having和where区别
where语句字段,必须是”数据表中存在的”字段
having:语句字段,必须是查询结果集中存在的字段或者要么用聚合函数
1:having子句同where子句一样,进行条件判断
2:where是针对磁盘进行判断,进入到内存之后,会进行分组操作,分组的结果就需要having进行处理哟
3:having能做where能做的几乎所有的事情,但是where却不能做having能做的很多事情
4:,having能够使用字段别名:where不能,where是从磁盘中取出数据,而名字只可能是字段,别名是字段进行到内存后才会产生
select [all | distinct] 字段或表达式列表 [from子局] [where 子局] [group by子句] [having 子句] [order by子句] [limit 子句];
select可以单独用不跟from,如果想跟from可以from一个dual(伪表)
all和distinct用于设定select出来的数据,是否消除’重复行’,可以不写,那就是默认all,如果是distinct表示会消除
结果集中可以使用字段别名,但是where条件中要用表的名字
查询时间戳用select unix_timestamp();
where子句
where中的字段要来自表不能用之前取的别名
算术运算符: +, -, *, /, %
比较运算符: >, >=, <, <=, =(等于), <>(不等于), !=(不等于)
=即代表赋值也代表比较运算
[not] between and 介于两者之间或不介于2者之间
is null 为空 is not null 不为空
逻辑运算符: and, or, not
一个子查询返回的结果,理论上是”一行一列”的时候.此时可以当做一个单个值来使用,即单个数据值
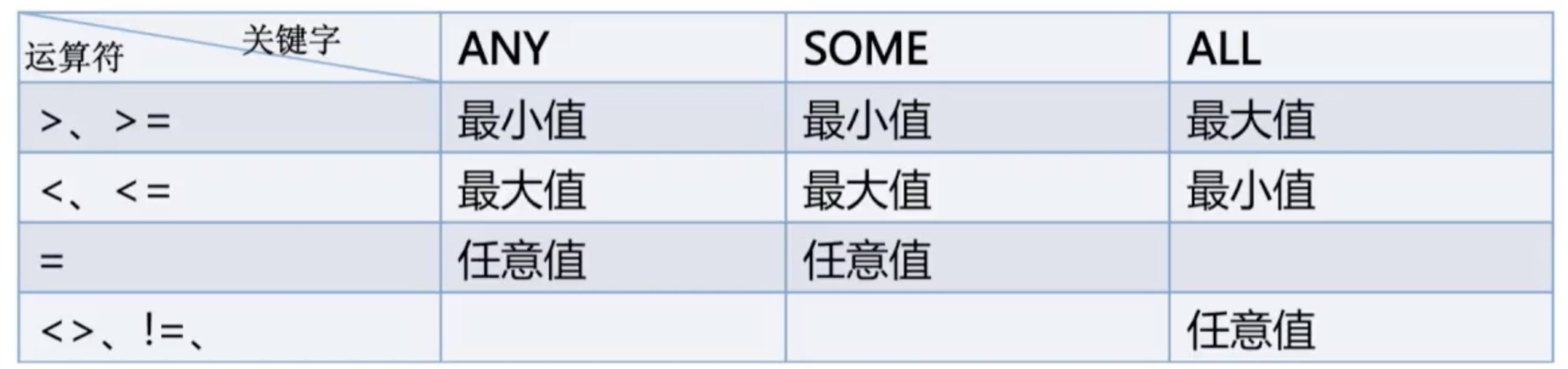
any 满足任意一个值就true all(some) 满足所有才true
例:查询所有非最高价商品 (只会小于上述所有价格中的某一个)
select from product where price < any (select price from product);
查询所有最高价商品(大于等于”所有价格”)
select from product where price >= all(select price from product);
子查询有多个值想要判断
例如: where xx > 这边可以用下面的几个关键字()
is运算符:
xx is null:判断某个字段是”null”值就是没有值
xx is not null: 判断某个字段不是”null”值
xx is true:判断某个字段为真
xx is false:判断某个字段为假 0, 0.0, ‘’, null
order by子句
order by字段1 [asc | desc], 字段2 [asc | desc],………. desc倒序 asc 顺序(排序默认小到大)
limit子句
limit offset,pagesize offset为偏移量,如果为0可以省略. pagesize每页显示的行数
分页公式:pagesize:每页显示条数,page:当前页. limit(page-1)*pagesize,pagesize

若有收获,就点个赞吧
0 人点赞
