1. 创建 DataFrame
#导入模块import pandas as pd# 新建DateFrame,格式为 字典,key为表头,value 是一个列表,为内容df = pd.DataFrame({'ID': [1, 2, 3], 'name': ['Tim', 'Victor', 'Nick']})print(df)
Excel显示结果,自动生成索引
如果指定 ID 为索引,需要使用。
df.set_index(‘ID’) 新建一个DataFrame
df.set_index(‘ID’, inplace=True) 不新建DateFrame,直接替换
df = df.set_index('ID')
Excel显示结果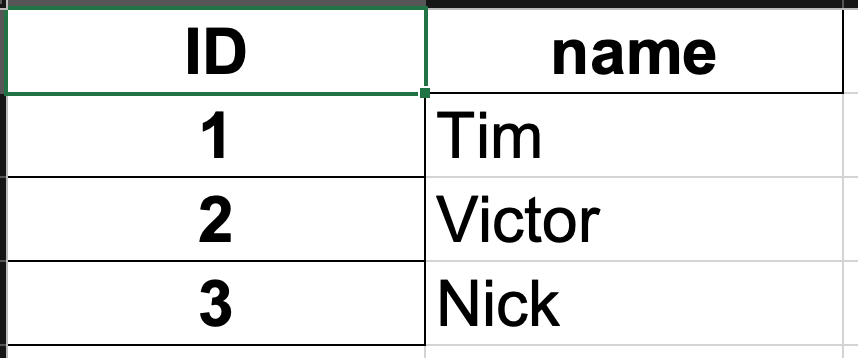
2.打开Excel
#导入模块import pandas as pd"""新建DateFrame1. skiprowes 可以在读取excel文件时跳过前面几行,usecols 可以指定读取列的范围。2. header 可以指定第一行,如果是空行,无需指定header。3. 如果没有表头,可以先使用 header = None,再使用 people.columns = ["id", "type"] 设定表头4. index_col='ID' 可以指定打开的Excel文件的index"""people = pd.read_excel('./test.xls', header=1)# 设定 indexpeople.set_index('序号', inplace=True)# 查看总行数,总列数print(people.shape)# 查看列名print(people.columns)# 查看头部,默认5行print(people.head(3))# 查看结尾,默认5行print(people.tail(3))# 保存文件people.to_excel('./1.xls')
3. 创建序列
- 创建序列 ``` import pandas as pd
创建字典
d = {‘x’: 100, ‘y’: 200, ‘z’: 300}
创建序列
s1 = pd.Series(d)
print(s1)
print(s1.index)
显示结果 x 100 y 200 z 300
dtype: int64
Index([‘x’, ‘y’, ‘z’], dtype=’object’)
- 序列组成DataFrame
L1 = [100, 200, 300] L2 = [‘x’, ‘y’, ‘z’]
s1 = pd.Series(L1, index=L2) s2 = pd.Series([100, 200, 300], index=[‘x’, ‘y’, ‘z’]) print(s1) print(s2)
显示结果 x 100 y 200 z 300 dtype: int64
- index 是序列的索引,组成Dataform的时候index 可以不对齐,index数值多少就到哪
import pandas as pd
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name=’A’) s2 = pd.Series([10, 20, 30], index=[2, 3, 4], name=’B’) s3 = pd.Series([100, 200, 300], index=[4, 5, 6], name=’C’)
以字典加入,序列为列,用的最多的方式
df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3}) print(df)
显示结果 A B C 1 1.0 NaN NaN 2 2.0 10.0 NaN 3 3.0 20.0 NaN 4 NaN 30.0 100.0 5 NaN NaN 200.0 6 NaN NaN 300.0
- 在组成DataFrame时,以字典加入,序列为列
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name=’A’) s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name=’B’) s3 = pd.Series([100, 200, 300], index=[1, 2, 3], name=’C’)
以字典加入,序列为列,用的最多的方式
df = pd.DataFrame({s1.name:s1,s2.name:s2,s3.name:s3}) print(df)
显示结果 A B C 1 1 10 100 2 2 20 200 3 3 30 300
- 在组成DataFrame时,以列表加入,序列为行
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name=’A’) s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name=’B’) s3 = pd.Series([100, 200, 300], index=[1, 2, 3], name=’C’)
以列表加入,序列为行
df2 = pd.DataFrame([s1, s2, s3]) print(df2)
显示结果 1 2 3 A 1 2 3 B 10 20 30 C 100 200 300 ```

若有收获,就点个赞吧
0 人点赞
