分析
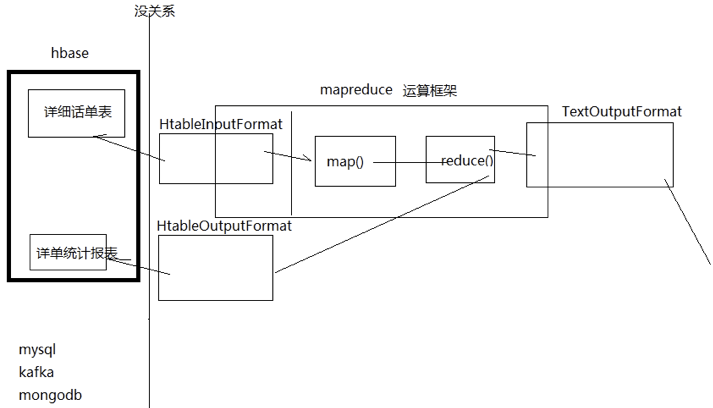
为什么需要用mapreduce去访问hbase的数据?
——加快分析速度和扩展分析能力
Mapreduce访问hbase数据作分析一定是在离线分析的场景下应用
代码
从Hbase中读取数据分析写入hdfs
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.io.ImmutableBytesWritable;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.hbase.mapreduce.TableMapper;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class HbaseReader {public static String t_user_info = "t_user_info";//这边泛型决定出去static class HdfsSinkMapper extends TableMapper<Text, NullWritable> {//key代表row key,value代表这一行结果@Overrideprotected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {byte[] bytes = key.copyBytes();//把row key变为stringString rowkey = new String(bytes);//从这行中取数据//注意bash_info这个列族下面的username这个列要有,不然会报空指针异常byte[] usernameBytes = value.getValue("base_info".getBytes(), "username".getBytes());String username = new String(usernameBytes);context.write(new Text(rowkey + "\t" + username), NullWritable.get());}}//reduce从map中拿数据static class HdfsSinkReducer extends Reducer<Text, NullWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {context.write(key, NullWritable.get());}}public static void main(String[] args) throws Exception {Configuration conf = HBaseConfiguration.create();conf.set("hbase.zookeeper.quorum", "master:2181,slave:2181");Job job = Job.getInstance(conf);job.setJarByClass(HbaseReader.class);// job.setMapperClass(HdfsSinkMapper.class);Scan scan = new Scan();//初始化TableMapReduceUtil.initTableMapperJob(t_user_info, scan, HdfsSinkMapper.class, Text.class, NullWritable.class, job);job.setReducerClass(HdfsSinkReducer.class);FileOutputFormat.setOutputPath(job, new Path("/Users/jdxia/Desktop/website/hdfs/output"));job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);job.waitForCompletion(true);}}
从hdfs中读取数据写入Hbase
测试数据
13902070000 www.baidu.com beijing13902070006 www.google.com.hk beijing13902070012 www.google.com.hk shanghai13902070018 www.baidu.com shanghai13902070024 www.baidu.com guanzhou13902070030 www.baidu.com tianjin
创建表
create 'flow_fields_import', 'info'
bean代码
import org.apache.hadoop.io.Text;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;public class FlowBean implements WritableComparable<FlowBean> {private Text phone;private Text url;public FlowBean() {}public FlowBean(Text phone, Text url) {super();this.phone = phone;this.url = url;}public FlowBean(String phone, String url) {super();this.phone = new Text(phone);this.url = new Text(url);}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(phone.toString());out.writeUTF(url.toString());}@Overridepublic void readFields(DataInput in) throws IOException {phone = new Text(in.readUTF());url = new Text(in.readUTF());}@Overridepublic String toString() {final StringBuilder sb = new StringBuilder("{");sb.append("\"phone\":").append(phone);sb.append(",\"url\":").append(url);sb.append('}');return sb.toString();}public Text getPhone() {return phone;}public void setPhone(Text phone) {this.phone = phone;}public Text getUrl() {return url;}public void setUrl(Text url) {this.url = url;}@Overridepublic int compareTo(FlowBean o) {return this.phone.toString().compareTo(o.getPhone().toString());}}
mapreduce代码
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.HColumnDescriptor;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.HBaseAdmin;import org.apache.hadoop.hbase.client.Mutation;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.io.ImmutableBytesWritable;import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;import org.apache.hadoop.hbase.mapreduce.TableReducer;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import java.io.IOException;/*** User: jdxia* Date: 2018/7/25* Time: 15:40*/public class HbaseSinker {public static String flow_fields_import = "flow_fields_import";public static class HbaseSinkMrMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = line.split(" ");String phone = fields[0];String url = fields[1];FlowBean bean = new FlowBean(phone, url);context.write(bean, NullWritable.get());}}public static class HbaseSinkMrReducer extends TableReducer<FlowBean, NullWritable, ImmutableBytesWritable> {@Overrideprotected void reduce(FlowBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {Put put = new Put(key.getPhone().getBytes());put.add("f1".getBytes(), "url".getBytes(), key.getUrl().getBytes());context.write(new ImmutableBytesWritable(key.getPhone().getBytes()), put);}}public static void main(String[] args) throws Exception {Configuration conf = HBaseConfiguration.create();conf.set("hbase.zookeeper.quorum", "master:2181,slave1:2181,slave2:2181");HBaseAdmin hBaseAdmin = new HBaseAdmin(conf);boolean tableExists = hBaseAdmin.tableExists(flow_fields_import);if (tableExists) {hBaseAdmin.disableTable(flow_fields_import);hBaseAdmin.deleteTable(flow_fields_import);}HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(flow_fields_import));HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("f1".getBytes());desc.addFamily(hColumnDescriptor);hBaseAdmin.createTable(desc);Job job = Job.getInstance(conf);job.setJarByClass(HbaseSinker.class);job.setMapperClass(HbaseSinkMrMapper.class);TableMapReduceUtil.initTableReducerJob(flow_fields_import, HbaseSinkMrReducer.class, job);FileInputFormat.setInputPaths(job, new Path("/Users/jdxia/Desktop/data.txt"));job.setMapOutputKeyClass(FlowBean.class);job.setMapOutputValueClass(NullWritable.class);job.setOutputKeyClass(ImmutableBytesWritable.class);job.setOutputValueClass(Mutation.class);job.waitForCompletion(true);}}

若有收获,就点个赞吧
0 人点赞
