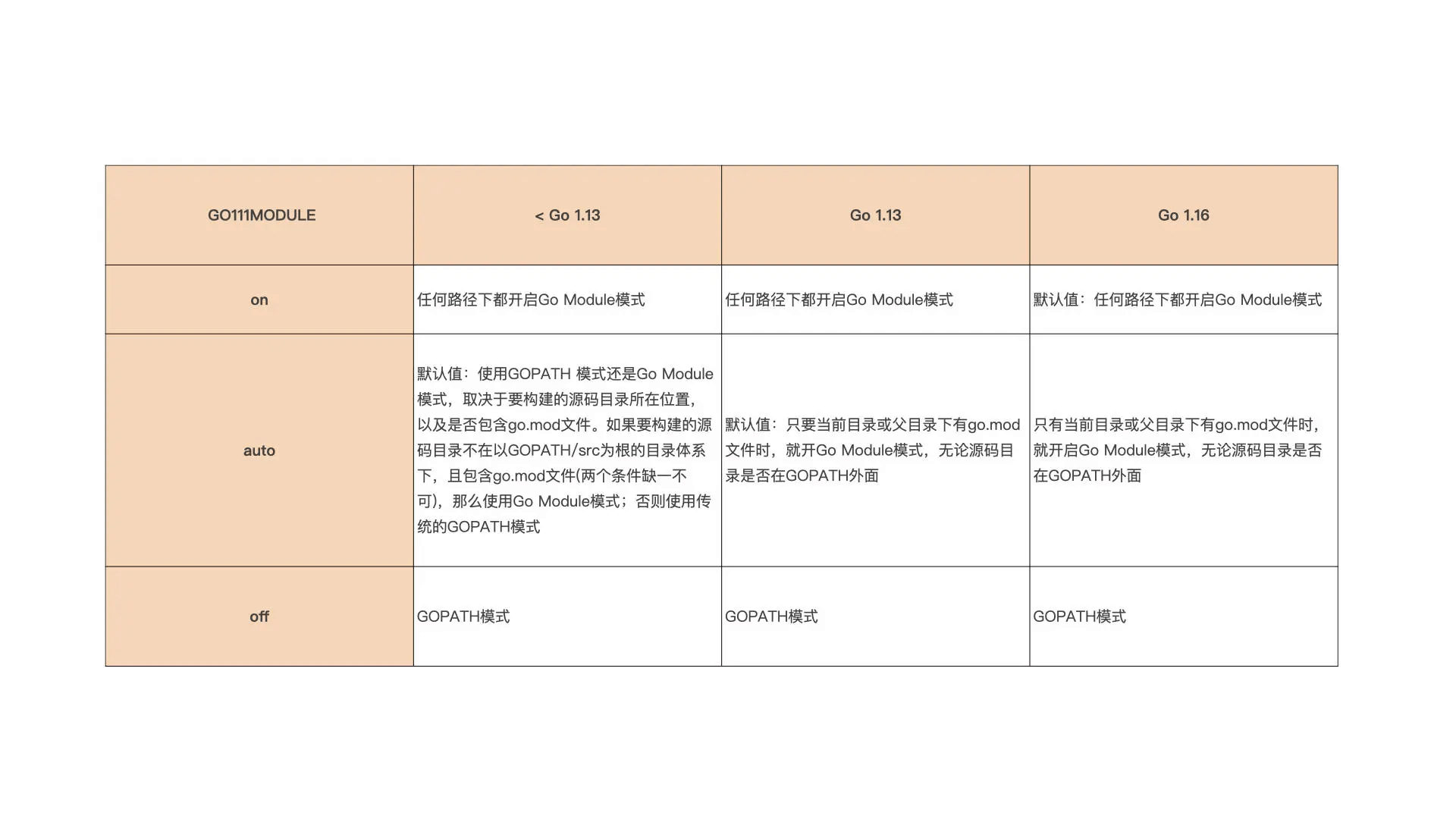
后来,Go 1.11 版本中,Go 核心团队推出了新一代构建模式:Go Module 以及一系列创新机制,包括语义导入版本机制、最小版本选择机制等。语义导入版本机制是 Go Moudle 其他机制的基础,它是通过在包导入路径中引入主版本号的方式,来区别同一个包的不兼容版本。而且,Go 命令使用最小版本选择机制进行包依赖版本选择,这和当前主流编程语言,以及 Go 社区之前的包依赖管理工具使用的算法都有点不同。此外,Go 命令还可以通过 GO111MODULE 环境变量进行 Go 构建模式的切换。但你要注意,从 Go 1.11 到 Go 1.16,不同的 Go 版本在 GO111MODULE 为不同值的情况下,开启的构建模式以及具体表现行为也几经变化,这里你重点看一下前面总结的表格。
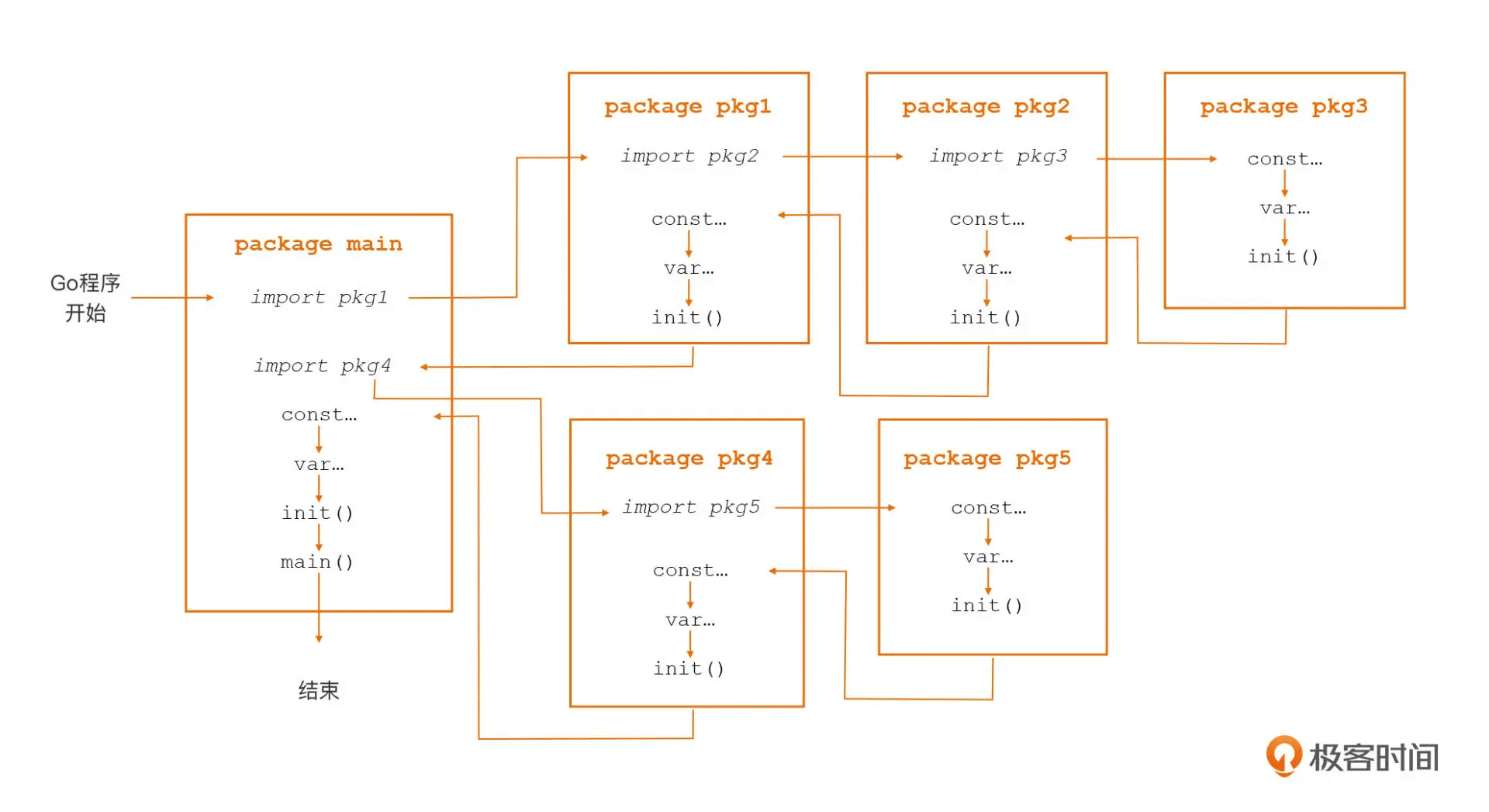
这里,我们来看看具体的初始化步骤。首先,main 包依赖 pkg1 和 pkg4 两个包,所以第一步,Go 会根据包导入的顺序,先去初始化 main 包的第一个依赖包 pkg1。
第二步,Go 在进行包初始化的过程中,会采用“深度优先”的原则,递归初始化各个包的依赖包。在上图里,pkg1 包依赖 pkg2 包,pkg2 包依赖 pkg3 包,pkg3 没有依赖包,于是 Go 在 pkg3 包中按照“常量 -> 变量 -> init 函数”的顺序先对 pkg3 包进行初始化;
紧接着,在 pkg3 包初始化完毕后,Go 会回到 pkg2 包并对 pkg2 包进行初始化,接下来再回到 pkg1 包并对 pkg1 包进行初始化。在调用完 pkg1 包的 init 函数后,Go 就完成了 main 包的第一个依赖包 pkg1 的初始化。
接下来,Go 会初始化 main 包的第二个依赖包 pkg4,pkg4 包的初始化过程与 pkg1 包类似,也是先初始化它的依赖包 pkg5,然后再初始化自身;然后,当 Go 初始化完 pkg4 包后也就完成了对 main 包所有依赖包的初始化,接下来初始化 main 包自身。
- 最后,在 main 包中,Go 同样会按照“常量 -> 变量 -> init 函数”的顺序进行初始化,执行完这些初始化工作后才正式进入程序的入口函数 main 函数。现在,我们可以通过一段代码示例来验证一下 Go 程序启动后,Go 包的初始化次序是否是正确的,示例程序的结构如下: ```go
prog-init-order ├── go.mod ├── main.go ├── pkg1 │ └── pkg1.go ├── pkg2 │ └── pkg2.go └── pkg3 └── pkg3.go
main 包依赖 pkg1 包和 pkg2 包;<br />pkg1 包和 pkg2 包都依赖 pkg3 包。```gopackage mainimport ("fmt"_ "github.com/bigwhite/prog-init-order/pkg1"_ "github.com/bigwhite/prog-init-order/pkg2")var (_ = constInitCheck()v1 = variableInit("v1")v2 = variableInit("v2"))const (c1 = "c1"c2 = "c2")func constInitCheck() string {if c1 != "" {fmt.Println("main: const c1 has been initialized")}if c2 != "" {fmt.Println("main: const c2 has been initialized")}return ""}func variableInit(name string) string {fmt.Printf("main: var %s has been initialized\n", name)return name}func init() {fmt.Println("main: first init func invoked")}func init() {fmt.Println("main: second init func invoked")}func main() {// do nothing}
我们可以看到,在 main 包中其实并没有使用 pkg1 和 pkg2 中的函数或方法,而是直接通过空导入的方式“触发”pkg1 包和 pkg2 包的初始化(pkg2 包也是通过空导入的方式依赖 pkg3 包的),下面是这个程序的运行结果
$go run main.gopkg3: const c has been initializedpkg3: var v has been initializedpkg3: init func invokedpkg1: const c has been initializedpkg1: var v has been initializedpkg1: init func invokedpkg2: const c has been initializedpkg2: var v has been initializedpkg2: init func invokedmain: const c1 has been initializedmain: const c2 has been initializedmain: var v1 has been initializedmain: var v2 has been initializedmain: first init func invokedmain: second init func invoked
你看,正如我们预期的那样,Go 运行时是按照“pkg3 -> pkg1 -> pkg2 -> main”的顺序,来对 Go 程序的各个包进行初始化的,而在包内,则是以“常量 -> 变量 -> init 函数”的顺序进行初始化。此外,main 包的两个 init 函数,会按照在源文件 main.go 中的出现次序进行调用。
还有一点,pkg1 包和 pkg2 包都依赖 pkg3 包,但根据 Go 语言规范,一个被多个包依赖的包仅会初始化一次,因此这里的 pkg3 包仅会被初始化了一次。
所以简而言之,记住 Go 包的初始化次序并不难,你只需要记住这三点就可以了:
- 依赖包按“深度优先”的次序进行初始化;
- 每个包内按以“常量 -> 变量 -> init 函数”的顺序进行初始化;
- 包内的多个 init 函数按出现次序进行自动调用。
init函数的作用

若有收获,就点个赞吧
0 人点赞
