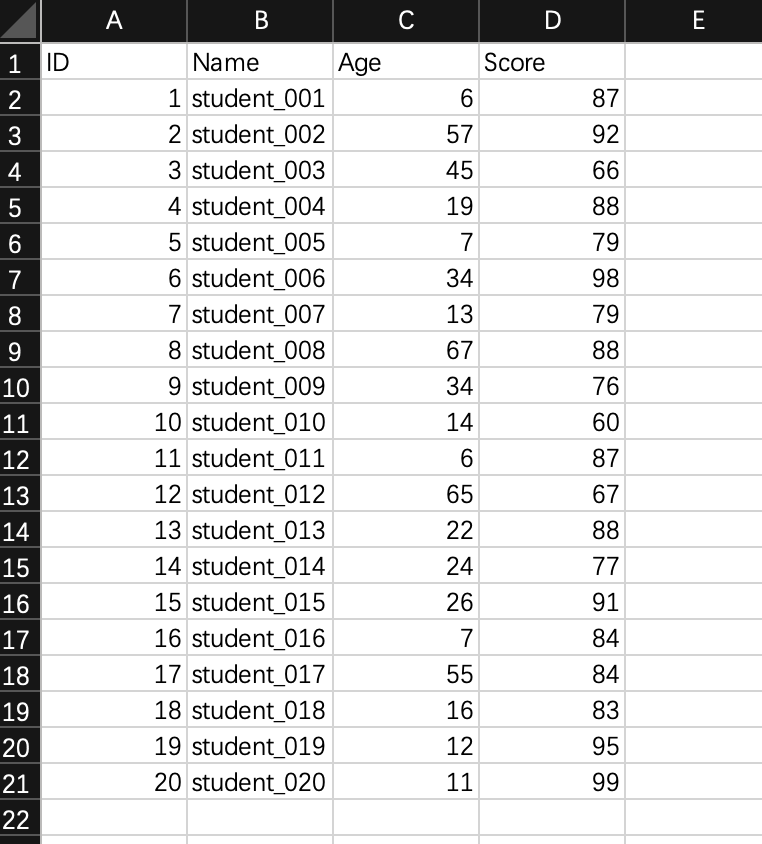
要求: 筛选 年龄在 18—30之间,成绩在85-100之间的学生
代码一
import pandas as pddef age_18_to_30(a):# return a >= 18 and a< 30return 18 <= a < 30def score_85_to_100(s):return 85 <= s <= 100student = pd.read_excel('./score.xlsx', index_col='ID')# 连用两次 .loc 筛选数据 ,注意 .loc[],后面是方括号# 连用两次 applystudent = student.loc[student['Age'].apply(age_18_to_30)].loc[student['Score'].apply(score_85_to_100)]print(student)
代码二
import pandas as pdstudent = pd.read_excel('./score.xlsx', index_col='ID')# 可以用 lambds 表达式代替函数 ,student['Age'] 与 student.Age 意义一样# 长代码换行可以用 "空格+\"student = student.loc[student['Age'].apply(lambda a: 18 <= a < 30)].loc[student['Score'].apply(lambda s: 85 <= s <= 100)]student = student.loc[student.Age.apply(lambda a: 18 <= a < 30)] \.loc[student.Score.apply(lambda s: 85 <= s <= 100)]print(student)
loc iloc用法
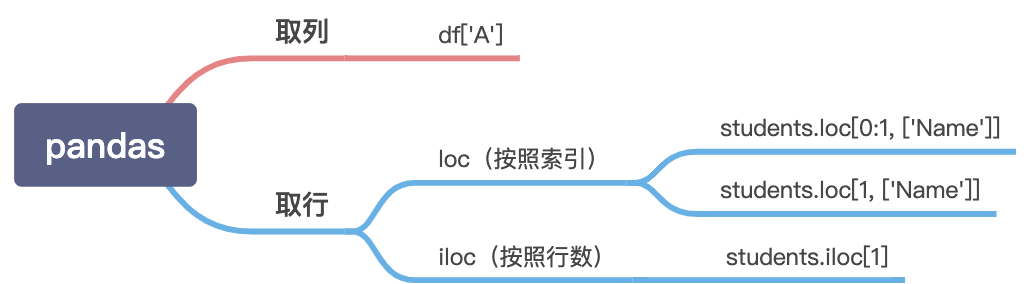 pandas以类似字典的方式来获取某一列的值,比如df[‘A’],这会得到df的A列。如果我们对某一行感兴趣呢?这个时候有两种方法,一种是iloc方法,另一种方法是loc方法。loc是指location的意思,iloc中的i是指integer。这两者的区别如下:
pandas以类似字典的方式来获取某一列的值,比如df[‘A’],这会得到df的A列。如果我们对某一行感兴趣呢?这个时候有两种方法,一种是iloc方法,另一种方法是loc方法。loc是指location的意思,iloc中的i是指integer。这两者的区别如下:
loc:works on labels in the index.
iloc:works on the positions in the index (so it only takes integers).
也就是说loc是根据index来索引,比如下边的df定义了一个index,那么loc就根据这个index来索引对应的行。iloc并不是根据index来索引,而是根据行号来索引,行号从0开始,逐次加1。
# loc:注意loc方法1:4包含第4students.loc[1, ['Name']] # 筛选index标签为 1 的 'Name'列students.loc[1:4, ['Name']] # 筛选index标签为 1到4 'Name'列students.loc[1:4, ['Name', 'ID']] # index标签为 1到4 'Name'列和'ID'列print(students.loc[[1, 3, 5], ['Name', 'ID']]) # 筛选index标签为 1、3、5 'Name'列和'ID'列# iloc:注意iloc方法1:4不包含第4students.iloc[1] # 筛选第一行students.iloc[1, 1] # 筛选第一行第一位students.iloc[1:5, 1] # 筛选第一行到第四行,第一位students.iloc[1:5, 1:7] # 筛选第一行到第四行,第一位到第六位students.iloc[[1, 3, 5], 1:7] # 筛选第一、三、五行,第一位到第六位

若有收获,就点个赞吧
0 人点赞
