分析
协处理器-coprocessor
协处理器有两种:observer和endpoint
Observer允许集群在正常的客户端操作过程中可以有不同的行为表现
Endpoint允许扩展集群的能力,对客户端应用开放新的运算命令
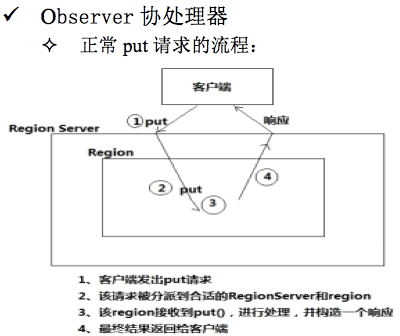
- 客户端发出put请求
- 该请求被分派给合适的RegionServer和region
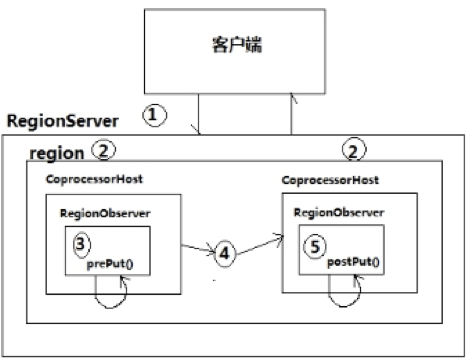
- coprocessorHost拦截该请求,然后在该表上登记的每个RegionObserver上调用prePut()
- 如果没有被prePut()拦截,该请求继续送到region,然后进行处理
- region产生的结果再次被CoprocessorHost拦截,调用postPut()
- 假如没有postPut()拦截该响应,最终结果被返回给客户端
- Observer的类型
- RegionObs——这种Observer钩在数据访问和操作阶段,所有标准的数据操作命令都可以被pre-hooks和post-hooks拦截
- WALObserver——WAL所支持的Observer;可用的钩子是pre-WAL和post-WAL
- MasterObserver——钩住DDL事件,如表创建或模式修改
二级索引
row key在HBase中是以B+ tree结构化有序存储的,所以scan起来会比较效率。单表以row key存储索引,column value存储id值或其他数据 ,这就是Hbase索引表的结构。
由于HBase本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠RowKey,为了能支持多条件查询,开发者需要将所有可能作为查询条件的字段一一拼接到RowKey中,这是HBase开发中极为常见的做法
比如,现在有一张1亿的用户信息表,建有出生地和年龄两个索引,我想得到一个条件是在杭州出生,年龄为20岁的按用户id正序排列前10个的用户列表。
有一种方案是,系统先扫描出生地为杭州的索引,得到一个用户id结果集,这个集合的规模假设是10万。然后扫描年龄,规模是5万,最后merge这些用户id,去重,排序得到结果。
这明显有问题,如何改良?
保证出生地和年龄的结果是排过序的,可以减少merge的数据量?但Hbase是按row key排序,value是不能排序的。
变通一下——将用户id冗余到row key里?OK,这是一种解决方案了,这个方案的图示如下:
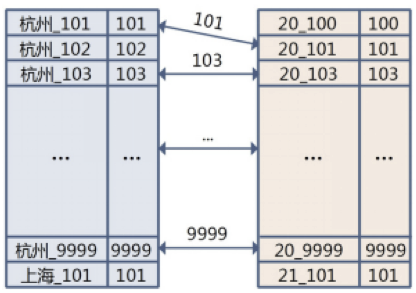
merge时提取交集就是所需要的列表,顺序是靠索引增加了_id,以字典序保证的。
按索引查询种类建立组合索引。
在方案1的场景中,想象一下,如果单索引数量多达10个会怎么样?10个索引,就要merge 10次,性能可想而知。
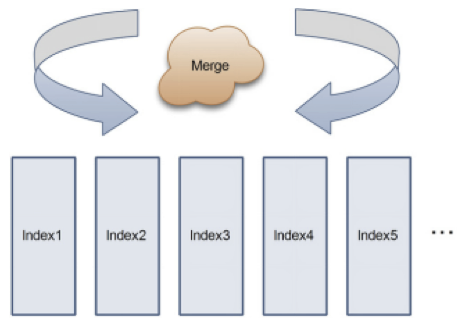
解决这个问题需要参考RDBMS的组合索引实现。
比如出生地和年龄需要同时查询,此时如果建立一个出生地和年龄的组合索引,查询时效率会高出merge很多。
当然,这个索引也需要冗余用户id,目的是让结果自然有序。结构图示如下:
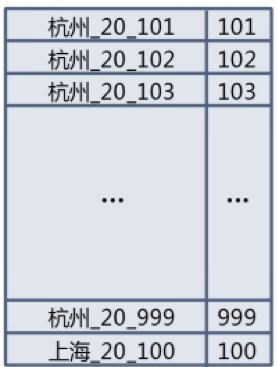
这个方案的优点是查询速度非常快,根据查询条件,只需要到一张表中检索即可得到结果list。缺点是如果有多个索引,就要建立多个与查询条件一一对应的组合索引
而索引表的维护如果交给应用客户端,则无疑增加了应用端开发的负担
通过协处理器可以将索引表维护的工作从应用端剥离
- 利用Observer自动维护索引表示例
在社交类应用中,经常需要快速检索各用户的关注列表t_guanzhu,同时,又需要反向检索各种户的粉丝列表t_fensi,为了实现这个需求,最佳实践是建立两张互为反向的表: - 一个表为正向索引关注表 “t_guanzhu”:
Rowkey: A-B
f1:From
f1:To - 另一个表为反向索引粉丝表:“t_fensi”:
Rowkey: B—A
f1:From
f1:To
插入一条关注信息时,为了减轻应用端维护反向索引表的负担,可用Observer协处理器实现:

prePut就是前置put
postPut就是后置put
代码
- 编写代码
package com.study;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.Cell;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;import org.apache.hadoop.hbase.coprocessor.ObserverContext;import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;import org.apache.hadoop.hbase.regionserver.wal.WALEdit;import java.io.IOException;public class FFCoprocessor extends BaseRegionObserver {@Overridepublic void prePut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {Configuration conf = HBaseConfiguration.create();Connection conn = ConnectionFactory.createConnection(conf);//二级索引表Table table = conn.getTable(TableName.valueOf("index_user"));//拦截到原始put对象中的rowkey和列的Value//rowkey//列的valuebyte[] row = put.getRow();String rowkey = new String(row);Cell addressCell = put.get("info".getBytes(), "address".getBytes()).get(0);byte[] valueArray = addressCell.getValueArray();String address = new String(valueArray, addressCell.getValueOffset(), addressCell.getValueLength());//原本的行键用-连起来的String[] user_fensi = rowkey.split("-");//里面的是二级索引表的rowkey,添加到二级索引表Put putIndex = new Put((user_fensi[1] + "-" + user_fensi[0]).getBytes());putIndex.addColumn("info".getBytes(), "address".getBytes(),address.getBytes());table.put(putIndex);table.close();}}
- 打成jar包“coprocess.jar”上传hdfs
hadoop fs -put coprocess.jar /
- 创建表
create 'user_guanzhu','info'create 'index_user','info'
- 修改schema,注册协处理器
需要先disable一下
disable 'user_guanzhu'
注意下面的表名,jar包和类名修改为自己的
coprocessor后面是指明协处理器jar包的地址,用|分割,指明对应类的全路径名然后|后跟上标识id
alter 'user_guanzhu',METHOD => 'table_att','coprocessor'=>'hdfs://master:9000/coprocess.jar|com.study.FFCoprocessor|1001|'
启用这个表
enable 'user_guanzhu'
- 检查是否注册成功,可以看到注册的协处理器
describe 'user_guanzhu'
- 向正向索引表中插入数据进行验证
put 'user_guanzhu','zhangsan-liuyifei','info:address','beijing'
删除协处理器
先disable表disable 'user_guanzhu'删除,$1表示是第一个协处理器alter 'user_guanzhu',METHOD=>'table_att_unset',NAME=>'coprocessor$1'再enable表enable 'user_guanzhu'

若有收获,就点个赞吧
0 人点赞
