倒排索引的算法和数据结构
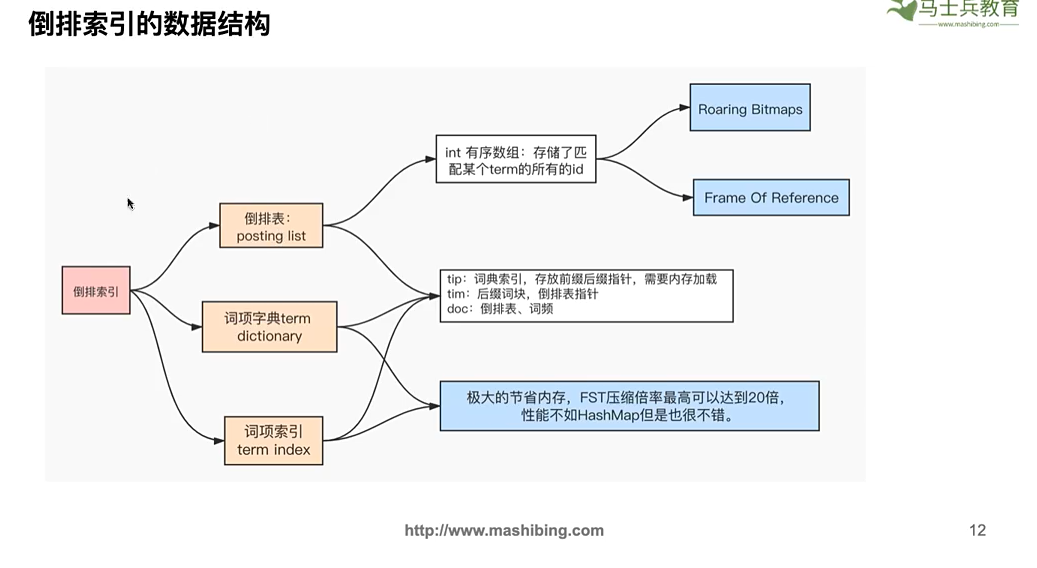
倒排索引的数据结构
- 倒排表posting list:存储词项匹配的id和词频 ,int数组
- 词项字典term dictionary:文本分割出来的词项
- 词项索引term index:加快词项的检索速度
其中的文件存储
data文件下
- doc:倒排表、词频
- tim:后缀词块,倒排表指针
- tip:词项索引,存放的前缀后缀指针,需要内存加载
数据结构对应的压缩算法
- 倒排表的压缩,int数组太大的压缩
- Roaring bitmaps(RBM)
- Frame of Reference(FOR)
- 池项和词项索引使用的压缩算法
- FST
压缩算法
Frame of Reference(FOR)倒排表压缩算法
适用于比较稠密的数组
倒排表的压缩算法,以一百万数据量的不重复、有序的int数组为例。
100W个int是400W字节 大概是4MB,我们需要压缩来节省磁盘空间,加快检索速率
FOR压缩在存储这样的不重复递增数组的时候,存的不是数字本身,存与前一位的差值。组成差值列表(deltas list)并且差值列表中存的并不是int,而是根据数值的大小存1bit到31bit大小的数据。例如差值全是1的数组,那么差值列表存的都是1bit,因为1这个数一个bit就可以表示。这样400W字节(3200W bit)的数据变成了100W bit的数据。压缩了32倍。
以上是最优的情况,等差列表值需要拆成一个数组,大多数情况下都需要拆成多个数组
实际情况运算形成的等差列表,差值不稳定,如果每个数字都拆分,那么算法会给每个数字数组分配1byte来存储当前数组的实际长度,浪费空间,编解码速度也会变慢,所以最后等差列表拆分成多少个数组是动态运算取的。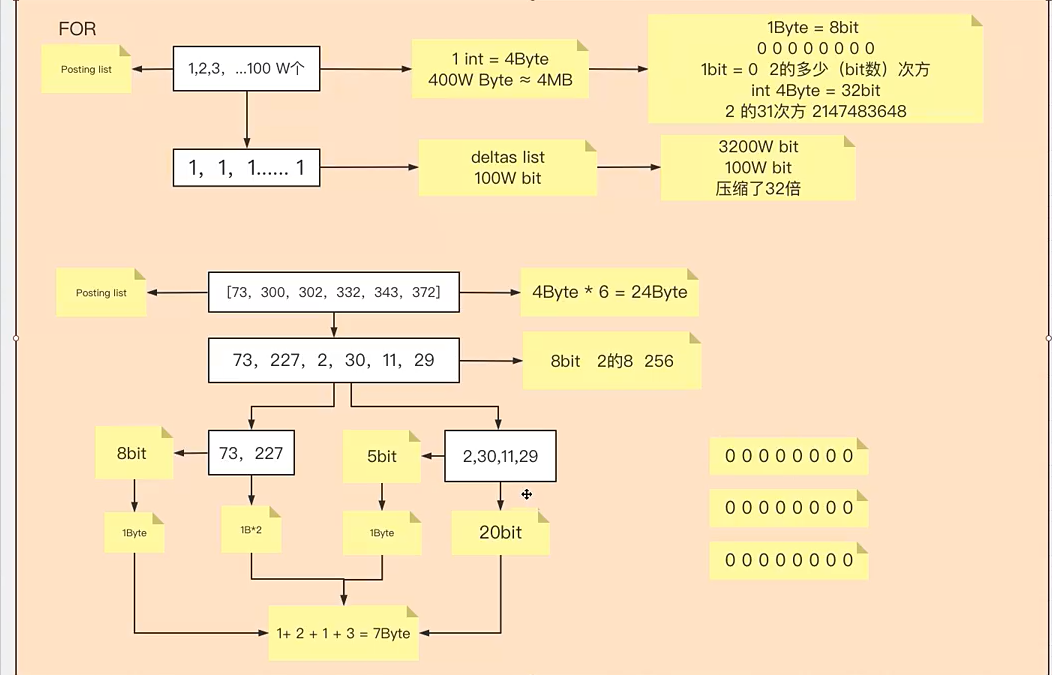
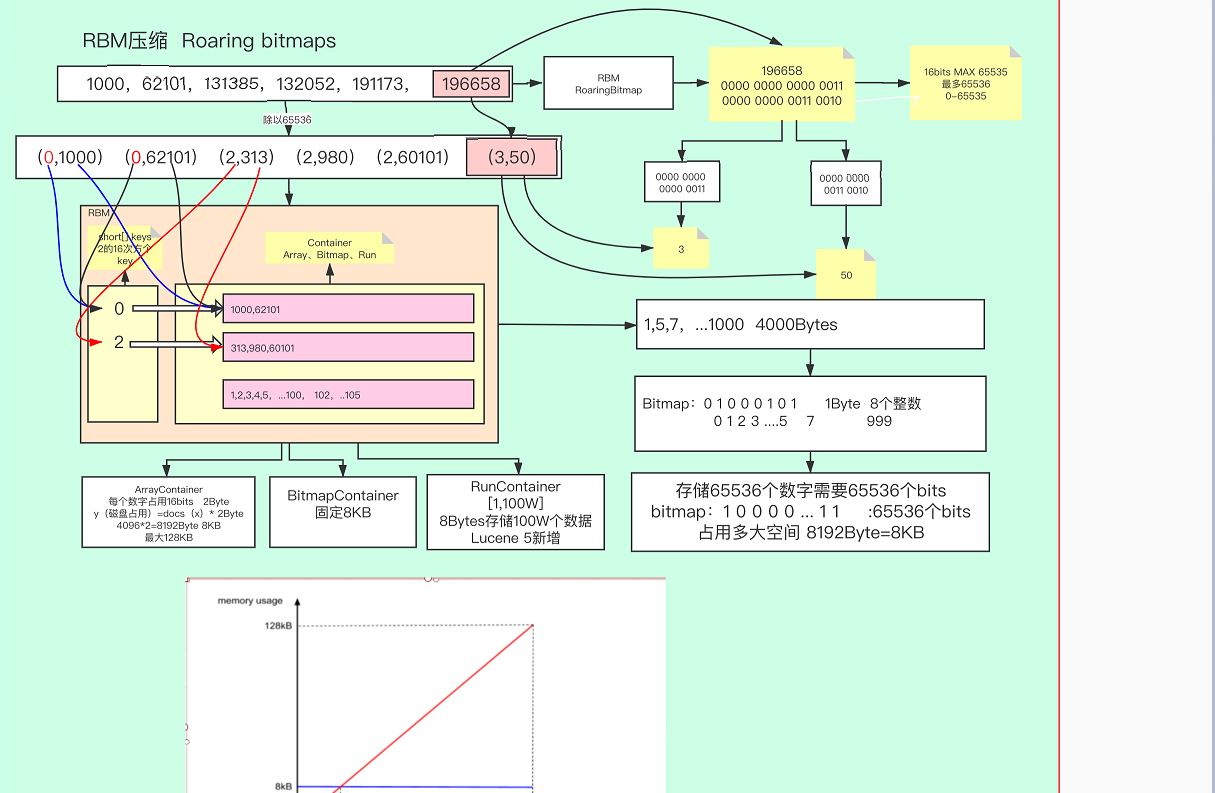
Roaring Bitmap(BMP)倒排表压缩算法
适用于比较稀疏的数组
当遇到稀疏的数组,差值变化较大,解决办法是数组的每一元素求65536的整数商和余数,由此可以得到int的高16位和低16位,高16位key用short 存储,每一个kEY都会对应很多低16位的value。此时的values有三种container存储,分别为ArrayComtainer、bitmapContainer、runContainer。
ArrayContainer是采用short数组来存储
bitmapContainer最大可以使用65536长度的位图来存储。这两个存储方式的性能交叉点是8kb
runContainer使用与连续的数组。只存头尾的数。
Trie前缀树/字典树(词项和词项索引使用的压缩算法)
字典树是以复用前缀的方式压缩。根节点以后单词每个字母占用树上的一个路径,最后一个单词是final节点,查找也是找到final才算查找完成。新的单词插入时,前缀相同复用,遇到不同的单词时候开启新的分支,并到新的final结束。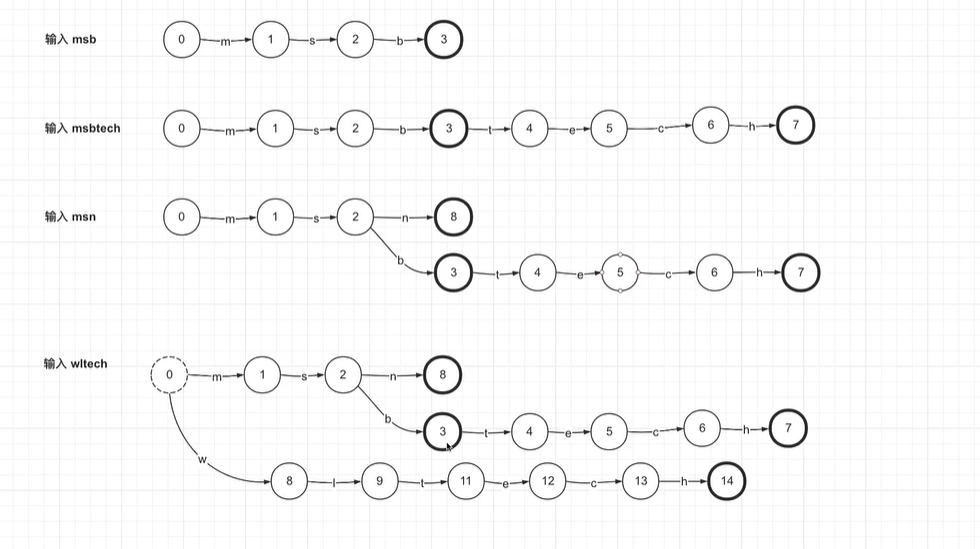
FST (词项和词项索引使用的压缩算法)
FSM(Finite State Machines)有限状态机
- 状态是有限的,
- 同一时间只能处于同一种状态
- 不同状态可以互相转换
- 状态是无序的
FSA:有限状态接收机
- 确定性:在任何给定的状态下,对于任何的输入,最到只能遍历到一个transition。
- 非循环:不能重复遍历同一个状态
- 末尾为最终状态时,才接受特定的输入序列。
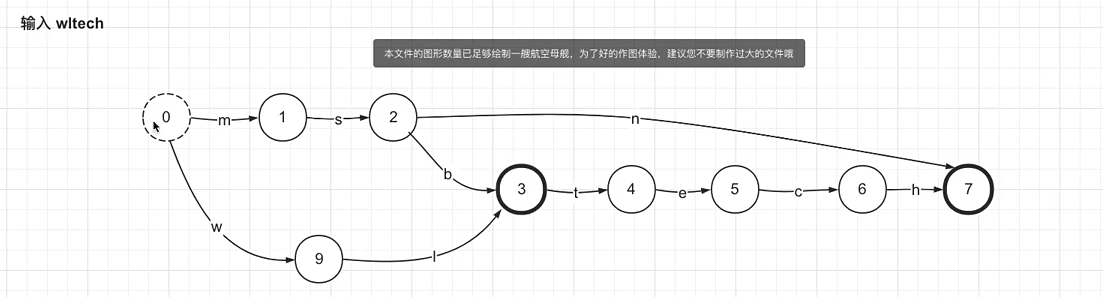
但是会多wl这个原本不存在的词项,
FST:有限状态转换机
路径上不止有字母还有对应的output数值,final节点会有额外的output的值,当output值相加等于词项的value值的时候。根据value严格匹配避免前后缀匹配的时候出现不存在的词项


若有收获,就点个赞吧
0 人点赞
