DOM文档对象模型
- DOM(Document Object Model)定义了访问和操作XML文档的标准方法,DOM把XML文档作为树结构来查看,能够通过DOM树来读写所有元素。
Dom4j
- Dom4j是一个易用的开源的库,用于解析XML。它应用于Java平台,具有性能优异、功能强大和极易使用的特点
- Dom4j将XML视为Document对象
- XML标签被Dom4j定义为Element对象
- 下载Dom4j.jar:链接
- 安装如下图所示
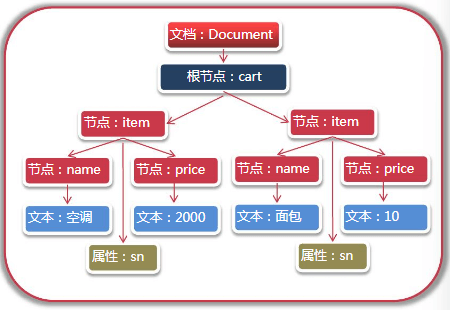
利用Dom4j遍历XML
package week11.dom4j;import java.util.List;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class HrReader {public void readXml(){String file = ".\\week11\\hr.xml";//SAXReader类是读取XML文件的核心类,用于将XML解析后以“树”的形式保存在内存中。SAXReader reader = new SAXReader();try {Document document = reader.read(file);//获取XML文档的根节点,即hr标签Element root = document.getRootElement();//elements方法用于获取指定的标签集合List<Element> employees = root.elements("employee");for(Element employee : employees){//element方法用于获取唯一的子节点对象Element name = employee.element("name");String empName = name.getText();//getText()方法用于获取标签文本System.out.println(empName);System.out.println(employee.elementText("age"));System.out.println(employee.elementText("salary"));Element department = employee.element("department");System.out.println(department.element("dname").getText());System.out.println(department.element("address").getText());Attribute att = employee.attribute("no");System.out.println(att.getText());}} catch (DocumentException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public static void main(String[] args) {HrReader reader = new HrReader();reader.readXml();}}
利用Dom4j更新XML
package week11.dom4j;import java.io.FileOutputStream;import java.io.OutputStreamWriter;import java.io.Writer;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class HrWriter {public void writeXml(){String file = ".\\week11\\hr.xml";SAXReader reader = new SAXReader();try {Document document = reader.read(file);Element root = document.getRootElement();Element employee = root.addElement("employee");employee.addAttribute("no", "3311");Element name = employee.addElement("name");name.setText("李铁柱");employee.addElement("age").setText("37");employee.addElement("salary").setText("3600");Element department = employee.addElement("department");department.addElement("dname").setText("人事部");department.addElement("address").setText("XX大厦-B105");Writer writer = new OutputStreamWriter(new FileOutputStream(file) , "UTF-8");document.write(writer);writer.close();} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}public static void main(String[] args) {HrWriter hrWriter = new HrWriter();hrWriter.writeXml();}}
XPath
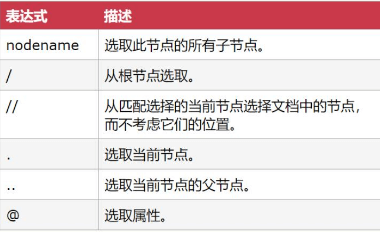
路径表达式
- XPath路径表达式是XML文档中查找数据的语言
- 掌握XPath可以极大可能的提高在提取数据时的开发效率
-
XPath基本表达式
Jaxen介绍
Jaxen是一个Java编写的开源的XPath库。可以适应多种不同对象的模型,如
- DOM
- XOM
- Dom4j
- JDOM
- Dom4j底层依赖Jaxen实现XPath查询
- Jaxen下载地址
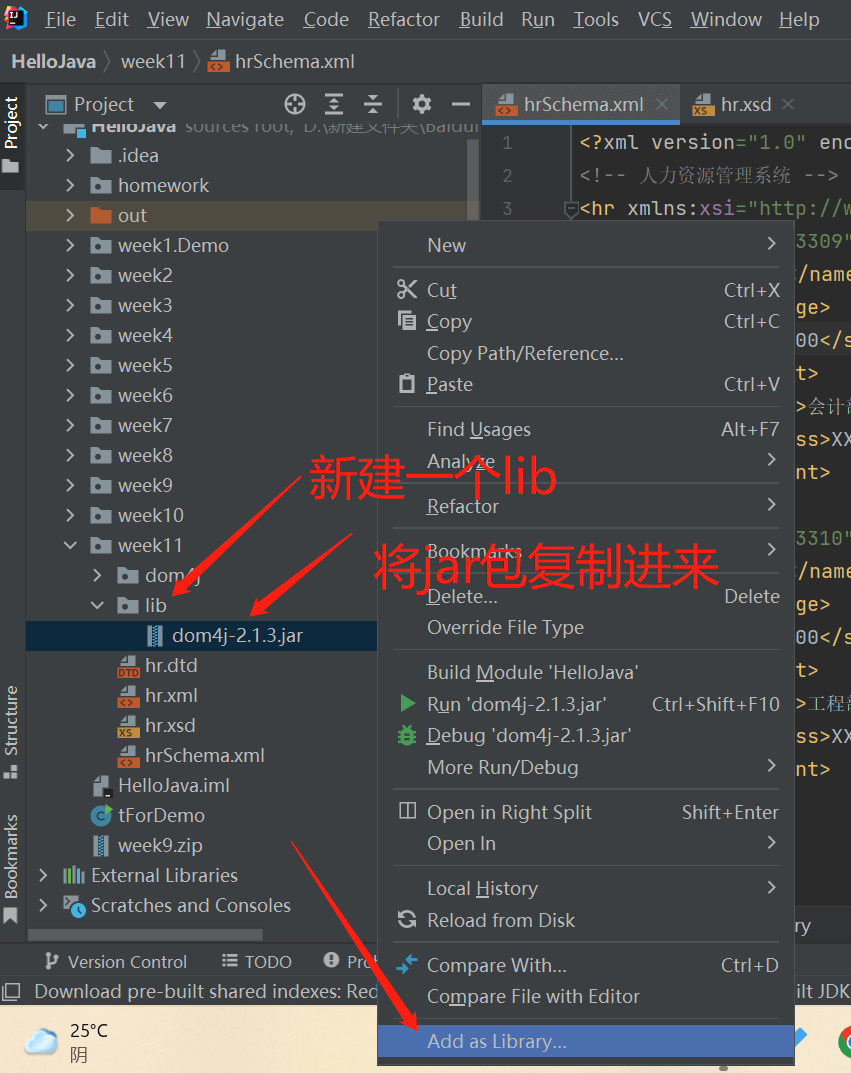
- 安装如下图所示

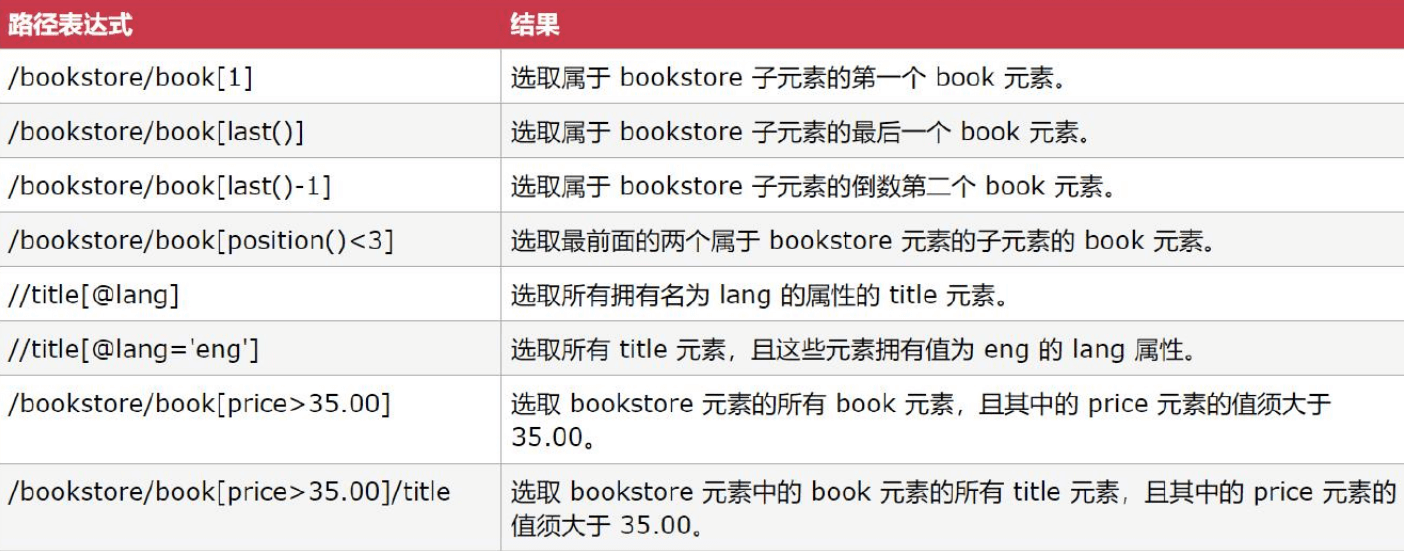
package week11.dom4j;import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.Node;import org.dom4j.io.SAXReader;public class XPathTestor {public void xpath(String xpathExp){String file = ".\\week11\\hr.xml";SAXReader reader = new SAXReader();try {Document document = reader.read(file);List<Node> nodes = document.selectNodes(xpathExp);for(Node node : nodes){Element emp = (Element)node;System.out.println(emp.attributeValue("no"));System.out.println(emp.elementText("name"));System.out.println(emp.elementText("age"));System.out.println(emp.elementText("salary"));System.out.println("==============================");}} catch (DocumentException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public static void main(String[] args) {XPathTestor testor = new XPathTestor();// testor.xpath("/hr/employee");// testor.xpath("//employee");// testor.xpath("//employee[salary<4000]");// testor.xpath("//employee[name='李铁柱']");// testor.xpath("//employee[@no=3304]");// testor.xpath("//employee[1]");// testor.xpath("//employee[last()]");//testor.xpath("//employee[position()<3]");testor.xpath("//employee[3] | //employee[8]");}}
编程练习一
使用Dom4j操作存储课程信息的plan.xml文件:

若有收获,就点个赞吧
0 人点赞
