下面几个shell 命令在hbase操作中可以起到很到的作用,且主要体现在建表的过程中,看下面几个create 属性
BLOOMFILTER
默认是NONE 是否使用布隆过虑及使用何种方式
布隆过滤可以每列族单独启用。
使用 HColumnDescriptor.setBloomFilterType(NONE | ROW | ROWCOL) 对列族单独启用布隆。
- Default = ROW 对行进行布隆过滤。
- 对 ROW,行键的哈希在每次插入行时将被添加到布隆。
- 对 ROWCOL,行键 + 列族 + 列族修饰的哈希将在每次插入行时添加到布隆
使用方法:
create 'table',{BLOOMFILTER =>'ROW'}
启用布隆过滤可以节省读磁盘过程,可以有助于降低读取延迟
BLOCKSIZE 块缓存
建表的时候可以设置数据块大小
create 'mytable', {NAME=>'colfam1',BLOCKSIZE=>'65536'}
数据库缓存默认是打开的,可以在建表的时候关闭他
create 'mytable', {NAME=>'colfam1',BLOCKSIZE=>'false'}
激进缓存
可以选择一些列族,赋予他们在数据块缓存里有更高的优先级(LRU缓存).如果你预期一个列族比另一个列族随机读更多,这个特性迟早用的上.这个配置是在表实例化的时候定义:
create 'mytable', {NAME=>'colfam1',IN_MEMORY=>'true'}
IN_MEMORY的参数默认是false.因为hbase除了在数据块缓存里保存这个列族相比其他列族更激进之外并不提供额外保证,所以设置为true不会变化太大
VERSIONS
默认是1 这个参数的意思是数据保留1个 版本,如果我们认为我们的数据没有这么大的必要保留这么多,随时都在更新,而老版本的数据对我们毫无价值,那将此参数设为1 能节约2/3的空间
使用方法: create 'table',{VERSIONS=>'2'}
附:MIN_VERSIONS => '0'是说在compact操作执行之后,至少要保留的版本
COMPRESSION 压缩
默认值是NONE 即不使用压缩
这个参数意思是该列族是否采用压缩,采用什么压缩算法
使用方法: create 'table',{NAME=>'info',COMPRESSION=>'SNAPPY'}
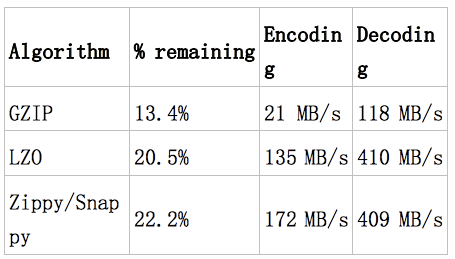
建议采用SNAPPY压缩算法
HBase中,在Snappy发布之前(Google 2011年对外发布Snappy),采用的LZO算法,目标是达到尽可能快的压缩和解压速度,同时减少对CPU的消耗;
在Snappy发布之后,建议采用Snappy算法(参考《HBase: The Definitive Guide》),具体可以根据实际情况对LZO和Snappy做过更详细的对比测试后再做选择。
如果建表之初没有压缩,后来想要加入压缩算法,可以通过alter修改schema
注意数据只是在硬盘上是压缩的,在内存里(memstore或blockcache)或网络传输的时候是没有压缩的
alter
使用方法:
如 修改压缩算法
disable 'table'alter 'table',{NAME=>'info',COMPRESSION=>'snappy'}enable 'table'
但是需要执行major_compact 'table' 命令之后 才会做实际的操作。
TTL
默认是 2147483647 即:Integer.MAX_VALUE 值大概是68年,默认TTL=>'FOREVER'
这个参数是说明该列族数据的存活时间,单位是s
这个参数可以根据具体的需求对数据设定存活时间,超过存过时间的数据将在表中不在显示,待下次major compact的时候再彻底删除数据
注意的是TTL设定之后 MIN_VERSIONS=>'0' 这样设置之后,TTL时间戳过期后,将全部彻底删除该family下所有的数据,如果MIN_VERSIONS 不等于0那将保留最新的MIN_VERSIONS个版本的数据,其它的全部删除,比如MIN_VERSIONS=>'1'届时将保留一个最新版本的数据,其它版本的数据将不再保存。
describe ‘table’
这个命令查看了create table 的各项参数或者是默认值
disable_all 'toplist.*'
disable_all 支持正则表达式,并列出当前匹配的表的如下:
toplist_a_total_1001toplist_a_total_1002toplist_a_total_1008toplist_a_total_1009toplist_a_total_1019toplist_a_total_1035...Disable the above 25 tables (y/n)? 并给出确认提示
drop_all
这个命令和disable_all的使用方式是一样的
hbase 表预分区——手动分区
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。
命令方式:
15个分区,hash切分
create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
也可以使用api的方式:
bin/hbase org.apache.hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f info
参数:
test_table是表名HexStringSplit 是split 方式-c 是分10个region-f 是family
可在UI上查看结果,如图:
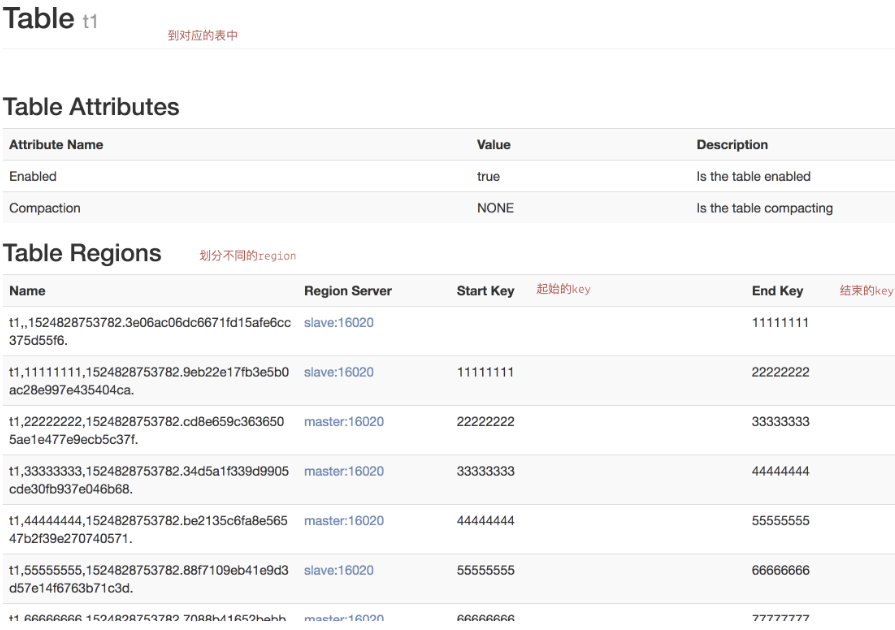
这样就可以将表预先分为15个区,减少数据达到storefile 大小的时候自动分区的时间消耗,并且还有以一个优势,就是合理设计rowkey 能让各个region 的并发请求平均分配(趋于均匀) 使IO 效率达到最高,但是预分区需要将filesize 设置一个较大的值,
设置哪个参数呢 hbase.hregion.max.filesize 这个值默认是10G 也就是说单个region 默认大小是10G
这个参数的默认值在0.90 到0.92到0.94.3各版本的变化:256M--1G--10G
但是如果MapReduce Input类型为TableInputFormat 使用hbase作为输入的时候,就要注意了,每个region一个map,如果数据小于10G 那只会启用一个map 造成很大的资源浪费,这时候可以考虑适当调小该参数的值,或者采用预分配region的方式,并将检测如果达到这个值,再手动分配region
行键设计
表结构设计
- 列族数量的设定
以用户信息为例,可以将必须的基本信息存放在一个列族,而一些附加的额外信息可以放在另一列族; - 行键的设计
语音详单:
13877889988-2015062513877889988-2015062513877889988-2015062613877889988-20150626138778899891387788998913877889989
——将需要批量查询的数据尽可能连续存放
CMS系统——多条件查询
尽可能将查询条件关键词拼装到rowkey中,查询频率最高的条件尽量往前靠
20150230-zhangsan-category…20150230-lisi-category…
(每一个条件的值长度不同,可以通过做定长映射来提高效率)(可以创建一张表来映射下)
参考:《hbase 实战》——详细讲述了facebook /GIS等系统的表结构设计

若有收获,就点个赞吧
0 人点赞
