上机要求:
- 以k-mean算法为例,介绍聚类分析算法的原理及流程。
- 利用k-mean算法,编程对鸢尾花进行聚类,可以使用任务1中经过数据预处理的数据集iris.csv也可以直接使用sklearn中内置的已经预处理好的数据集。
- 使用数据可视化的方法对聚类结果进行输出,与真值的可视化结果进行对比。
- 与真值数据对比,计算聚类的准确率。
注:
- iris数据本身包含每类花型的数据,但在做聚类分析的时候应忽略类型这一列的数据。
- k-means算法需手动指定聚为几类,本例当中应为3类。有余力的同学也可尝试选用不同数量的参数或选用不同的数据集观察聚类结果。
可视化参考结果如下: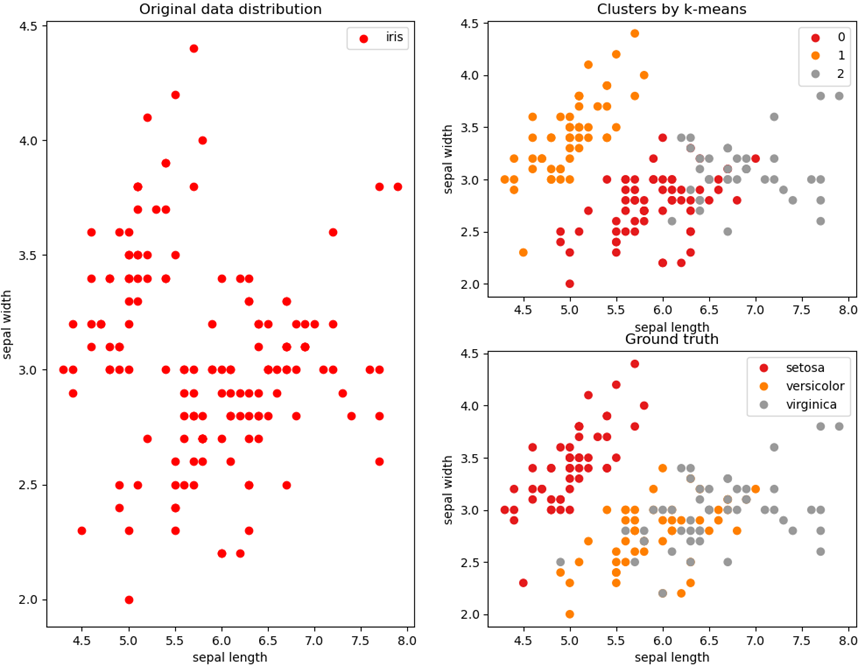
上机实现:
K-means进行聚类分析
导入需要的用到的包
import matplotlib.pyplot as pltimport numpy as npfrom sklearn.cluster import KMeans#from sklearn import datasetsfrom sklearn.datasets import load_iris
导入必要的数据集
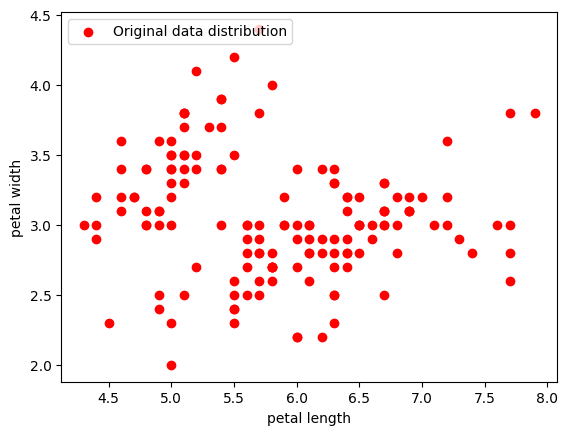
iris = load_iris()X = iris.data[:] ##表示我们只取特征空间中的后两个维度#绘制数据分布图plt.scatter(X[:, 0], X[:, 1], c = "red", marker='o', label='see')plt.xlabel('petal length')plt.ylabel('petal width')plt.legend(loc=2)plt.show()
K-means进行数据集的聚类分析
绘制 k-means 结果
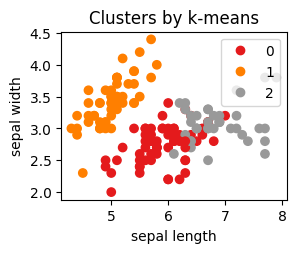
# 执行 k-means 聚类estimator = KMeans(n_clusters=3) # 构造聚类器estimator.fit(iris.data) # 执行聚类# 注:如果此处载入的数据源为 csv,需注意不要把第五列,即真实类别带入聚类执行器# 绘制 k-means 结果plt.subplot(2, 2, 2)s = plt.scatter(iris.data[:, 0], iris.data[:, 1], c=estimator.labels_, cmap=plt.cm.Set1)plt.xlabel('sepal length')plt.ylabel('sepal width')plt.legend(handles=s.legend_elements()[0], labels=[0, 1, 2], loc=1)plt.title("Clusters by k-means")
绘制原始类别真值
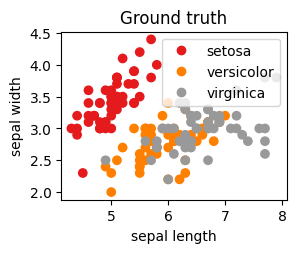
# 绘制原始类别真值plt.subplot(2, 2, 4)s = plt.scatter(iris.data[:, 0], iris.data[:, 1], c=iris.target, cmap=plt.cm.Set1)plt.xlabel('sepal length')plt.ylabel('sepal width')plt.legend(handles=s.legend_elements()[0], labels=iris.target_names.tolist(), loc=1)plt.title("Ground truth")# 显示结果plt.show()
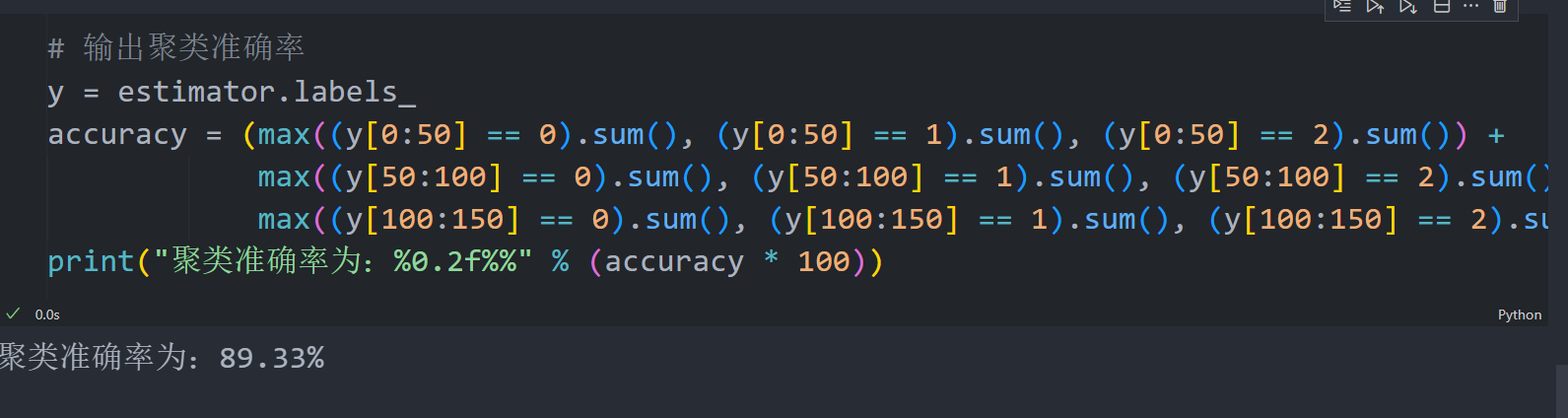
输出聚类准确率
# 输出聚类准确率y = estimator.labels_accuracy = (max((y[0:50] == 0).sum(), (y[0:50] == 1).sum(), (y[0:50] == 2).sum()) +max((y[50:100] == 0).sum(), (y[50:100] == 1).sum(), (y[50:100] == 2).sum()) +max((y[100:150] == 0).sum(), (y[100:150] == 1).sum(), (y[100:150] == 2).sum())) / 150print("聚类准确率为:%0.2f%%" % (accuracy * 100))

若有收获,就点个赞吧
0 人点赞
