设计
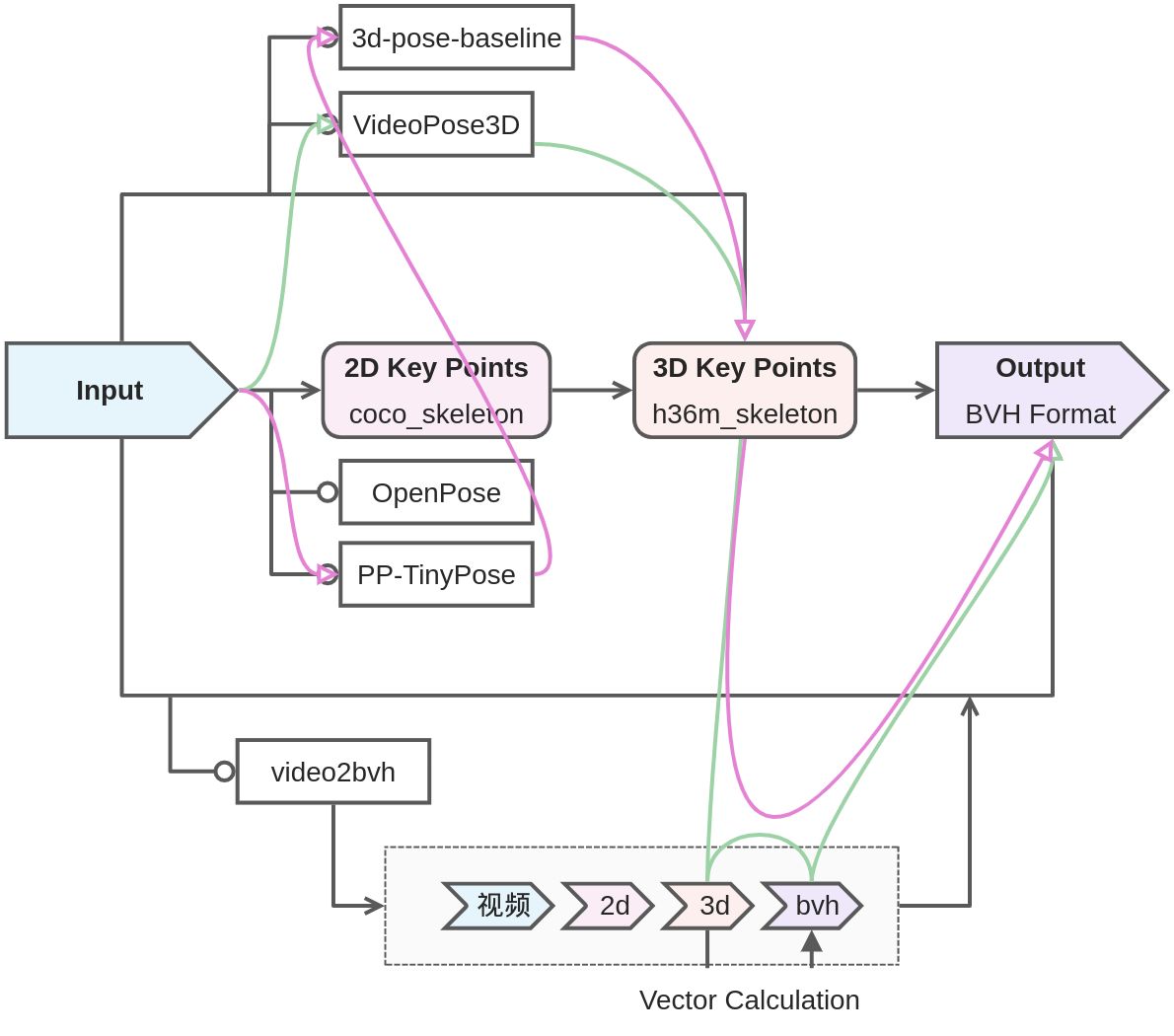
实践过程
绿线
Video to Pose2D
一开始走了点弯路,根据我们的需求,应该使用Inference in the wild这个部分的代码,而这部分代码主要使用了Facebook的[Detectron2](https://github.com/facebookresearch/Detectron),当然如何使用在VideoPose3D的[INFERENCE.md](https://github.com/facebookresearch/VideoPose3D/blob/main/INFERENCE.md)中也有详细说明。
基本上这个步骤就是VideoPose3D 实践记录中写的那样,由于它甚至提供了训练好的模型,所以直接用就行。需要注意的是,一定要写对input文件的路径,包括在 to Pose2D 和 to Pose3D 中这个地方都是很容易出问题的地方。
配置好环境即可推理。
而这个步骤是整个流程中最慢的,在Colab的GPU加速下只能跑 2fps ,可能是我的打开方式不太对。
-
下一步可能会尝试把这一步换成用~~tinypose~~实现。Pose2D to Pose3D
实际上这一步的开销并不大,主要原理是对二维点进行深度拟合。
根据在VideoPose3D的[INFERENCE.md](https://github.com/facebookresearch/VideoPose3D/blob/main/INFERENCE.md)进行Step 4和Step 5,向上面一步提到的那样,注意路径问题即可推理。
添加--viz-export字段来导出关键节点的空间坐标数据,是numpy的.npy文件。通过这个文件我们进行下一步的转写.bvhPose3D to bvh
首先需要了解BVH 格式 | Biovision Hierarchy format,才能知道接下来要干什么。
我直接借鉴了video2bvh这个项目的代码。可惜的是,这个项目中并没有我支持的骨架定义,所以我模仿着自己写了一个,这个过程是非常痛苦的。因为上一步得到的空间坐标是如何定义的并没有在官方文件中给出,我只能自己一帧一帧的用Matplotlib画出三视图来识别!这实在是太痛苦了……索性最后还是整出来了,虽然我发现它是倾斜的……
 |
针对这张图,有几个需要说明的地方: 1. 节点名称显然是我自己取的,在 video2bvh提供的代码中,最好左右和EndSite有明显的命名特征;2. 空间坐标系是没有严格规定的,主要体现在一开始对 T-Pose的定义,只需要保证T-Pose的定义和后续对子空间坐标系的定义匹配即可;3. 那个橙色的地方意思是鼻子是凸出来的! |
|---|---|
实现效果

子任务文章
VideoPose3D 实践记录
BVH 格式 | Biovision Hierarchy format
PP-TinyPose 实践记录

若有收获,就点个赞吧
0 人点赞
