Zookeeper
Zookeeper
Zookeeper是一个主从集群
存在一个leader主,它可以写操作,其他机器只能读,但是也就存在主单点故障问题
主单点故障问题
会快速(200MS以内)从追随者中重新选举一个新的leader出来。
角色
- leader
- follower
-
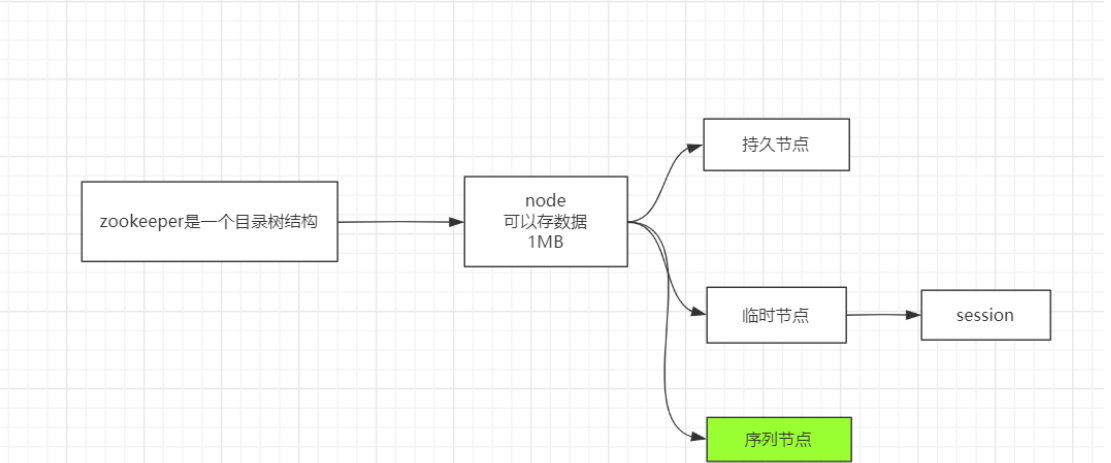
Zookeeper的文件结构
zookeeper是一个目录树结构
每个Node都只有1MB的大小 持久节点
- 持久序列节点
- 临时节点
- 属于当前会话,连接断开,节点被删除
- 临时节点无法创建子节点
- 临时序列节点
Zookeeper的保证
ZooKeeper 非常快速且非常简单。但是,由于它的目标是成为构建更复杂服务(例如同步)的基础,因此它提供了一组保证。这些是:
顺序一致性 - 来自客户端的更新将按发送顺序应用。
原子性 - 更新要么成功要么失败。没有部分结果。
单一系统映像 - 无论连接到哪个服务器,客户端都将看到相同的服务列表视图。
可靠性(持久化) - 应用更新后,它将从那时起一直存在,直到客户端覆盖更新。
及时性(最终一致性) - 系统的客户视图保证在特定时间范围内是最新的。
zookeeper
- tickTime=2000 每次心跳的毫秒间隔
- initLimit=10 最多可以忍追随者10次没有心跳
- sysncLimit = 5 leader发送了同步请求最多忍5次心跳的时间没有回复
- dataDir=/var/mashibing/zk 持久化目录
-
SessionID
一个客户端连接服务器,会在服务器端生成一个SessionID
创建的临时节点属于该会话。断开会被删除zookeeper命令
create [-s][-e] 创建一个节点,默认是持久节点。-s为序列节点,后面会跟一个序号,-e为临时节点
节点状态(包含事务ID)

每个节点下面都会保存事务IDcZxid:0x180000001e 创建的事务ID
- mZxid :0x180000001e 修改的事务ID
- pZxid :0x180000001e 子节点最后一次被修改的事务ID
每个create会使得三个ID加一
每个set会使得mZxid加一
新建sessionid和删除也会消耗一个事务ID
需要三个及以上节点
1).zookeeper集群的写操作,由leader节点负责,它会把通知所有节进行写入操作,只有收到半数以上节点的成功反馈,才算成功。如果是部署2个节点的话,那就必须都成功。
2).zookeeper的选举策略也是需要半数以上的节点同意才能当选leader,如果是偶数节点可能导致票数相同的情况
3).只有当半数以上的节点存活时 zookeeper集群才能对外服务,维持正常状态,如果是2个节点,只要其中一个挂掉,那么剩下的1个并不满足半数以上规则。
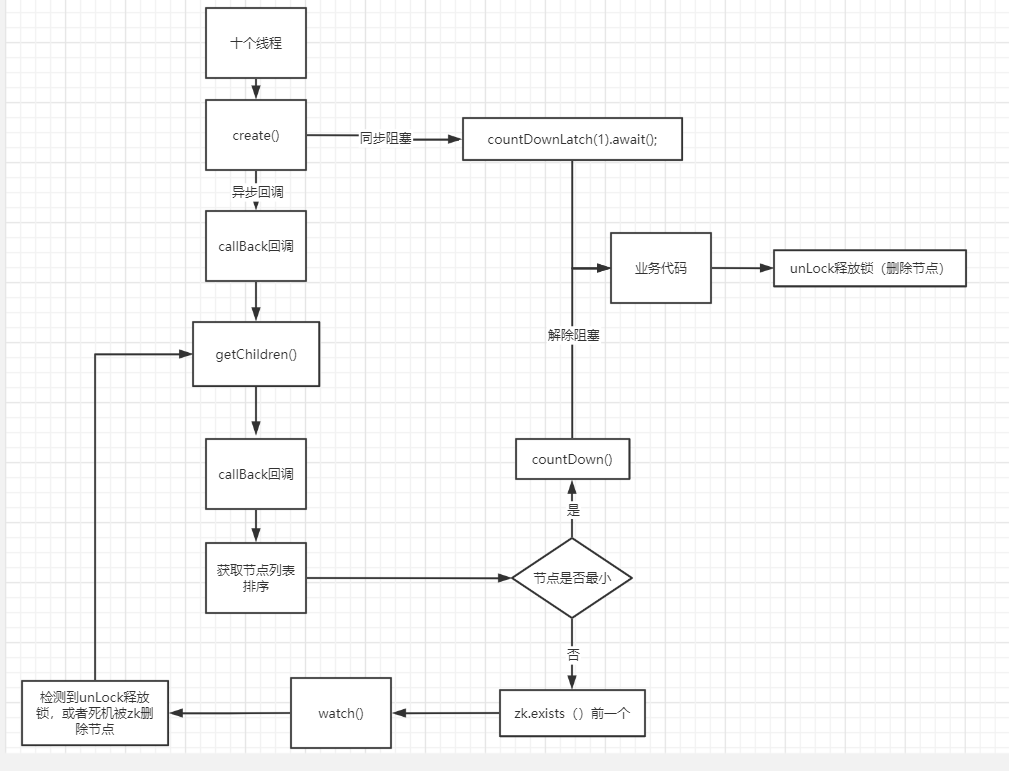
利用Zookeeper实现分布式锁
因为临时节点session删除也会被删除,所以不会出现因为单点故障出现的死锁
以下为两种实现锁的方式
- 临时节点作为锁,监控临时节点是否存在
- 序列临时节点作为锁,可以实现队列式的锁。
安装过程
安装笔记:
准备 node01~node04
1,安装jdk,并设置javahome
, node01:
2,下载zookeeper zookeeper.apache.org
3,tar xf zookeeper..tar.gz
4,mkdir /opt/mashibing
5, mv zookeeper /opt/mashibing
6,vi /etc/profile
export ZOOKEEPERHOME=/opt/mashibing/zookeeper-3.4.6
export PATH=_PATH:ZOOKEEPER_HOME/bin
7,cd zookeeper/conf
8,cp zoo.sem*.cfg zoo.cfg
9,vi zoo.cfg
dataDir=
server.1=node01:2888:3888
10, mkdir -p /var/mashibing/zk
11,echo 1 > /var/mashibing/zk/myid
12,cd /opt && scp -r ./mashibing/ node02:pwd
13:node02~node04 创建 myid
14:启动顺序 1,2,3,4
15:zkServer.sh start-foreground
zkCli.sh
help
ls /
create /ooxx “”
create -s /abc/aaa
create -e /ooxx/xxoo
create -s -e /ooxx/xoxo
get /ooxx
netstat -natp | egrep ‘(2888|3888)’ZAB 原子广播协议
原子:成功、失败。没有中间状态
广播:分布式多节点,过半通过
zk的数据状态在内存
用磁盘保存日志,
广播的修改命令会先放在log中,leader发现过半之后才会重新发送write内存的操作paxos 算法
选举投票,过半通过
投票的时候先比较事务xid,再比较idzk的watch
观察者模式
提供了对某一个节点的监听
可以把监听器作为回调函数传到watch等到传回事件java api
ZooKeeper zk = newZooKeeper("192.168.150.11:2181,192.168.150.12:2181,192.168.150.13:2181,192.168.150.14:2181",String pathName = zk.create("/ooxx", "olddata".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);final Stat stat=new Stat();byte[] node = zk.getData("/ooxx", new Watcher() {@Overridepublic void process(WatchedEvent event) {System.out.println("getData watch: "+event.toString());try {//true default Watch 被重新注册 new zk的那个watchzk.getData("/ooxx",this ,stat);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}}, stat);
zookeeper实现的分布式锁

若有收获,就点个赞吧
0 人点赞
