行操作
代码1 : append ,drop ,loc 等应用
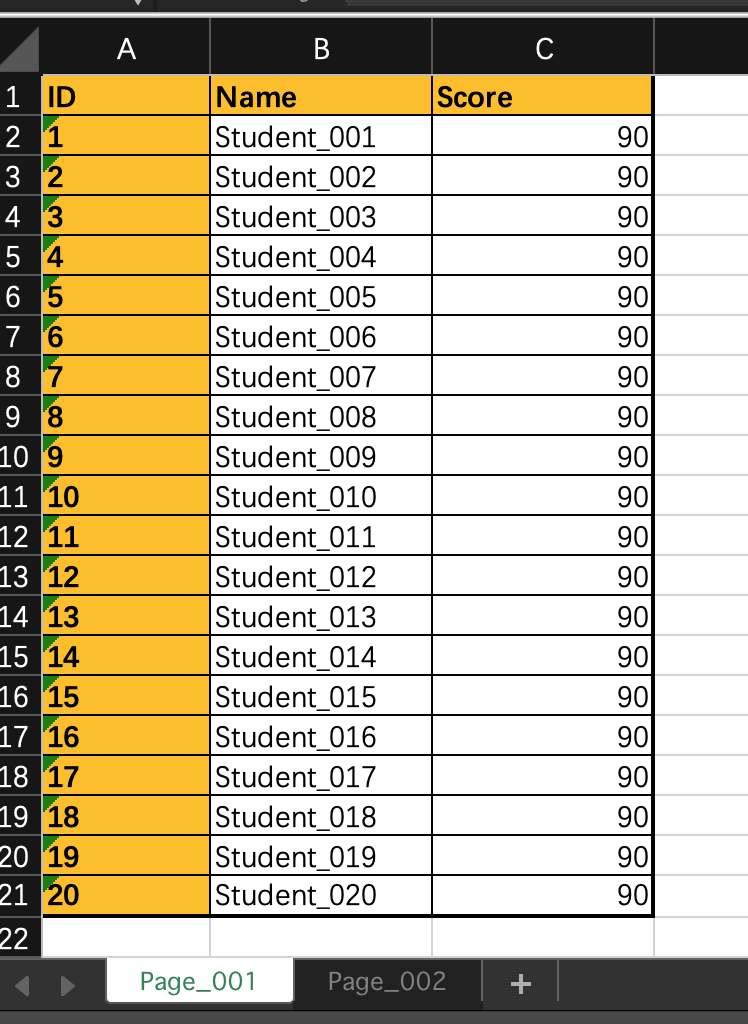
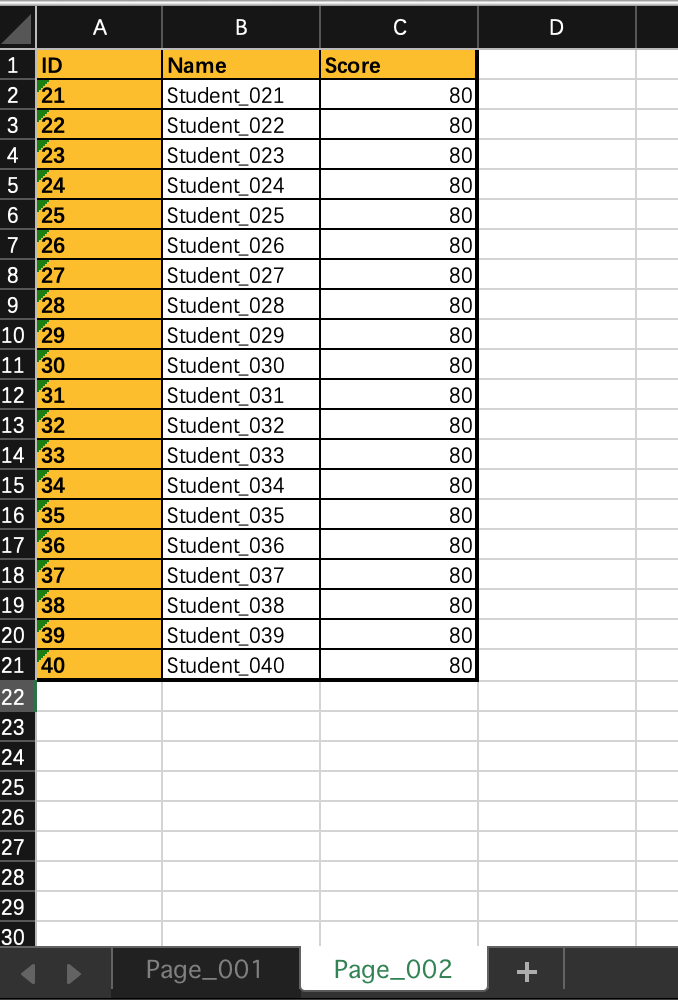
import pandas as pdpage_001 = pd.read_excel('./Students.xlsx', sheet_name='Page_001')page_002 = pd.read_excel('./Students.xlsx', sheet_name='Page_002')"""append 可以追加一个DateFramereset_index(drop=True),可以重新生成一个index,但是原有的index依然在,加上drop=True后"""students = page_001.append(page_002).reset_index(drop=True)# 增加一行 ,如果不使用ignore_index=True,加入的Series会找不到index,报错stu = pd.Series({'ID': 41, 'Name': 'Abel', "Score": 99})students = students.append(stu, ignore_index=True)# 单元格修改数值students.at[39, 'Name'] = 'Bailey'students.at[39, 'Score'] = '900'# 整行替换stu2 = pd.Series({'ID': 31, 'Name': 'nzl5423', 'Score': 88})students.iloc[30] = stu2# 插入一行stu3 = pd.Series({'ID': 101, 'Name': 'wyy', 'Score': 88})part1 = students[:20]part2 = students[20:]"""插入一行的操作是先将DateFrame 切片,通过append方法 把part1、stu3、part2 连接起来就可以了新插进来的Series没有index ,所以要使用ignore_index=True,否则报错将后面的DateFrame接上来后,因为这部分已经有index了,只需要reset_index(drop=True),但是原有的index依然在,加上drop=True后"""students = part1.append(stu3, ignore_index=True).append(part2).reset_index(drop=True)# 删除数据行# students.drop(index=[0, 1, 2], inplace=True)# students.drop(index=range(0,10),inplace=True)# students.drop(students[0:10].index, inplace=True)# 按条件删除行for i in range(5, 15):students['Name'].at[i] = ''missing = students.loc[students['Name'] == '']students.drop(index=missing.index, inplace=True)students.reset_index(drop=True) # 为新的DataFrame 生成新的 indexprint(students)"""结果显示ID Name Score0 1 Student_001 901 2 Student_002 902 3 Student_003 903 4 Student_004 904 5 Student_005 9015 16 Student_016 9016 17 Student_017 9017 18 Student_018 9018 19 Student_019 9019 20 Student_020 9020 101 wyy 8821 21 Student_021 8022 22 Student_022 8023 23 Student_023 8024 24 Student_024 8025 25 Student_025 8026 26 Student_026 8027 27 Student_027 8028 28 Student_028 8029 29 Student_029 8030 30 Student_030 8031 31 nzl5423 8832 32 Student_032 8033 33 Student_033 8034 34 Student_034 8035 35 Student_035 8036 36 Student_036 8037 37 Student_037 8038 38 Student_038 8039 39 Student_039 8040 40 Bailey 90041 41 Abel 99Process finished with exit code 0"""
代码2 concat 应用
import pandas as pdpage_001 = pd.read_excel('./Students.xlsx', sheet_name='Page_001')page_002 = pd.read_excel('./Students.xlsx', sheet_name='Page_002')"""concat 可以追加一个DateFrame, axis=0为添加行,axis=1为纵向添加,concat后面添加 .reset_index(drop=True)可以重设index但是原有的index依然在,加上drop=True后"""# students = pd.concat([page_001, page_002],axis=1).reset_index(drop=True)students = pd.concat([page_001, page_002], axis=0).reset_index(drop=True)# students.reset_index(drop=True) # 为新的DataFrame 生成新的 indexprint(students)
列操作
import pandas as pdimport numpy as nppage_001 = pd.read_excel('./Students.xlsx', sheet_name='Page_001')page_002 = pd.read_excel('./Students.xlsx', sheet_name='Page_002')"""concat 可以追加一个DateFrame, axis=0为添加行,axis=1为纵向添加,concat后面添加 .reset_index(drop=True)可以重设index但是原有的index依然在,加上drop=True后"""# students = pd.concat([page_001, page_002],axis=1).reset_index(drop=True)students = pd.concat([page_001, page_002], axis=0).reset_index(drop=True)# 增加列# students['Age'] = 18# 所有数字都等于18# students['Age'] = np.repeat(20, len(students))# numpy方法 所有都等于20students['Age'] = np.arange(0, len(students))# numpy方法生成序列 0—len(students)# 删除列students.drop(columns=['Score', 'Age'], inplace=True)# 插入列 插入位置 插入的列名 插入的值 ,插入列默认 inplace=True,不用写students.insert(1, column='Foo', value=np.repeat('foo', len(students)))# 修改列名students.rename(columns={'Foo': 'FOO', 'Nmae': 'NAME'}, inplace=True)# 删除空值# 只有float才可以有空值 not number,即 NaN,所以先转化为float类型students['ID'] = students['ID'].astype(float)for i in range(5, 14):# np.nan 即为 not number, NaNstudents['ID'].at[i] = np.nan# .dropna 方法从上到下扫描每一行,一旦行中有 NaN,即删除整行students.dropna(inplace=True)# students.reset_index(drop=True) # 为新的DataFrame 生成新的 indexprint(students)"""结果显示ID FOO Name0 1.0 foo Student_0011 2.0 foo Student_0022 3.0 foo Student_0033 4.0 foo Student_0044 5.0 foo Student_00514 15.0 foo Student_01515 16.0 foo Student_01616 17.0 foo Student_01717 18.0 foo Student_01818 19.0 foo Student_01919 20.0 foo Student_02020 21.0 foo Student_02121 22.0 foo Student_02222 23.0 foo Student_02323 24.0 foo Student_02424 25.0 foo Student_02525 26.0 foo Student_02626 27.0 foo Student_02727 28.0 foo Student_02828 29.0 foo Student_02929 30.0 foo Student_03030 31.0 foo Student_03131 32.0 foo Student_03232 33.0 foo Student_03333 34.0 foo Student_03434 35.0 foo Student_03535 36.0 foo Student_03636 37.0 foo Student_03737 38.0 foo Student_03838 39.0 foo Student_03939 40.0 foo Student_040Process finished with exit code 0"""

若有收获,就点个赞吧
0 人点赞
