一、初识docker网络
1、从内核开始认识docker网络
从网络角度看docker的技术架构,则是利用NetWork NameSpace 为底层实现的。那么,NetWorkNameSpace又是什么呢?
1.1 NetWorkNameSpace是什么
NetWorkNameSpace是linux内核提供的一种进行网络隔离额资源,通过调用CLONE_NEWNET参数来实现网络设备、网络栈、端口等资源的隔离。NetWorkNameSpace可以在一个操作系统内创建多个网络空间,并为每一个网络空间创建独立的网络协议栈,系统管理员也可以通过ip工具来进行管理
[root@docker1 ~]# ip net helpUsage: ip netns listip netns add NAMEip netns set NAME NETNSIDip [-all] netns delete [NAME]ip netns identify [PID]ip netns pids NAMEip [-all] netns exec [NAME] cmd ...ip netns monitorip netns list-id
我们先尝试通过ip netns add example_net1命令创建一个名为example_net1的namespace
[root@docker1 ~]# ip netns add example_net1
[root@docker1 ~]# ip netns list example_net1
[root@docker1 ~]# ls /var/run/netns/ example_net1
在这个新的namespace内,会有独立的网卡、arp表、路由表、iptables规则,我们可以通过ip netns exec 命令来进行查看
[root@docker1 ~]# ip netns exec example_net1 ip link list
1: lo: <loopback> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@docker1 ~]# ip netns exec example_net1 route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
[root@docker1 ~]# ip netns exec example_net1 iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
[root@docker1 ~]# ip netns exec example_net1 arp -a
通过上述实验我们可以看到,namespace的arp表、路由表、iptables规则是隔离开的,那么网卡我们怎么来验证一下呢?下面我们先创建一对网卡,并将其中一个网卡插入到namespace中
[root@docker1 ~]# ip link add type veth
[root@docker1 ~]# ip link list
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens32: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:fc:3f:5f brd ff:ff:ff:ff:ff:ff
3: docker0: <no-carrier,broadcast,multicast,up> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:ad:84:cb:87 brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <broadcast,multicast,m-down> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 86:62:51:08:e8:1b brd ff:ff:ff:ff:ff:ff
5: veth1@veth0: <broadcast,multicast,m-down> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 3a:21:26:35:f8:82 brd ff:ff:ff:ff:ff:ff
[root@docker1 ~]# ip link set veth0 netns example_net1
[root@docker1 ~]# ip link list
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens32: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:fc:3f:5f brd ff:ff:ff:ff:ff:ff
3: docker0: <no-carrier,broadcast,multicast,up> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:ad:84:cb:87 brd ff:ff:ff:ff:ff:ff
5: veth1@if4: <broadcast,multicast> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 3a:21:26:35:f8:82 brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@docker1 ~]# ip netns exec example_net1 ip link list
1: lo: <loopback> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0@if5: <broadcast,multicast> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 86:62:51:08:e8:1b brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@docker1 ~]#
我们可以看到,创建完veth pair后,可以看到5个网卡,当将veth0插入到example_net1 namespace后,便只剩下了4个网卡,而example_net1 中多了一个veth0,所以,网卡也是隔离开的。
1.2 不同NetWorkNameSpace之间是怎么通信的呢
那么跨namespace是怎么通信的呢?我们可以再深入模拟一下,下面我们创建另一个namespace,并veth1插入到另一个namespace中
[root@docker1 ~]# ip netns add example_net2
[root@docker1 ~]# ip link set veth1 netns example_net2
下面我们开始配置网卡
[root@docker1 ~]# ip netns exec example_net1 ip link set veth0 up
[root@docker1 ~]# ip netns exec example_net2 ip link set veth1 up
[root@docker1 ~]# ip netns exec example_net1 ip addr add 172.19.0.1/24 dev veth0
[root@docker1 ~]# ip netns exec example_net2 ip addr add 172.19.0.2/24 dev veth1
[root@docker1 ~]# ip netns exec example_net1 ip a
1: lo: <loopback> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0@if5: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 86:62:51:08:e8:1b brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 172.19.0.1/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::8462:51ff:fe08:e81b/64 scope link
valid_lft forever preferred_lft forever
[root@docker1 ~]# ip netns exec example_net2 ip a
1: lo: <loopback> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: veth1@if4: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 3a:21:26:35:f8:82 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.19.0.2/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::3821:26ff:fe35:f882/64 scope link
valid_lft forever preferred_lft foreve
现在两个namespace可以通信了,网络模型如下图所示 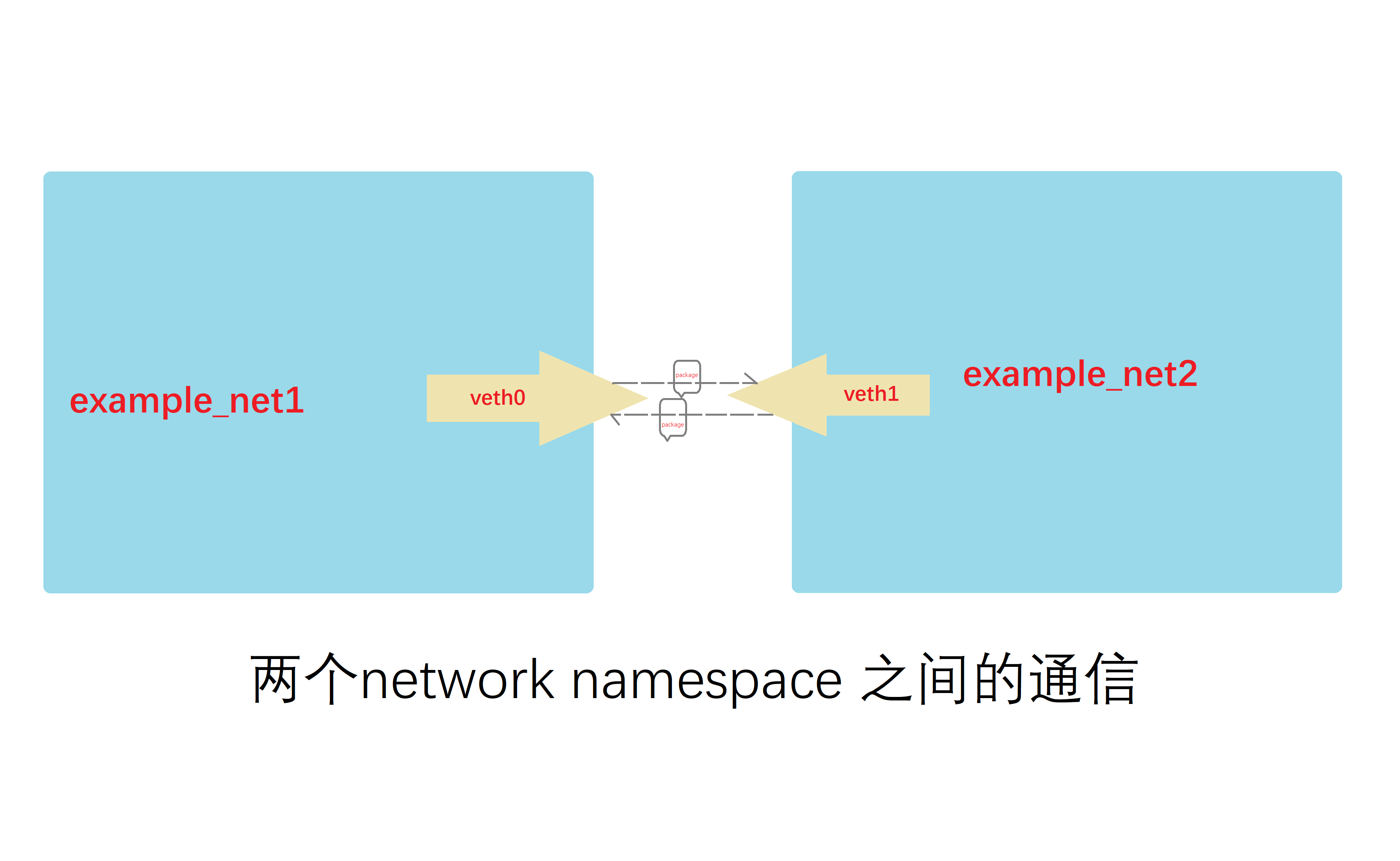
[root@docker1 ~]# ip netns exec example_net1 ping 172.19.0.2
PING 172.19.0.2 (172.19.0.2) 56(84) bytes of data. 64 bytes from 172.19.0.2:
icmp_seq=1 ttl=64 time=0.095 ms 64 bytes from 172.19.0.2:
icmp_seq=2 ttl=64 time=0.042 ms 64 bytes from 172.19.0.2:
icmp_seq=3 ttl=64 time=0.057 ms ^C
--- 172.19.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2015ms
rtt min/avg/max/mdev = 0.042/0.064/0.095/0.024 ms
[root@docker1 ~]#
现在我们已经高度接近容器网络了,那么docker中用于跨主机通信的docker0又是怎么实现的呢?下面我们在另一台机器上模拟一下。
[root@docker2 ~]# ip netns add ns1
[root@docker2 ~]# ip netns add ns2
[root@docker2 ~]# brctl addbr bridge0
[root@docker2 ~]# ip link set dev bridge0 up
[root@docker2 ~]# ip link add type veth
[root@docker2 ~]# ip link add type veth
[root@docker2 ~]# ip link list
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens32: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:1b:1e:63 brd ff:ff:ff:ff:ff:ff
3: docker0: <no-carrier,broadcast,multicast,up> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:85:70:1a:f0 brd ff:ff:ff:ff:ff:ff
24: bridge0: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether 8e:34:ad:1e:80:18 brd ff:ff:ff:ff:ff:ff
25: veth0@veth1: <broadcast,multicast,m-down> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether a2:2f:0e:64:d0:7b brd ff:ff:ff:ff:ff:ff
26: veth1@veth0: <broadcast,multicast,m-down> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether d6:13:14:1a:d4:42 brd ff:ff:ff:ff:ff:ff
27: veth2@veth3: <broadcast,multicast,m-down> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 2e:f1:f1:ae:77:1e brd ff:ff:ff:ff:ff:ff
28: veth3@veth2: <broadcast,multicast,m-down> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether da:08:09:21:36:98 brd ff:ff:ff:ff:ff:ff
[root@docker2 ~]# ip link set dev veth0 netns ns1
[root@docker2 ~]# ip netns exec ns1 ip addr add 192.21.0.1/24 dev veth0
[root@docker2 ~]# ip netns exec ns1 ip link set veth0 up
[root@docker2 ~]# ip link set dev veth3 netns ns2
[root@docker2 ~]# ip netns exec ns2 ip addr add 192.21.0.2/24 dev veth3
[root@docker2 ~]# ip netns exec ns2 ip link set veth3 up
[root@docker2 ~]# ip link set dev veth1 master bridge0
[root@docker2 ~]# ip link set dev veth2 master bridge0
[root@docker2 ~]# ip link set dev veth1 up
[root@docker2 ~]# ip link set dev veth2 up
[root@docker2 ~]# ip netns exec ns1 ping 192.21.0.2
PING 192.21.0.2 (192.21.0.2) 56(84) bytes of data. 64 bytes from 192.21.0.2:
icmp_seq=1 ttl=64 time=0.075 ms 64 bytes from 192.21.0.2:
icmp_seq=2 ttl=64 time=0.064 ms 64 bytes from 192.21.0.2: icmp_seq=3 ttl=64 time=0.077 ms ^C
--- 192.21.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2005ms
rtt min/avg/max/mdev = 0.064/0.072/0.077/0.005 ms
这个就模拟了容器通过docker0网桥通信的过程,网络模型如下图所示。 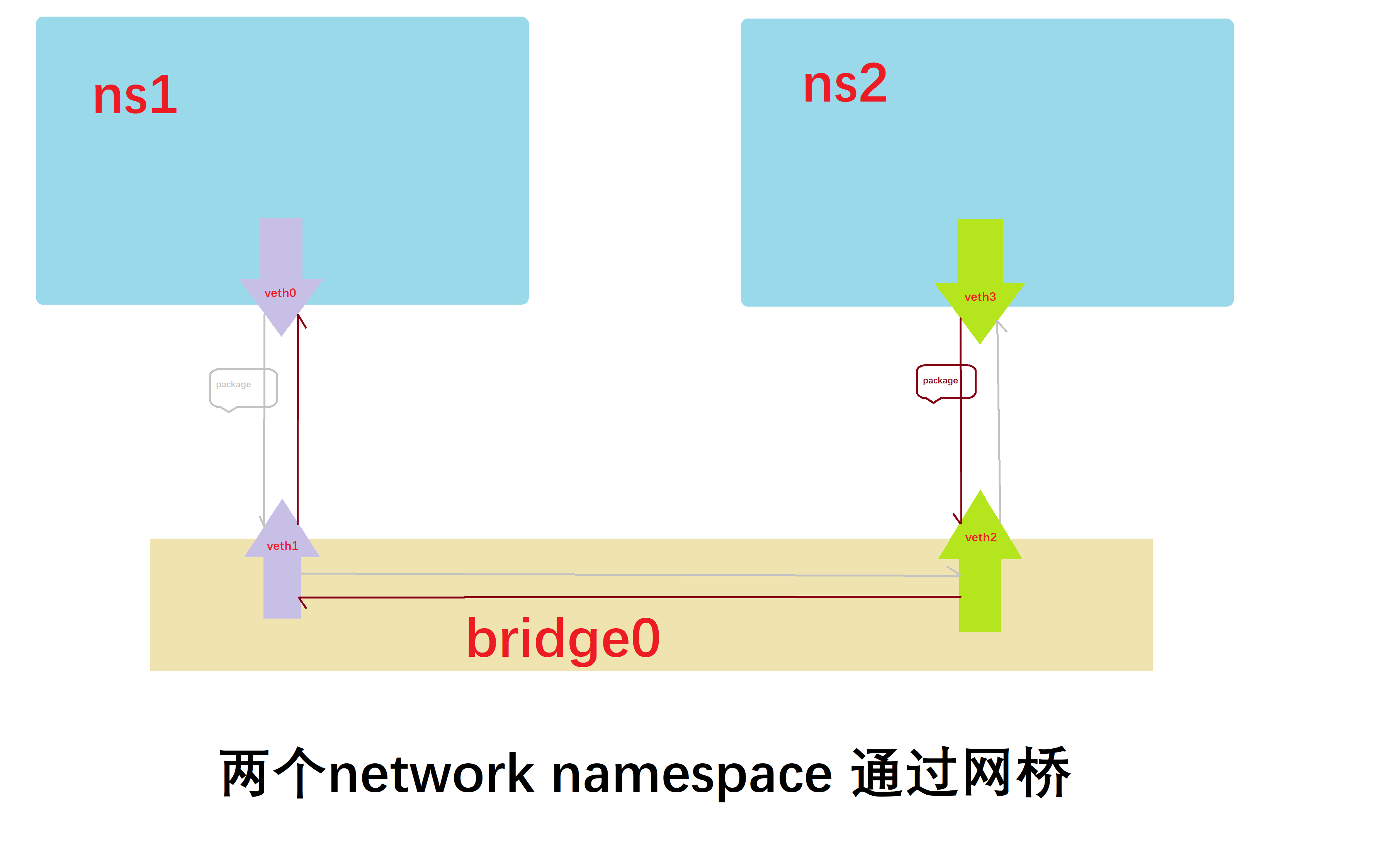
在这里我们初步的认识一下network namespace,可以方便我们学习docker网络,下面我们一起来认识一下docker的四大网络模型。
2、docker的网络模式
docker提供了包括bridge模式、host模式、container模式和none模式在内的四大网络模式,下面我们一起学习一下这四个网络模式。
2.1、bridge模式
当我们将docker安装好之后,docker会自动一个默认的网桥docker0,而bridge模式也是docker默认的网络模式,在不指定—network的前提下,会自动为每一个容器分配一个network namespace,并单独配置IP。我们可以在宿主机上更直观的看到这个现象
[root@docker1 ~]# ifconfig
docker0: flags=4099<up,broadcast,multicast> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:f7:b9:1b:10 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens32: flags=4163<up,broadcast,running,multicast> mtu 1500
inet 192.168.1.51 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::20c:29ff:fefc:3f5f prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:fc:3f:5f txqueuelen 1000 (Ethernet)
RX packets 145458 bytes 212051596 (202.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9782 bytes 817967 (798.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<up,loopback,running> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 8 bytes 684 (684.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 684 (684.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
我们可以看到,docker在宿主机上创建的网桥docker,其IP为172.17.0.1,而网桥则是桥接在了宿主机网卡ens33上面。下面我们将创建两个容器
[root@docker1 ~]# docker run -itd centos:7.2.1511
22db06123b51ad671e2545e5204dec5c40853f60cbe1784519d614fd54fee838
[root@docker1 ~]# docker run -itd centos:7.2.1511
f35b9d78e08f9c708c421913496cd1b0f37e7afd05a6619b2cd0997513d98885
[root@docker1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f35b9d78e08f centos:7.2.1511 "/bin/bash" 3 seconds ago Up 2 seconds tender_nightingale
22db06123b51 centos:7.2.1511 "/bin/bash" 4 seconds ago Up 3 seconds elastic_darwin
现在我们再查看一下网卡,又会有什么发现呢?
[root@docker1 ~]# ifconfig
docker0: flags=4163<up,broadcast,running,multicast> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:f7ff:feb9:1b10 prefixlen 64 scopeid 0x20<link>
ether 02:42:f7:b9:1b:10 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 648 (648.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens32: flags=4163<up,broadcast,running,multicast> mtu 1500
inet 192.168.1.51 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::20c:29ff:fefc:3f5f prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:fc:3f:5f txqueuelen 1000 (Ethernet)
RX packets 145565 bytes 212062634 (202.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 9839 bytes 828247 (808.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<up,loopback,running> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 8 bytes 684 (684.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 684 (684.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethe96ebe7: flags=4163<up,broadcast,running,multicast> mtu 1500
inet6 fe80::fcf9:fbff:fefb:db3b prefixlen 64 scopeid 0x20<link>
ether fe:f9:fb:fb:db:3b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 13 bytes 1038 (1.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethfdafaf4: flags=4163<up,broadcast,running,multicast> mtu 1500
inet6 fe80::1426:8eff:fe86:1dfb prefixlen 64 scopeid 0x20<link>
ether 16:26:8e:86:1d:fb txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 16 bytes 1296 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
我们可以清楚地看到这里多出来了两个网卡:vethe96ebe7和vethfdafaf4,同时每个容器内也创建了一个网卡设备ens3,而这就组成了bridge模式的虚拟网卡设备veth pair。veth pair会组成一个数据通道,而网桥docker0则充当了网关,可参考下图 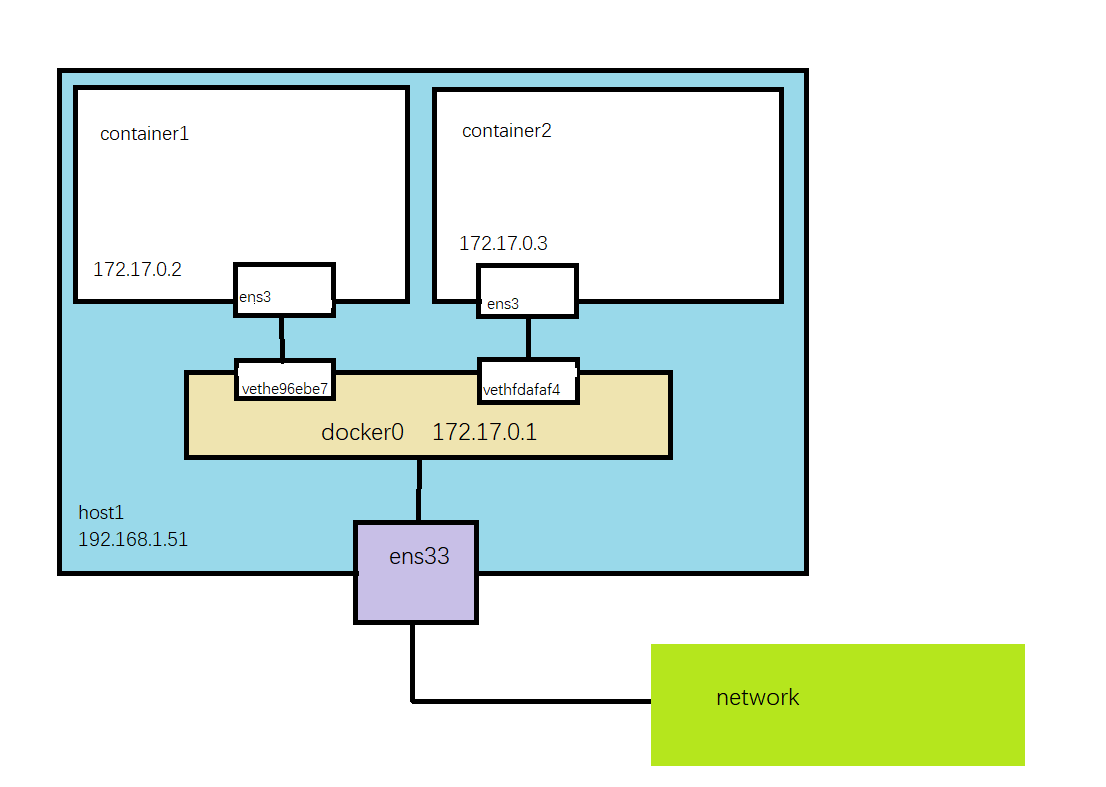 同一宿主机通过广播通信,跨主机则是通过docker0网关。
同一宿主机通过广播通信,跨主机则是通过docker0网关。
2.2、host模式
host模式是共享宿主机网络,使得容器和host的网络配置完全一样。我们先启动一个host模式的容器
[root@docker1 ~]# docker run -itd --network=host centos:7.2.1511
841b66477f9c1fc1cdbcd4377cc691db919f7e02565e03aa8367eb5b0357abeb
[root@docker1 ~]# ifconfig
docker0: flags=4099<up,broadcast,multicast> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:65ff:fead:8ecf prefixlen 64 scopeid 0x20<link>
ether 02:42:65:ad:8e:cf txqueuelen 0 (Ethernet)
RX packets 18 bytes 19764 (19.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 16 bytes 2845 (2.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens32: flags=4163<up,broadcast,running,multicast> mtu 1500
inet 192.168.1.51 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::20c:29ff:fefc:3f5f prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:fc:3f:5f txqueuelen 1000 (Ethernet)
RX packets 147550 bytes 212300608 (202.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 11002 bytes 1116344 (1.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<up,loopback,running> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 8 bytes 684 (684.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 684 (684.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
可以看到host模式下并未创建虚拟网卡设备,我们进入到容器内看一下
[root@docker1 /]# hostname -i fe80::20c:29ff:fefc:3f5f%ens32 fe80::42:65ff:fead:8ecf%docker0 192.168.1.51 172.17.0.1
我们可以很直观的看到容器内IP为宿主机IP,同时还有一个docker0的网关。我们可以通过下图更加直观的认识一下 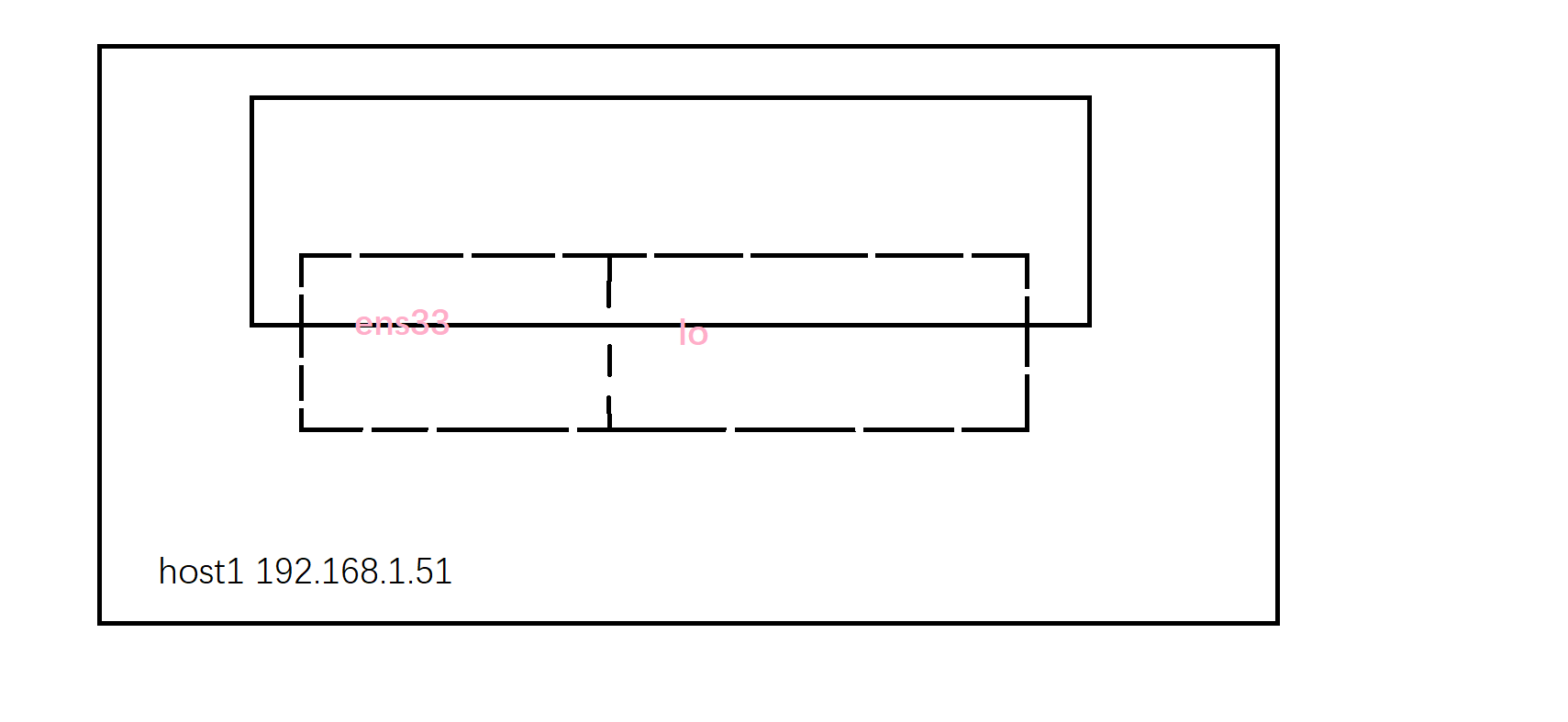 当然了,host模式很方便,但是也有很多的不足,这个后续会谈。
当然了,host模式很方便,但是也有很多的不足,这个后续会谈。
2.3、container模式
这个模式下,是将新创建的容器丢到一个已存在的容器的网络栈中,共享ip等网络资源,而两者通过lo回环进行通信,下面我们启动一个容器可以观察一下
[root@docker2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b7b201d3139f centos:7.2.1511 "/bin/bash" 28 minutes ago Up 27 minutes jovial_kepler
[root@docker2 ~]# docker run -itd --network=container:b7b201d3139f centos:7.2.1511
c4a6d59a971a7f5d92bfcc22de85853bfd36580bf08272de58cb70bc4898a5f0
[root@docker2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c4a6d59a971a centos:7.2.1511 "/bin/bash" 2 seconds ago Up 2 seconds confident_shockley
b7b201d3139f centos:7.2.1511 "/bin/bash" 28 minutes ago Up 28 minutes jovial_kepler
[root@docker2 ~]# ifconfig
docker0: flags=4163<up,broadcast,running,multicast> mtu 1500
inet 172.18.0.1 netmask 255.255.0.0 broadcast 172.18.255.255
inet6 fe80::42:8ff:feed:83e7 prefixlen 64 scopeid 0x20<link>
ether 02:42:08:ed:83:e7 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 648 (648.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens32: flags=4163<up,broadcast,running,multicast> mtu 1500
inet 192.168.1.52 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::20c:29ff:fe1b:1e63 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:1b:1e:63 txqueuelen 1000 (Ethernet)
RX packets 146713 bytes 212204228 (202.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10150 bytes 947975 (925.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<up,loopback,running> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 4 bytes 340 (340.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 340 (340.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
vethb360066: flags=4163<up,broadcast,running,multicast> mtu 1500
inet6 fe80::ca6:62ff:fe45:70e8 prefixlen 64 scopeid 0x20<link>
ether 0e:a6:62:45:70:e8 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 13 bytes 1038 (1.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
这里可以看到,两个容器,但是虚拟网卡只有一个,下面我们进入到容器内
[root@docker2 ~]# docker exec -it c4a6d59a971a bash [root@b7b201d3139f /]# hostname -i 172.18.0.3
可以清晰地看到,两个容器 是同一套网络资源
2.4、none
通过—network=node 可以创建一个隔离的namespace,但是没有进行任何配置。使用这一网络模式需要管理员对网络配置有自己独到的认识,根据需求配置网络栈即可。
通过对以上内容的学习,我们对docker网络有了初步的认识,下面我们将进行docker集群网络方案的学习。
二、进阶,深入理解docker集群网络方案
1、同宿主机外进行通信
一般来说,linux系统的ip_forward 已打开,同时 SNAT/MASQUERADE规则已创建后,都是可以进行对外通信的。主要是因为linux的转发依托于ip_forward,同时从容器网段出来的包都要经过一次MASQUERADE转发,来实现ip地址的替换。
同时也需要注意一下DNS和主机名的影响,其中
/etc/resolv/conf 在创建容器的时候,默认与宿主机的/etc/resolv.conf一致
/etc/hosts 中记载了容器自身的一些地址和名称
/etc/hostname 中记载的是容器的主机名
这三个文件在容器内修改是即时生效,但是重启后失效,所以在DNS上可以通过—dns=address来指定的,主机名同理。
2、集群网络方案——隧道方案
隧道方案,也就是overlay网络,适用于几乎所以有的网络基础架构,唯一的要求是主机之间的IP链接,但是由于二次封包,会导致性能的下降,同时定位问题也是很麻烦的。

若有收获,就点个赞吧
0 人点赞
