MDL表元数据锁
MDL锁是为了解决DDL和DML之间冲突的问题。
- 假设事务A先查询得到一个数据,然后事务B执行了字段修改,那么事务A再次去查的时候,发现数据对不上了
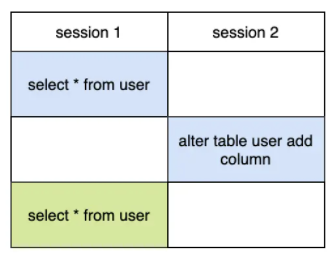
- 事务A先更新数据未提交,事务B修改字段提交,slave就会先修改字段,再更新数据,那么就会有问题
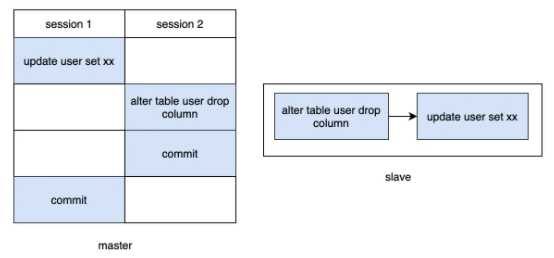
当使用了MDL锁后,DDL操作必须要先获得MDL写锁,我们知道写锁和写锁,写锁和读锁是冲突的,那么在DDL之前如果有任何查询或者更新,都必须要阻塞等待,不会让DDL执行的,从而解决了冲突问题
做MDL的时候, 执行查询会发生什么?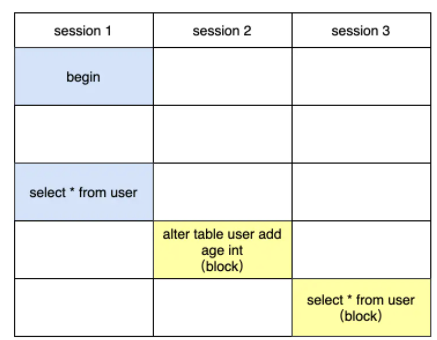
首先MDL锁一定是在事务提交后才释放的,session1在执行查询后,并没有commit,那么MDL读锁是没有释放的,session2紧接着执行DDL,执行DDL是要获取MDL写锁的,由于写锁和读锁是互斥的,那么session2是卡住的,它在等待session1释放读锁,session3在session2之后执行的,此时session3是需要一个读锁的,但是由于获取锁是有先后顺序的,它们要排队,并且写锁的优先级要高于读锁,这也是为什么session3会卡住
所以是session1执行commit之后,然后session2先执行完,最后session3先执行完?刚试了下,看着好像session2和session3几乎同时运行完,为什么呢?
不是的,并不是session2先执行完,其实是session3先执行完,但是session2会先获得MDL写锁,由于session3没有显式的开启一个事务,那么session3默认执行完毕之后自动commit,所以在session1 commit之后,看起来像session2和session3几乎同时进行的。如果让session3显式的开启事务,就能发现运行的细节了。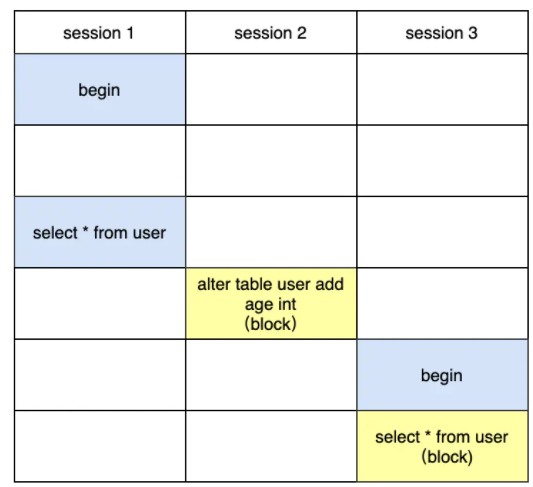
这样当session1 commit之后可以发现session3先执行,session2依然是卡住的,只有当session3 commit之后,发现session2才能运行。所以真实情况应该是session3先执行,然后session2
mysql支持在线DDL,不阻塞用户操作,当执行一个DDL,它的流程大概是这样的:
- 拿MDL写锁
- 降级成MDL读锁
- 真正做DDL
- 升级成MDL写锁
- 释放MDL锁
其中session2在拿到MDL写锁后,会降级成MDL读锁,降级后,session3拿到MDL读锁,然后执行select,但是没有commit,这样MDL读锁就没释放,然后session2在升级成MDL写锁的时候因为session3没释放读锁从而导致session2阻塞。
为什么DDL过程中1-2要降级,而3-4又要升级吗?
首先在MDL写锁期间,干的事就是创建临时的frm和idb文件,这个过程要安全,是排他的,同时这个过程也是快速的,在临时文件创建好之后,就不需要排他了,那么就降级为读锁,支持正常的增删改查,这也是为什么DDL支持online的原因之一。在新的数据文件写好之后,要替换老的数据文件,这个过程要安全,所以在3执行完后,会尝试升级成MDL写锁,这个过程也是快速的,也是支持online DDL的原因之二。
next-key lock
假设有一张表,表里有10条记录,还有个字段user_id,并且user_id是普通索引。
+----+---------+| id | user_id |+----+---------+| 1 | 10 || 2 | 20 || 3 | 30 || 4 | 40 || 5 | 50 || 6 | 60 || 7 | 70 || 8 | 80 || 9 | 90 || 10 | 100 |+----+---------+
如果事务A执行:
SELECT * FROM user WHERE user_id=50 FOR UPDATE;
紧接着事务B执行下面的sql会发生什么?:
INSERT INTO user set user_id=45;
阻塞
因为InnoDB的Next-Key Lock算法,不仅仅会锁住user_id=50这条记录,还会锁住50左右的间隙。Next-Key Lock锁定的范围是左开右闭的,那么理论上最终(40,50],(50,60]的区间数据会被锁定。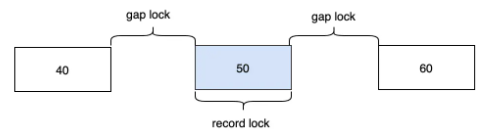
由于要插入的45在40-50之间,所以就会发生阻塞。
那按照区间锁法,是包含60这条数据的是吧,所以如果插入一条60的数据,就会发生阻塞?
INSERT INTO user set user_id=60;
其实不会,这里涉及到next key lock的优化,在等值查询中,向右遍历时且最后一个值不满足等值条件的时候,Next-Key Lock会退化为Gap Lock,所以对于(50,60]这个区间最终会降级为(50,60),那么60这条数据就不会被锁住,是可以插入成功的。
那40这条数据是不在这个锁区间的,所以可以插入40这条数据?
INSERT INTO user set user_id=40;
其实也不会,40这条数据的插入也会阻塞,首先对于非聚集索引user_id它的叶子节点一定是排序的,大概就像(40,4),(50,5)这样,其次因为主键id是自增的,那么对于再插入一条40的数据,它的主键id一定是大于4的,就目前10条数据来说,下一次插入的id肯定是11,那(4,11)这条数据肯定是要在(40,4)后面的,这样的话,就落入到了间隙锁中,所以会阻塞,其实上面60那条数据可以插入也是同样的道理。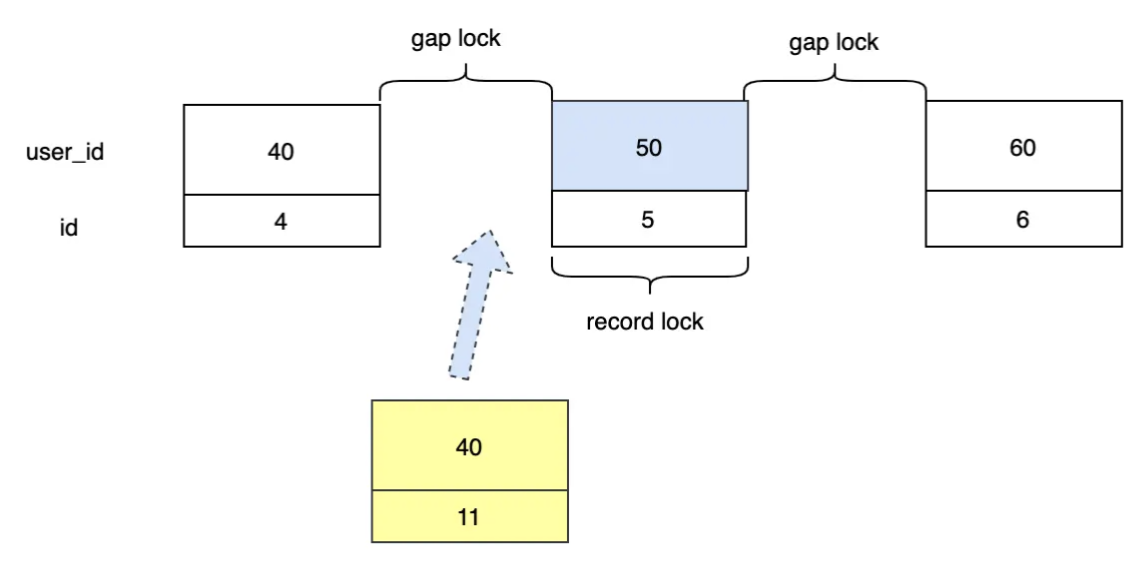
那如果我一开始不用select for update了,而用select lock in share mode,那么所有的插入会有什么变化吗?
没有变化,还是一样,因为插入需要X锁,X锁和任何锁都互斥。
如果user_id不是普通索引而是唯一索引,那会有什么变化?
当索引是唯一索引时,那么就会发生降级,Next Key Lock会降级成Record Lock,最终只会锁住50这条记录。
如果user_id没有索引怎么办?
那就所有的记录都会锁上,任何的插入都会阻塞。
那你知道为什么要有间隙锁这个东西吗?
为了解决幻读。比如当事务A执行以下查询时
SELECT * FROM user WHERE id>=9 for update
应该返回两条记录(id=9和id=10),这时候如果另一个事务B执行
INSERT INTO user set user_id=110;
在没有间隙锁的情况下,那么事务A再次查询会发现多了一条记录,就出现了幻读,如果有了间隙锁,那么[9,+∞)这个区间都会被锁住,事务B的插入就会阻塞。但是只有在事务的隔离级别设置成可重复读的时候,才支持间隙锁。
如果某个上了锁的事务一直不提交,那么后面需要获取相关锁的事务就会阻塞,这样会有什么问题?
如果阻塞的事务越来越多,那么阻塞的线程也会越来越多,严重时会造成连接池满了,mysql不能提供服务了。但是InnoDB支持阻塞超时后,会自动放弃这个等待锁的sql命令,这个值默认是50s。
+--------------------------+-------+| Variable_name | Value |+--------------------------+-------+| innodb_lock_wait_timeout | 50 |+--------------------------+-------+
Auto-inc locking
自增长锁,在InnoDB引擎中,每个表都会维护一个表级别的自增长计数器,当对表进行插入的时候,会通过以下的命令来获取当前的自增长的值。
SELECT MAX(auto_inc_col) FROM user FOR UPDATE;
插入操作会在这个基础上加1得到即将要插入的自增长id。
我们知道事务中的锁是在事务提交后才释放的,那么在更新自增长id后,当事务没来及提交,其它的事务获取自增长id就要等待吗?这样的话效率是不是有点低?
不用等待的,为了提高插入性能,自增长的锁不会等到事务提交之后才释放,而是在相关插入sql语句完成后立刻就释放的,这也是为什么一些事务回滚之后,发现id不连续的原因:
A
虽然AUTO-INC Locking可以不用等事务提交就释放,但是在并发的时候,因为AUTO-INC Locking本身会对自增id上锁的,还是会影响效率,这个该怎么解决?
现在InnoDB支持互斥量的方式来实现自增长,通过互斥量可以对内存中的计数器进行累加操作,比AUTO-INC Locking要快些

若有收获,就点个赞吧
0 人点赞
