一、初识kubernetes调度
1、Automated Placement为kubernetes带来的问题
Automated Placement是kubernetes调度器的核心功能,那么在实现Automated Placement时,kubernetes需要面对哪些问题呢?
1.1、如何找到一个合适的节点
在一个分布式系统中,常常会面对数十个甚至数百个乃至更多的进程。虽然pod将打包和部署进行了抽象,提供了完善的部署方案,但是如何寻找到一个合适的节点却一直没有解决。要知道容器之间存在依赖关系,容器对节点所提供的资源也有一定的需求,从而使容器对节点也有依赖。而节点在使用过程中,资源消耗也会不断的发生变化,那么如果处理这些问题呢?
1.2、如何满足用户各种各样的调度需求,使pod分布更加完美
在一个分布式系统内,我们要面对的需求有很多,例如:
- 我们需要满足pod尽可能均匀的分布到节点上,避免因为节点异常而导致大量pod无法提供服务。
- 频繁互相调用的pod尽可能分配在同一节点上来降低时延。
- 稀有资源,如GPU需要实现独享,避免无关pod抢占节点,浪费资源。
- 集群长期运行后,节点出现内存、CPU使用比不均衡,导致CPU或内存大量闲置二其余资源耗尽的问题。
那么,kubenetes时如何解决这一系列的问题的呢?这就需要深入理解schedule这一核心组件了,下面让我们来深入学习kube-scheduler。
2、scheduler架构和调度流程
kubernetes调度是基于队列的调度器,在调度过程中,每次进调度一个pod,通过这一机制保证调度时刻的全局最优。在一次完整的调度流程中,scheduler将对pod进行一次筛选及打分。在筛选中,将符合需求的node过滤出来,之后对每一个node进行打分,之后将pod调度到最高分的node上,若存在多个等分的node,则会随机选择一个node进行调度。关于scheduler的架构及详细调度流程如下: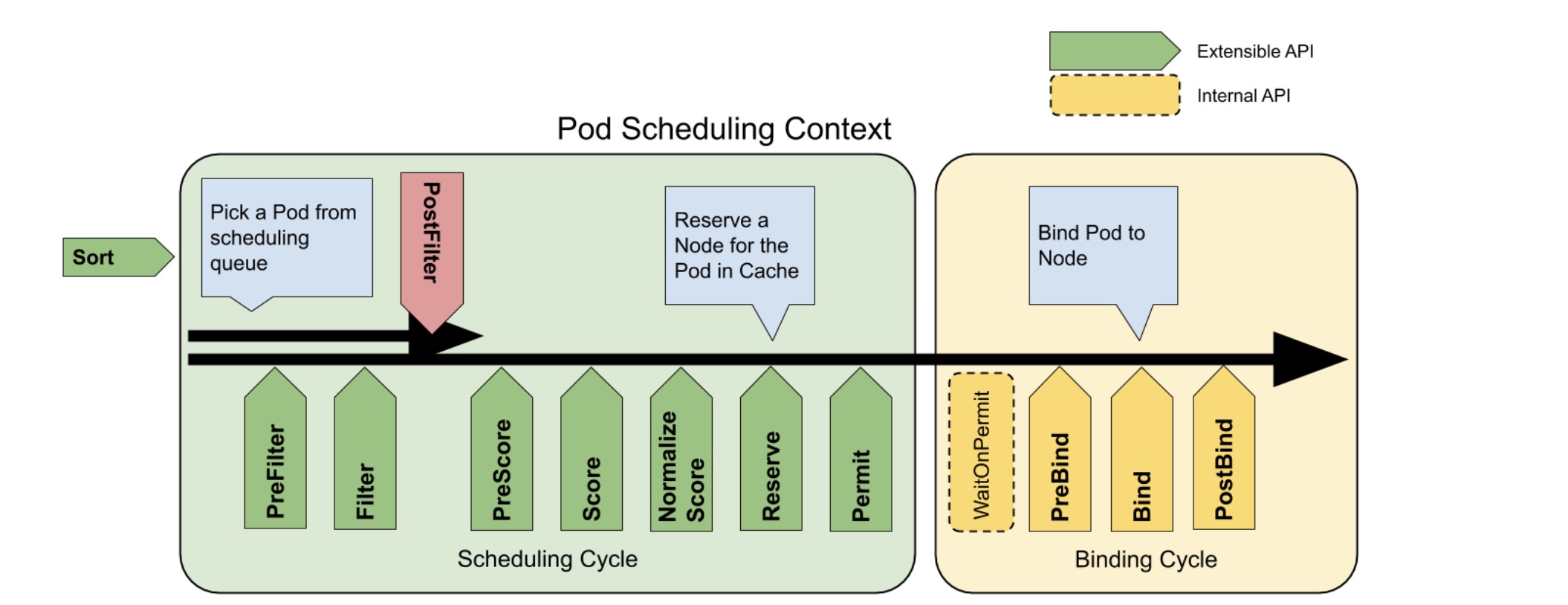
- 通过kubectl交互apiserver后,informer list/watch到资源变化,会更新调度队列和调度缓存
- 队列排序插件用于对调度队列中的 Pod 进行排序。 队列排序插件本质上提供 less(Pod1, Pod2) 函数。 一次只能启动一个队列插件。
- 前置过滤插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。 如果 PreFilter 插件返回错误,则调度周期将终止。
- 过滤插件用于过滤出不能运行该 Pod 的节点。对于每个节点, 调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行, 则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。
- 这些插件在筛选阶段后调用,但仅在该 Pod 没有可行的节点时调用。 插件按其配置的顺序调用。如果任何后过滤器插件标记节点为“可调度”, 则其余的插件不会调用。典型的后筛选实现是抢占,试图通过抢占其他 Pod 的资源使该 Pod 可以调度。
- 前置评分插件用于执行 “前置评分” 工作,即生成一个可共享状态供评分插件使用。 如果 PreScore 插件返回错误,则调度周期将终止。
- 评分插件用于对通过过滤阶段的节点进行排名。调度器将为每个节点调用每个评分插件。 将有一个定义明确的整数范围,代表最小和最大分数。 在标准化评分阶段之后,调度器将根据配置的插件权重 合并所有插件的节点分数。
- 预绑定插件用于执行 Pod 绑定前所需的任何工作。 例如,一个预绑定插件可能需要提供网络卷并且在允许 Pod 运行在该节点之前 将其挂载到目标节点上。
- Bind 插件用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,Bind 插件才会被调用。 各绑定插件按照配置顺序被调用。绑定插件可以选择是否处理指定的 Pod。 如果绑定插件选择处理 Pod,剩余的绑定插件将被跳过。
- 这是个信息性的扩展点。 绑定后插件在 Pod 成功绑定后被调用。这是绑定周期的结尾,可用于清理相关的资源。
3、深入理解过滤策略
过滤算法是在kubernetes调度过程中,对于节点进行粗过滤,在这个过程中过滤掉不符合需求的节点,保留下可用节点。具体算法如下:
| 算法名称 | 功 能 |
|---|---|
| GeneralPredicates | 检查node是否与pod所需资源匹配,包括cpu、mem、gpu、pod上限等 |
| NoDiskConflict | 检查node是否满足存储需求,是否存在卷冲突。 |
| CheckVolumeBinding | 检查是否满足pod资源对象pvc的挂载 |
| NoVolumeZoneConflict | 检查pod资源对象挂载pvc是否跨区域挂载 |
| CheckNodeMemoryPressure | 检查node是否满足pod的内存需求 |
| CheckNodePidPressure | 检查node是否进程压力过大 |
| PodToleratesNodeTaints | 检查pod是否可以容忍污点 |
| MatchInterPodAffinity | 检查亲和性 |
根据以上算法已经可以筛选出来一批可用节点,那么如何将pod调度到最适合的节点呢?
4、深入理解优选策略
在过滤策略筛选后的node是完全可以符合pod需求的,但是在这么多的node中五和选择一个最适配pod的节点,就需要通过优选策略了。具体算法如下:
| 算法名称 | 功 能 |
|---|---|
| LeastRequestedPriority | 按node计算资源,挑选最空闲node |
| MostRequestedPriority | 按node计算资源,挑选消耗最大的node |
| BalancedResourceAllocation | 补充LeastRequestedPriority,平衡men和cpu剩余 |
| SelectorSpreadPriority | 同一个svc或rc下的pod尽可能打散 |
| NodeAffinityPriority | 按亲节点和性打分,命中规则越高分越高 |
| TaintTolerationPriority | 按污点匹配,越多的污点不匹配,分数越低 |
| InterPodAffinityPriority | 按照pod亲和性和反亲和性规则匹配进行打分 |
| ImageLocalityPriority | 若节点是否已有当前所需镜像来打分 |
通过上述算法进行打分后,pod将调度到最高分节点,至此,一次pod调度循环结束。至此,我们学习到了,kubernetes时如何实现Automated Placement中最基本的需求,如何找到一个合适的节点,那么其他的调度需求又是如何实现的呢?
二、kube-scheduler的个性化调度
1、selector机制
当我们的kubernetes集群中有大量节点,并且节点功能不同时,我们可以给节点添加label进行区分,一边对节点进行分组管理,例如:
- 针对稀有资源添加label,对使用SSD的节点,添加DISK=SSD的label,对使用GPU的节点accelerator=nvidia的label
- 根据服务前端后端添加label,前端APP=front,后端APP=backend
当我们通过标签对节点进行分组后,在编排pod时,就可以通过nodeSelector来筛选节点,将pod调度到期望的节点上了。
2、Affinity与Anti-Affinity机制
虽然selector可以帮我们实现对节点的进一步管理,但是在分布式系统内,仍然会出现多个pod调度到同一节点上这一现象,一旦节点异常,便不得不面对大量pod无法提供服务的困境,针对这一问题,kubernetes提供了Anti-affinity这一机制,实现代码如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
上述代码实现了同一标签的pod不在同一节点上这一需求,同样的,也可以针对某些需要调度到同一节点的应用,我们也可以通过pod Affinity来实现,代码如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
特别需要注意的是,Affinity和AntiAffinity不仅可以作用于pod和pod之前,还可以实现节点的亲和性一反亲和性,而且还支持requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution,也就是硬亲和性和软亲和性,这使得 Affinity和Anti-Affinity使用的越来越广泛。
3、Taint机制
前文提到过,我们在节点中会提供例如SSD、GPU等昂贵的资源,虽然有selector Anti-Affinity等机制,但仍然无法避免pod调度到这类稀有资源的节点上,从而占用稀有资源产生浪费,那么这个时候就需要在用Taint来实现进一步的约束。
假设这里有一个节点node1,上面存在有GPU,那么为了保护这个节点,我们可以先执行如下命令
# 添加 GPU 标签
kubectl label nodes node1 accelerator=nvidia
# 添加污点
kubectl taint nodes node1 special=true:NoSchedule
之后我们就可以通过如下代码,将需要CPU的pod调度到该节点,而其他pod则无法调度到该节了
tolerations:
- key: "special"
operator: "Equal"
value: "true"
effect: "NoExecute"
tolerationSeconds: 3600
4、Descheduler
在kubernetes中,一个pod一旦调度到一个node上,除非发生node异常,或者是手动删除pod,否则,pod上不会不会迁移。那么随着时间的迁移,调度工作可能会引发资源碎片化,集群资源利用率低,部分节点负载过高等问题,同时修改节点的label也不会修正之前的调度结果。为了修正这一问题,kubernetes sigs社区推出了Descheduler 工具。
Descheduler 支持多种解调度策略:
4.1、RemoveDuplicates
此策略确保每个副本集(RS)、副本控制器(RC)、部署(Deployment)或任务(Job)只有一个 pod 被分配到同一台 node 节点上。如果有多个则会被驱逐到其它节点以便更好的在集群内分散 pod。
可用字段如下:
| Name | Type |
|---|---|
| excludeOwnerKinds | list(string) |
| namespaces | (see namespace filtering) |
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| nodeFit | bool (see node fit filtering) |
模版:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemoveDuplicates":
enabled: true
params:
removeDuplicates:
excludeOwnerKinds:
- "ReplicaSet"
4.2、LowNodeUtilization
此策略会查找未充分利用的节点,并在可能的情况下从其他节点驱逐pod。可以对noode配置threshold,当一个节点上mem、cpu、pod数量多资源均低于threshold时,则认为此node资源利用率低。
可用参数如下:
| Name | Type |
|---|---|
| thresholds | map(string:int) |
| targetThresholds | map(string:int) |
| numberOfNodes | int |
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| nodeFit | bool (see node fit filtering) |
配置模版
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"LowNodeUtilization":
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
# 支持原生资源类型为 cpu、mem、pod数,默认thresholds为100
# 可扩展资源类型
# thresholds不可超过targetThresholds,并且范围为[0-100]
4.3、HighNodeUtilization
此策略是发现为充分利用的node,并驱逐此node上的pod。节点为充分利用的thresholds是可以配置的,thresholds可以配置为 mem、cpu、pod数量的百分比,如果节点低于此thresholds,就认为此节点为充分利用。可用字段为:
| Name | Type |
|---|---|
| thresholds | map(string:int) |
| numberOfNodes | int |
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| nodeFit | bool (see node fit filtering) |
配置模板:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"HighNodeUtilization":
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
# 支持原生资源类型为 cpu、mem、pod数,默认thresholds为100
# 可扩展资源类型
# thresholds不可超过targetThresholds,并且范围为(0-100]
4.4、RemovePodsViolatingInterPodAntiAffinity
此策略会暴力清除node中违反pod亲和性的pod。
可用参数:
Parameters:
| Name | Type |
|---|---|
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| namespaces | (see namespace filtering) |
| labelSelector | (see label filtering) |
| nodeFit | bool (see node fit filtering) |
代码模板:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingInterPodAntiAffinity":
enabled: true
4.5、RemovePodsViolatingNodeAffinity
此策略会移除node中所有违反node亲和性的pod,并在下次调度中遵守node亲和性。
可用字段:
| Name | Type |
|---|---|
| nodeAffinityType | list(string) |
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| namespaces | (see namespace filtering) |
| labelSelector | (see label filtering) |
| nodeFit | bool (see node fit filtering) |
代码模板:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingNodeAffinity":
enabled: true
params:
nodeAffinityType:
- "requiredDuringSchedulingIgnoredDuringExecution"
4.6、RemovePodsViolatingNodeTaints
此策略会移除该node上违反node 污点容忍的pod。
可以参数:
| Name | Type |
|---|---|
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| namespaces | (see namespace filtering) |
| labelSelector | (see label filtering) |
| nodeFit | bool (see node fit filtering) |
代码模板:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingNodeTaints":
enabled: true
4.7、RemovePodsViolatingTopologySpreadConstraint
该策略确保 从节点驱逐违反拓扑扩展约束的node。具体而言,它尝试逐出将拓扑域平衡到每个约束的内所需的最小Pod数maxSkew。此策略至少需要k8s 1.18版。
可用参数:
| Name | Type |
|---|---|
| includeSoftConstraints | bool |
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| namespaces | (see namespace filtering) |
| labelSelector | (see label filtering) |
| nodeFit | bool (see node fit filtering) |
代码模板:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingTopologySpreadConstraint":
enabled: true
params:
includeSoftConstraints: false
4.8、RemovePodsHavingTooManyRestarts
此策略用于移除该node上重启次数过多的pod。
可用参数:
Parameters:
| Name | Type |
|---|---|
| podRestartThreshold | int |
| includingInitContainers | bool |
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| namespaces | (see namespace filtering) |
| nodeFit | bool (see node fit filtering) |
代码模板:
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsHavingTooManyRestarts":
enabled: true
params:
podsHavingTooManyRestarts:
podRestartThreshold: 100
includingInitContainers: true
4.9、PodLifeTime
此策略驱逐了超过maxPodLifeTimeSeconds的pod
| Name | Type |
|---|---|
| maxPodLifeTimeSeconds | int |
| podStatusPhases | list(string) |
| thresholdPriority | int (see priority filtering) |
| thresholdPriorityClassName | string (see priority filtering) |
| namespaces | (see namespace filtering) |
| labelSelector | (see label filtering) |
至此我们已经充分的了解了kubenetes调度的原理。

若有收获,就点个赞吧
0 人点赞
