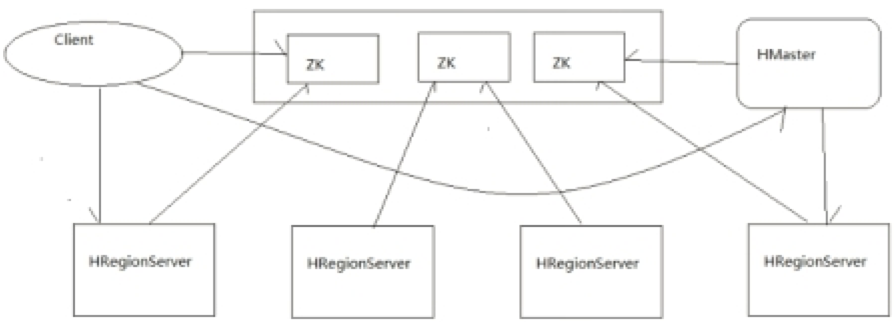
系统架构图
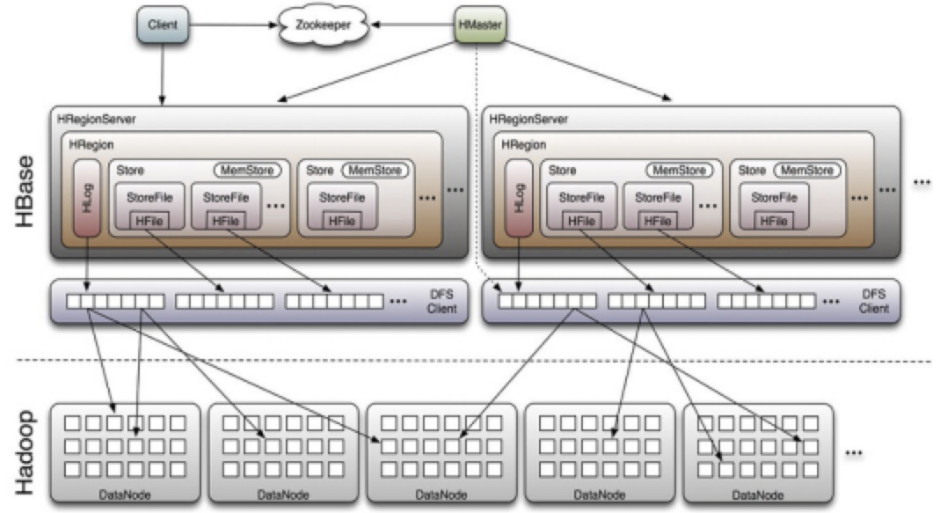
存储
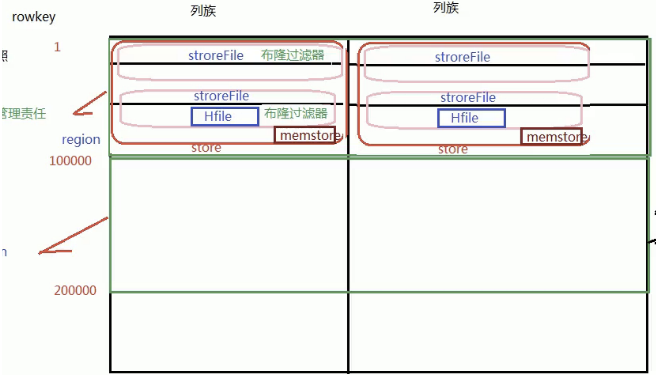
- store
一个region按照列族划分的,多个列族会有多个store - storeFile
每个store里面又有很多个storeFile,他是store里面按照rowkey来划分的,storeFile是以一种特殊的文件格式Hfile来存储在hdfs上的,所以经常把datanode和RegionServer放一起,提高查询.
sotre中有很多storefile,那么如何知道数据在哪个文件?
每个soreFile都有一个布隆过滤器,先把所有元素放在集合中,然后用来判断一个元素在不在集合里面 - 布隆过滤器
是一种空间效率很高的随机数据结构
查询一个rowkey,会把rowkey会转换64bit
布隆过滤器会存这个storeFile所有的rowkey,然后要查询的rowkey和布隆过滤器比较 - memstore
每个store有一个memstore,当他达到一定阈值后会写入磁盘上
内存中的,数据写入的时候会写入memstore
他存储近期访问的数据和提交的数据,还有经常访问的数据,查询的时候可以不走底层的hdfs文件,可以从memstore先进行检索
Client
- 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问(经常访问的数据放到块缓存),比如regione的位置信息。
Zookeeper
- 保证任何时候,集群中只有一个master
- 存贮所有Region的寻址入口——root表在哪台服务器上。
- 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
- 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master职责
- 为Region server分配region
- 负责region server的负载均衡
- 发现失效的region server并重新分配其上的region
- HDFS上的垃圾文件回收
- 处理schema更新请求
- hbase的主节点,负责整个集群的状态感知,负载分配、负责用户表的元数据管理
- DDL(create,update,delete表)操作
- 不直接存储数据,负责统筹分配和DDL操作
RegionServer职责
- Region server维护Master分配给它的region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。 - 真正负责管理region的服务器,也就是负责为客户端进行表数据读写的服务器
regions
- hbase中对表进行切割的单元,按rowkey分割的
- hbase以Rowkey的起止区间为范围被水平切分成了多个Region.每个Region中包含了RowKey从开始到结束区间的所有行.这些Region被分配到的集群节点称为RegionServers
Region管理
BLOOMFILTER
布隆过滤器
当一个regionserver数据很大的时候,会有很多文件.
虽然能定位在那个regionserver上,但是下面有很多文件
如何定位这个数据在那个文件中?
布隆过滤器会不断的查询这个数据在不在这个文件中,一直检测,做反向判断
region分配
任何时刻,一个region只能分配给一个region server。master记录了当前有哪些可用的region server。以及当前哪些region分配给了哪些region server,哪些region还没有分配。当需要分配的新的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
region server上线
master使用zookeeper来跟踪region server状态。当某个region server启动时,会首先在zookeeper上的server目录下建立代表自己的znode。由于master订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知。因此一旦region server上线,master能马上得到消息。
region server下线
当region server下线时,它和zookeeper的会话断开,zookeeper而自动释放代表这台server的文件上的独占锁。master就可以确定:
- region server和zookeeper之间的网络断开了。
- region server挂了。
无论哪种情况,region server都无法继续为它的region提供服务了,此时master会删除server目录下代表这台region server的znode数据,并将这台region server的region分配给其它还活着的同志
master工作机制
master上线
master启动进行以下步骤:
- 从zookeeper上获取唯一一个代表active master的锁,用来阻止其它master成为master。
- 扫描zookeeper上的server父节点,获得当前可用的region server列表。
- 和每个region server通信,获得当前已分配的region和region server的对应关系。
- 扫描.META.region的集合,计算得到当前还未分配的region,将他们放入待分配region列表。
master下线
由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region 上下线,无法进行region的合并,唯一例外的是region的split可以正常进行,因为只有region server参与),表的数据读写还可以正常进行。因此master下线短时间内对整个hbase集群没有影响。
从上线过程可以看到,master保存的信息全是可以冗余信息(都可以从系统其它地方收集到或者计算出来)
因此,一般hbase集群中总是有一个master在提供服务,还有一个以上的‘master’在等待时机抢占它的位置
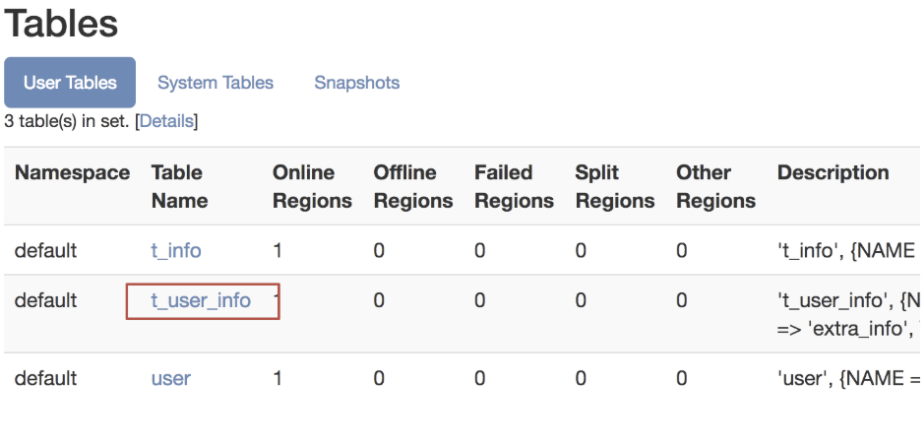
数据更新
点击web管理页面中的表
上面是合并,下面是切分
数据修改删除并不会从hdfs上真正的去掉,旧数据还是会冗余的
hdfs不支持数据更新,他只是在hdfs上对数据标记,get,scan的时候不显示数据
合并数据他还会定期清除数据,因为一些数据更新后,老的数据还是在的,他会定期清除的
合并还有大合并(major compaction)和小合并(minor compaction)
大合并,对于整个Region下面的store的所有storefile是把所有的文件整理成一个,涉及很多磁盘IO
小合并,将超过设置版本数量的数据和生命周期的数据,进行清除,但是他不会做任何删除数据的操作,删除数据的工作是在大合并中做的

若有收获,就点个赞吧
0 人点赞
