实验要求:
任务3.1 卡方检验
- 复习第四章数据统计中卡方分布及参数检验相关内容,简述卡方检验基本原理与过程。
- 假设一次学科竞赛A、B两所学校各有300人参加,工作人员随机取样了两所学校若干同学的成绩情况,如文件夹中scores文件所示。
- 将文件夹中所给数据,转化成四格表形式。
合格 不合格
A学校
B学校 - 写出原假设与备择假设。
- 选择适当的假设检验方法,编程进行数据分析。输出自由度、卡方值、p值和最终检验结果(保留四位小数)。
任务3.2 T检验
- 简述T检验基本原理与过程。
- 设某工厂生产的一批灯泡服从正态分布,该批灯泡设计寿命为2000小时。现从该批灯泡中随机抽取11只进行测试,得到的最终寿命如下:1789, 1867, 2012, 2134, 1952, 1997, 1840, 1567, 2230, 2403,1777。请问,在显著水平为0.05下,能否认为本批灯泡合格?列出计算方法并编程验证。
任务3.3 方差检验(optional)
- 简述方差分析的种类、原理与流程。
- 某灯泡制造厂有3条不同的生产线,分别为国产A、德国产B和美国产C,有四班组生产工人,分别为甲、乙、丙、丁班组。经理希望研究不同生产线以及不同生产班组对产量的影响,因此安排生产计划,让甲、乙、丙、丁四班工人操作生产线A、B、C各生产3天,其灯泡产量如下表格所示:
A B C
甲 56,55,59 62,61,66 52,50,47
乙 47,45,49 54,50,55 42,45,48
丙 47,49,44 56,52,54 44,49,48
丁 53,57,54 54,61,60 48,51,64 - 请选用适合的方差分析方法,分析班组与生产线对灯泡产量是否有显著影响,并说明理由。
- 编程验证分析,并得出结论。
上机实现:
任务3.1卡方检验
导入所需要的包
import pandas as pdimport numpy as npimport osimport csvfrom scipy.stats import chi2_contingency
数据预处理
导入原始数据
``` 序号 成绩是否合格 所属学校 0 1 合格 A学校 1 2 合格 A学校 2 3 合格 A学校 3 4 合格 B学校 4 5 合格 B学校 .. … … … 234 235 合格 A学校 235 236 不合格 B学校 236 237 不合格 B学校 237 238 不合格 B学校 238 239 不合格 B学校file_path = r"D:\DataAnalysis\scores.xlsx"data = pd.read_excel(file_path,header=0)print(data)
[239 rows x 3 columns]
<a name="ccf66a03"></a>#### 转化为四格表```python# 统计出A学校及格、不及格的人数data2 = data.drop(columns='序号')data2.groupby('所属学校').value_counts()
所属学校 成绩是否合格A学校 合格 86不合格 36B学校 合格 77不合格 40dtype: int64
data3=[[86,36],[77,40]]data4 = pd.DataFrame(data3,index=['合格','不合格'],columns=['A学校','B学校'])data4
| A学校 | B学校 | |
|---|---|---|
| 合格 | 86 | 36 |
| 不合格 | 77 | 40 |
选取备择假设与原假设
原假设:A学校的合格率大于B学校
备择假设:A学校的合格率小于等于B学校
计算卡方等数字特征值
kt = chi2_contingency(data4)print('卡方值=%.4f, p值=%.4f, 自由度=%i expected_frep=%s'%kt)
卡方值=0.4066, p值=0.5237, 自由度=1 expected_frep=[[83.20502092 38.79497908][79.79497908 37.20502092]]
任务3.2 T检验
导入样本并计算样本均值
sample = np.array([1789, 1867, 2012, 2134, 1952, 1997, 1840, 1567, 2230, 2403, 1777])m = np.mean(sample)print("样本均值: %0.4f" % m)
T检验相关结果:样本均值: 1960.7273
计算t值和p值
t, p = stats.ttest_1samp(sample, 2000, axis=0) # 单样本检验print("t值: %0.4f" % t)print("p值: %0.4f" % p)print()print()
t值: -0.5586p值: 0.5887
结果简述:
根据计算出的p值和t值可知,在显著水平为0.05下,能认为本批灯泡合格。
任务3.3 方差检验
原理简述:
方差分析有以下几种类型:
- 单因素方差分析:只涉及一个自变量(也称因素)的情况。
- 双因素方差分析:涉及两个自变量的情况,可以考察两个自变量各自对反应变量的影响以及它们之间的交互作用。
- 重复测量方差分析:适用于同一受试者在不同时间点或条件下进行多次测量的情况。
方差分析的扩展:包括三因素、四因素及更多因素的方差分析等。
方差分析的原理基于总离差平方和的分解,将其分解为组内离差平方和和组间离差平方和,并通过比较组间离差平方和和组内离差平方和的大小,判断因素变量是否对反应变量有显著影响。
方差分析的流程大致如下:
- 确定问题并收集数据
- 建立假设并确定显著性水平
- 进行方差分析,计算组间
代码实现:
导入需要的数据和包
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom statsmodels.formula.api import olsfrom statsmodels.stats.anova import anova_lmfrom statsmodels.stats.multicomp import pairwise_tukeyhsd
将表中数据转换为如下的DataFrame对象
dfdata = {'line':['A','A','A','B','B','B','C','C','C','A','A','A','B','B','B','C','C','C','A','A','A','B','B','B','C','C','C','A','A','A','B','B','B','C','C','C'],'people':['甲','甲','甲','甲','甲','甲','甲','甲','甲','乙','乙','乙','乙','乙','乙','乙','乙','乙','丙','丙','丙','丙','丙','丙','丙','丙','丙', '丁','丁','丁','丁','丁','丁','丁','丁','丁'] ,'value':[56,55,59,62,61,66,52,50,47,47,45,49,54,50,55,42,45,48,47,49,44,56,52,54,44,49,48,53,57,54,54,61,60,48,51,64]}df = pd.DataFrame(dfdata)df
运行结果:
| line | people | value | |
|---|---|---|---|
| 0 | A | 甲 | 56 |
| 1 | A | 甲 | 55 |
| 2 | A | 甲 | 59 |
| 3 | B | 甲 | 62 |
| 4 | B | 甲 | 61 |
| 5 | B | 甲 | 66 |
| 6 | C | 甲 | 52 |
| 7 | C | 甲 | 50 |
| 8 | C | 甲 | 47 |
| 9 | A | 乙 | 47 |
| 10 | A | 乙 | 45 |
| 11 | A | 乙 | 49 |
| 12 | B | 乙 | 54 |
| 13 | B | 乙 | 50 |
| 14 | B | 乙 | 55 |
| 15 | C | 乙 | 42 |
| 16 | C | 乙 | 45 |
| 17 | C | 乙 | 48 |
| 18 | A | 丙 | 47 |
| 19 | A | 丙 | 49 |
| 20 | A | 丙 | 44 |
| 21 | B | 丙 | 56 |
| 22 | B | 丙 | 52 |
| 23 | B | 丙 | 54 |
| 24 | C | 丙 | 44 |
| 25 | C | 丙 | 49 |
| 26 | C | 丙 | 48 |
| 27 | A | 丁 | 53 |
| 28 | A | 丁 | 57 |
| 29 | A | 丁 | 54 |
| 30 | B | 丁 | 54 |
| 31 | B | 丁 | 61 |
| 32 | B | 丁 | 60 |
| 33 | C | 丁 | 48 |
| 34 | C | 丁 | 51 |
| 35 | C | 丁 | 64 |
描述性分析:
df.describe()
| value | |
|---|---|
| count | 36.000000 |
| mean | 52.444444 |
| std | 6.058969 |
| min | 42.000000 |
| 25% | 48.000000 |
| 50% | 52.000000 |
| 75% | 56.000000 |
| max | 66.000000 |
sns.boxplot(x = 'line', y = 'value', data = df)sns.boxplot(x = 'people', y = 'value', data = df)model = ols('value ~C(line) + C(people) + C(line):C(people)', data = df).fit()anova_table = anova_lm(model, type = 2)pd.DataFrame(anova_table)print(pairwise_tukeyhsd(df['value'], df['people']))print(pairwise_tukeyhsd(df['value'], df['line']))
print('方差检验相关结果:')print()df = pd.DataFrame(np.array([[56, 55, 59, 62, 61, 66, 52, 50, 47],[47, 45, 49, 54, 50, 55, 42, 45, 48],[47, 49, 44, 56, 52, 54, 44, 49, 48],[53, 57, 54, 54, 61, 60, 48, 51, 64]]))df.index = pd.Index(['甲', '乙', '丙', '丁'], name='班组')df.columns = pd.Index(['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'], name='生产线')df = df.stack().reset_index().rename(columns={0: '产量'})# print(df)model = ols('产量~C(班组) + C(生产线) + C(班组):C(生产线)', df).fit()print(anova_lm(model))
运行结果如下:
Multiple Comparison of Means - Tukey HSD, FWER=0.05=====================================================group1 group2 meandiff p-adj lower upper reject-----------------------------------------------------丁 丙 -6.5556 0.0417 -12.9229 -0.1882 True丁 乙 -7.4444 0.0169 -13.8118 -1.0771 True丁 甲 0.6667 0.9919 -5.7007 7.034 False丙 乙 -0.8889 0.9812 -7.2563 5.4785 False丙 甲 7.2222 0.0213 0.8548 13.5896 True乙 甲 8.1111 0.0082 1.7437 14.4785 True-----------------------------------------------------Multiple Comparison of Means - Tukey HSD, FWER=0.05=====================================================group1 group2 meandiff p-adj lower upper reject-----------------------------------------------------A B 5.8333 0.0232 0.6981 10.9685 TrueA C -2.25 0.5359 -7.3852 2.8852 FalseB C -8.0833 0.0014 -13.2185 -2.9481 True-----------------------------------------------------
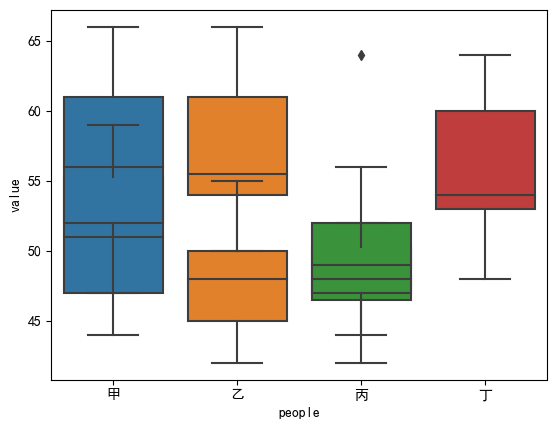
方差检验相关结果:df sum_sq mean_sq F PR(>F)C(班组) 3.0 489.555556 163.185185 13.412481 0.000024C(生产线) 2.0 417.722222 208.861111 17.166667 0.000024C(班组):C(生产线) 6.0 85.611111 14.268519 1.172755 0.353370Residual 24.0 292.000000 12.166667 NaN NaN
结果说明:
如上图所示,不同车间组,不同的生产线对产量有显著的影响。

若有收获,就点个赞吧
0 人点赞
