简介
缓存池是解决读的
change buffer是解决写的
缓存池
缓存池就是数据从磁盘读取出来, 缓存到内存中, 这个地方叫做缓存池, 避免每次从磁盘访问
但是缓存池有大小, 只把最热的数据放在里面, 剩下的数据LRU淘汰掉
预读
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读为什么有效?
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO
传统LRU
把入缓冲池的页放到LRU的头部,作为最近访问的元素,从而最晚被淘汰。这里又分两种情况:
(1)页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰;
(2)页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作
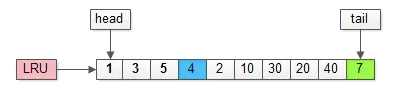
如上图,假如管理缓冲池的LRU长度为10,缓冲了页号为1,3,5…,40,7的页。
假如,接下来要访问的数据在页号为4的页中: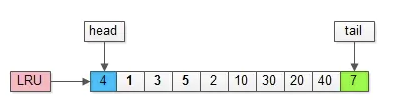
(1) 页号4本来就在里面
(2) 把页号4放到头部没有页被淘汰
为了减少数据移动, LRU一般用链表实现, 还会利用跳表
假如,再接下来要访问的数据在页号为50的页中:
(1)页号为50的页,原来不在缓冲池里;
(2)把页号为50的页,放到LRU头部,同时淘汰尾部页号为7的页;
传统LRU算法问题
(1)预读失效;
(2)缓冲池污染;
预读失效
由于预读(Read-Ahead),提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
如何解决
要优化预读失效,思路是:
(1)让预读失败的页,停留在缓冲池LRU里的时间尽可能短;
(2)让真正被读取的页,才挪到缓冲池LRU的头部;
以保证,真正被读取的热数据留在缓冲池里的时间尽可能长。
具体方法是:
(1)将LRU分为两个部分:
- 新生代(new sublist)
- 老生代(old sublist)
(2)新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head);
(3)新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
- 如果数据真正被读取(预读成功),才会加入到新生代的头部
- 如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
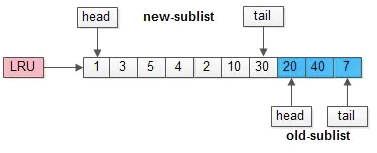
举个例子,整个缓冲池LRU如上图:
(1)整个LRU长度是10;
(2)前70%是新生代;
(3)后30%是老生代;
(4)新老生代首尾相连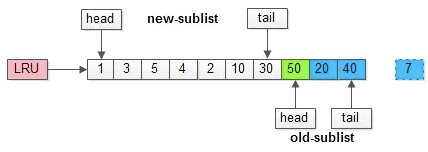
假如有一个页号为50的新页被预读加入缓冲池:
(1)50只会从老生代头部插入,老生代尾部(也是整体尾部)的页会被淘汰掉;
(2)假设50这一页不会被真正读取,即预读失败,它将比新生代的数据更早淘汰出缓冲池;
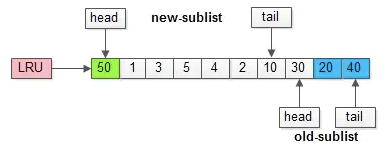
假如50这一页立刻被读取到,例如SQL访问了页内的行row数据:
(1)它会被立刻加入到新生代的头部;
(2)新生代的页会被挤到老生代,此时并不会有页面被真正淘汰;
改进版缓冲池LRU能够很好的解决“预读失败”的问题。
不要因为害怕预读失败而取消预读策略,大部分情况下,局部性原理是成立的,预读是有效的
新老生代改进版LRU仍然解决不了缓冲池污染的问题。
缓存污染
当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
例如,有一个数据量较大的用户表,当执行:
select * from user where name like "%shenjian%";
虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页:
(1)把页加到缓冲池(插入老生代头部);
(2)从页里读出相关的row(插入新生代头部);
(3)row里的name字段和字符串shenjian进行比较,如果符合条件,加入到结果集中;
(4)…直到扫描完所有页中的所有row…
如此一来,所有的数据页都会被加载到新生代的头部,但只会访问一次,真正的热数据被大量换出。
为什么解决这个情况?
MySQL缓冲池加入了一个“老生代停留时间窗口”的机制:
(1)假设T=老生代停留时间窗口;
(2)插入老生代头部的页,即使立刻被访问,并不会立刻放入新生代头部;
(3)只有满足“被访问”并且“在老生代停留时间”大于T,才会被放入新生代头部;
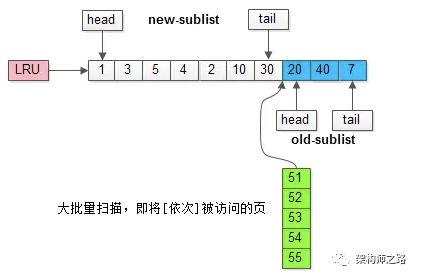
继续举例,假如批量数据扫描,有51,52,53,54,55等五个页面将要依次被访问。
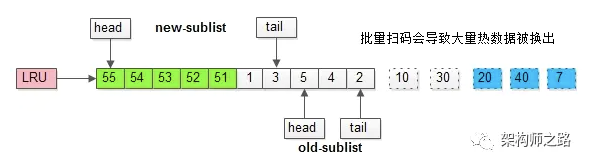
如果没有“老生代停留时间窗口”的策略,这些批量被访问的页面,会换出大量热数据。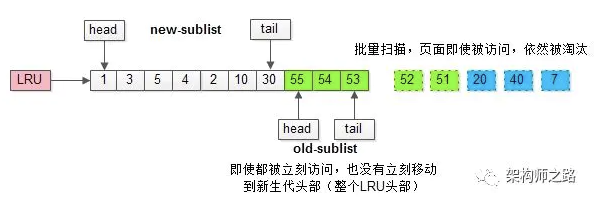
加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。
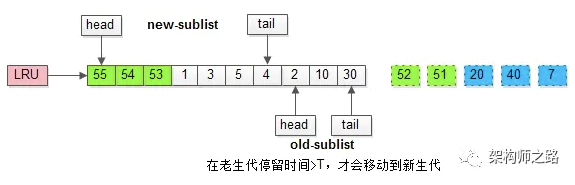
而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。
innodb 中的参数
mysql> show global variables like 'innodb_buffer_pool_size';+-------------------------+-----------+| Variable_name | Value |+-------------------------+-----------+| innodb_buffer_pool_size | 134217728 |+-------------------------+-----------+1 row in set (0.04 sec)mysql> show global variables like 'innodb_old_blocks_pct';+-----------------------+-------+| Variable_name | Value |+-----------------------+-------+| innodb_old_blocks_pct | 37 |+-----------------------+-------+1 row in set (0.00 sec)mysql> show global variables like 'innodb_old_blocks_time';+------------------------+-------+| Variable_name | Value |+------------------------+-------+| innodb_old_blocks_time | 1000 |+------------------------+-------+1 row in set (0.00 sec)
参数:innodbbuffer_pool_size
介绍:配置缓冲池的大小,在内存允许的情况下,DBA往往会建议调大这个参数,越多数据和索引放到内存里,数据库的性能会越好。
参数:innodb_old_blocks_pct
介绍:老生代占整个LRU链长度的比例,默认是37,即整个LRU中新生代与老生代长度比例是63:37。
画外音:如果把这个参数设为100,就退化为普通LRU了。_
参数:innodb_old_blocks_time
介绍:老生代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老生代停留时间超过1秒”两个条件,才会被插入到新生代头部
(1)缓冲池(buffer pool)是一种常见的降低磁盘访问的机制;
(2)缓冲池通常以页(page)为单位缓存数据;
(3)缓冲池的常见管理算法是LRU,memcache,OS,InnoDB都使用了这种算法;
(4)InnoDB对普通LRU进行了优化:
- 将缓冲池分为老生代和新生代,入缓冲池的页,优先进入老生代,页被访问,才进入新生代,以解决预读失效的问题
- 页被访问,且在老生代停留时间超过配置阈值的,才进入新生代,以解决批量数据访问,大量热数据淘汰的问题
change buffer
什么是change buffer
假如要修改页号为4的索引页,而这个页正好在缓冲池内。
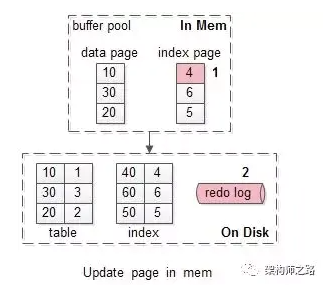
如上图序号1-2:
(1)直接修改缓冲池中的页,一次内存操作;
(2)写入redo log,一次磁盘顺序写操作;
这样的效率是最高的。
画外音:像写日志这种顺序写,每秒几万次没问题。
是否会出现一致性问题呢?
并不会。
(1)读取,会命中缓冲池的页;
(2)缓冲池LRU数据淘汰,会将“脏页”刷回磁盘;
(3)数据库异常奔溃,能够从redo log中恢复数据;
什么时候缓存池中的页,会刷到磁盘上呢?
定期刷磁盘,而不是每次刷磁盘,能够降低磁盘IO,提升MySQL的性能。
批量写,是常见的优化手段
没有chaneg buffer的情况
假如要修改页号为40的索引页,而这个页正好不在缓冲池内。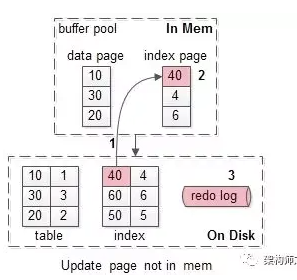
此时麻烦一点,如上图需要1-3:
(1)先把需要为40的索引页,从磁盘加载到缓冲池,一次磁盘随机读操作;
(2)修改缓冲池中的页,一次内存操作;
(3)写入redo log,一次磁盘顺序写操作;
没有命中缓冲池的时候,至少产生一次磁盘IO,对于写多读少的业务场景,是否还有优化的空间呢?
这即是InnoDB考虑的问题,又是本文将要讨论的写缓冲(change buffer)。
从名字容易看出,写缓冲是降低磁盘IO,提升数据库写性能的一种机制
在MySQL5.5之前,叫插入缓冲(insert buffer),只针对insert做了优化;现在对delete和update也有效,叫做写缓冲(change buffer)
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。
写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
加入change buffer
假如要修改页号为40的索引页,而这个页正好不在缓冲池内。
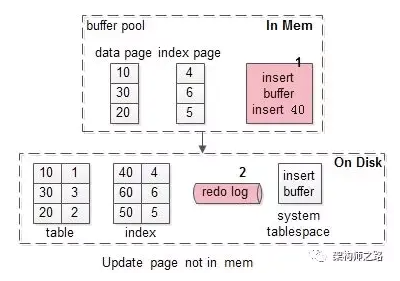
加入写缓冲优化后,流程优化为:
(1)在写缓冲中记录这个操作,一次内存操作;
(2)写入redo log,一次磁盘顺序写操作;
其性能与,这个索引页在缓冲池中,相近。<br />
可以看到,40这一页,并没有加载到缓冲池中
是否会出现一致性问题呢?
也不会。
(1)数据库异常奔溃,能够从redo log中恢复数据;
(2)写缓冲不只是一个内存结构,它也会被定期刷盘到写缓冲系统表空间;
(3)数据读取时,有另外的流程,将数据合并到缓冲池;
为什么唯一索引不行
如果索引设置了唯一(unique)属性,在进行修改操作时,InnoDB必须进行唯一性检查。也就是说,索引页即使不在缓冲池,磁盘上的页读取无法避免(否则怎么校验是否唯一?),此时就应该直接把相应的页放入缓冲池再进行修改,而不应该再整写缓冲这个幺蛾子。
除了数据页被访问,还有哪些场景会触发刷写缓冲中的数据呢?
还有这么几种情况,会刷写缓冲中的数据:
(1)有一个后台线程,会认为数据库空闲时;
(2)数据库缓冲池不够用时;
(3)数据库正常关闭时;
(4)redo log写满时;
什么场景适合写缓冲
当:
(1)数据库都是唯一索引;
(2)或者,写入一个数据后,会立刻读取它;
这两类场景,在写操作进行时(进行后),本来就要进行进行页读取,本来相应页面就要入缓冲池,此时写缓存反倒成了负担,增加了复杂度。
什么时候适合使用写缓冲,如果:
(1)数据库大部分是非唯一索引;
(2)业务是写多读少,或者不是写后立刻读取;
可以使用写缓冲,将原本每次写入都需要进行磁盘IO的SQL,优化定期批量写磁盘。
例如,账单流水业务
innodb里面的参数
mysql> show global variables like 'innodb_change_buffer_max_size';+-------------------------------+-------+| Variable_name | Value |+-------------------------------+-------+| innodb_change_buffer_max_size | 25 |+-------------------------------+-------+1 row in set (0.00 sec)mysql> show global variables like 'innodb_change_buffering';+-------------------------+-------+| Variable_name | Value |+-------------------------+-------+| innodb_change_buffering | all |+-------------------------+-------+1 row in set (0.00 sec)
参数:innodb_change_buffer_max_size
介绍:配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,最大值是50%。*画外音:写多读少的业务,才需要调大这个值,读多写少的业务,25%其实也多了。*
参数:innodb_change_buffering
介绍:配置哪些写操作启用写缓冲,可以设置成all/none/inserts/deletes等。
change buffer整个流程
:::info
redo 是优化写的
change是优化读的
非唯一索引, 你要做改变, 首先要去查下这个数据, 再修改
这个查询会导致一次磁盘io, 如何避免这个磁盘io
就把这个change 记录下来
:::
先说一下普通一个数据修改的过程(这里不涉及到改主键索引或唯一索引B+树结构的,就说改普通字段的值)
第一步:INNODB要修改一个数据时,先判断内存(Buffer Pool)中有没有这个数据,有的话则直接修改内存。没有的话,先从磁盘中读到内存,再进行修改(先假设是这样)。
第二步:写redo log,将事务的状态标位prepare
第三步:写binlog
第四步;将redo log中事务的状态标位commit
到这里,一个事务已经结束了,但是你会发现,数据压根就没落盘,只在Buffer Pool进行了相应的修改。而这些在内存中的数据(脏页)会在一段时间后因为某些原因才会被刷到磁盘中,那在这中间还没有刷到磁盘的过程中,则有可能发生断电,那还没有保存到磁盘中的buffer pool中的数据也就丢了,而redo log的作用,就是断电重启之后,用来恢复这部分的数据。(在我看来,redo log的作用仅此而已,有误的话可以指正)
再回过头看第一步:如果是普通索引(非唯一索引),哪怕内存中没有这条数据,直接保存修改就行了,连去磁盘读取出这条数据这一步都不需要,节省了磁盘IO的时间。也就是上面说的流程中的第一步其实应该改为:如果仅仅修改了普通索引的话,内存中若有这条数据,则直接修改,若没这条数据,则先将修改的操作写到change buffer中。
回到问题:change buffer是做什么的?
答:当然是为了提高效率的,但是有一定的局限性,基本上只能用在:数据在磁盘中而不在内存中,而这次修改不会涉及到改动主键索引以及唯一索引的结构 的情况之下。也就是优化了上面流程中的第一步。

若有收获,就点个赞吧
0 人点赞
