[0.x] 前言 🎓
[0.1.x] 课程相关
:::tips
因为我只能找到 17 年的视频,所以是跟着 17 年的版本学。 ::: :::info Course Website
Course Video
Course Description
Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image classification, localization and detection. Recent developments in neural network (aka “deep learning”) approaches have greatly advanced the performance of these state-of-the-art visual recognition systems. This course is a deep dive into the details of deep learning architectures with a focus on learning end-to-end models for these tasks, particularly image classification. During the 10-week course, students will learn to implement and train their own neural networks and gain a detailed understanding of cutting-edge research in computer vision. Additionally, the final assignment will give them the opportunity to train and apply multi-million parameter networks on real-world vision problems of their choice. Through multiple hands-on assignments and the final course project, students will acquire the toolset for setting up deep learning tasks and practical engineering tricks for training and fine-tuning deep neural networks.
Assignments
-
[0.2.x] 学习日志
:::tips Course
01020304050607080910111213141516
Assignments
010203 :::[0.3.x] 学习资源
:::info Reference
Lab
- none now
:::
[1.x] 课程笔记 📖
Lecture 1: Introduction to Convolutional Neural Networks for Visual Recognition
🔗 Video
🔗 Slides
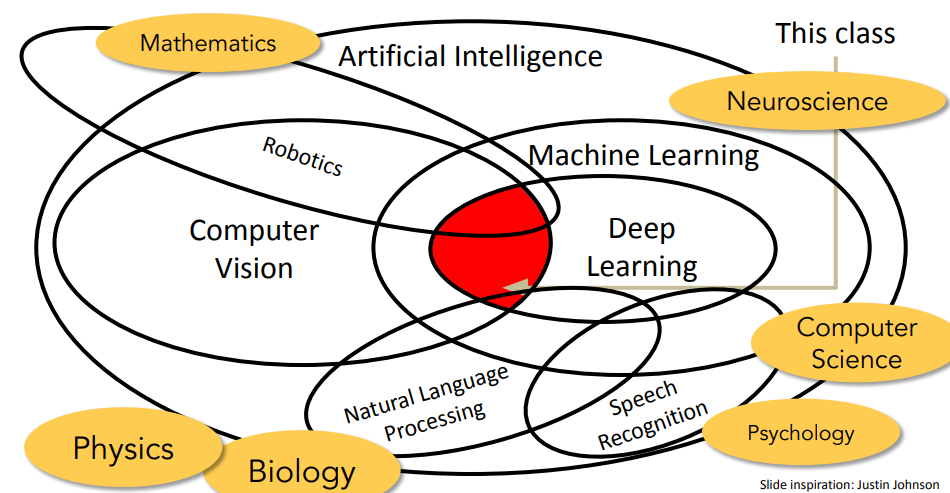
- 一些早期的关于 CV 的思考
- 早期对如何表示物体,超越「Block World」的表示方法
人们意识到直接识别物体比较困难,于是想到了分割图形(image segmentation)——即先做将像素分组
- 启发:视觉识别的重点可以从识别对象的一些具有识别力和不易变化的部分开始
- 总的而言对象识别是 CV 领域的一个重要话题
- 该课程重点为卷积神经网络(Convolutional Neural Network / CNN)
- 具体着眼点为图像分类问题(image classification)
- 也将涉及对象检测(object detection)、图像字幕(image captioning)等问题


Lecture 2: Image Classification Pipeline
🔗 Video
🔗 Slides
🔗 CIFAR-10 & CIFAR-100
前置:
- 语义鸿沟(semantic gap)
Data-Driven Approach:
- Collect a dataset of images and labels;
- Use Machine Learning to train a classifier;
- Evaluate the classifier on new images;
- 得到的模型有两个核心 API:一个用于训练(train),一个用于预测(predict)
- 一般情况下,我们不介意训练时间长,但希望预测效率高
| 🔗 CIFAR-10 Data Set
Distance Metric to compare images


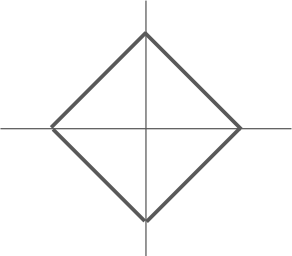
L1 (Manhattan) distance: (stupid in most cases)
![📔 [大一暑假] Stanford CS 231N - Deep Learning for Computer Vision - 图10](/uploads/projects/isshikixiu@codes/ec749606f7caeb125dc9de25f56baa2b.svg)
*如果图像旋转,预测结果会发生改变
L2 (Euclidean ) distance: (better by comparison)
![📔 [大一暑假] Stanford CS 231N - Deep Learning for Computer Vision - 图13](/uploads/projects/isshikixiu@codes/7049ea9d99cc4d814d4a6bfcf5c8be2a.svg)
🔗K-Nearest Neighbors [ 🔗 Interactive Demo ] Instead of copying label from nearest neighbor, take majority vote from K closest points.
- 当然,这种通过比较“距离”的分类方案并不仅限于图片等,对于任何需要分类的数据,例如文本,只要能定义能够量化的“距离”以及一系列相应的规则,就能使用这种方法来进行分类。
- 然而,K-临近算法在图像分类上几乎不怎么使用,主要是因为它实际使用起来,预测效率较低;且“距离度量”并不非常适合图像处理(它无法完整描述图像上的距离信息或图像之间的差异);此外它还有一个比较严重的问题:🔗维数灾难(curse of dimensionality)(因为只有训练样本足够密集,K-临近算法才能正常运行)。
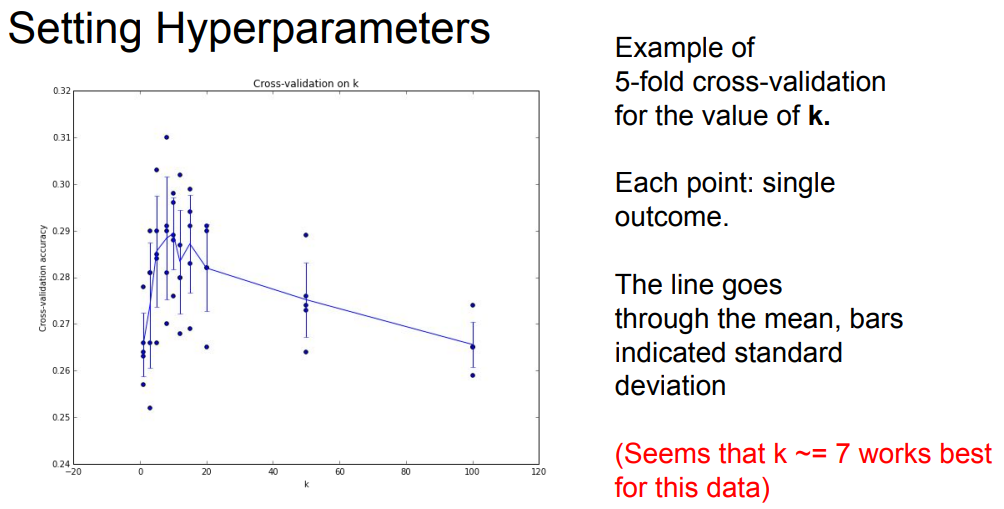
Hyperparameters: choices about the algorithm that we set rather than learn.
- eg: best k to use; best distance to use (L1/L2);
Setting Hyperparameters (调参)


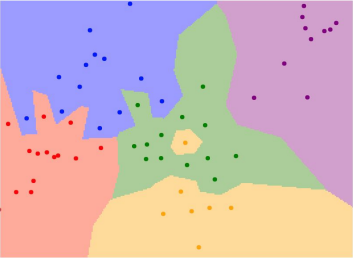

Linear Classification Parametric Approach
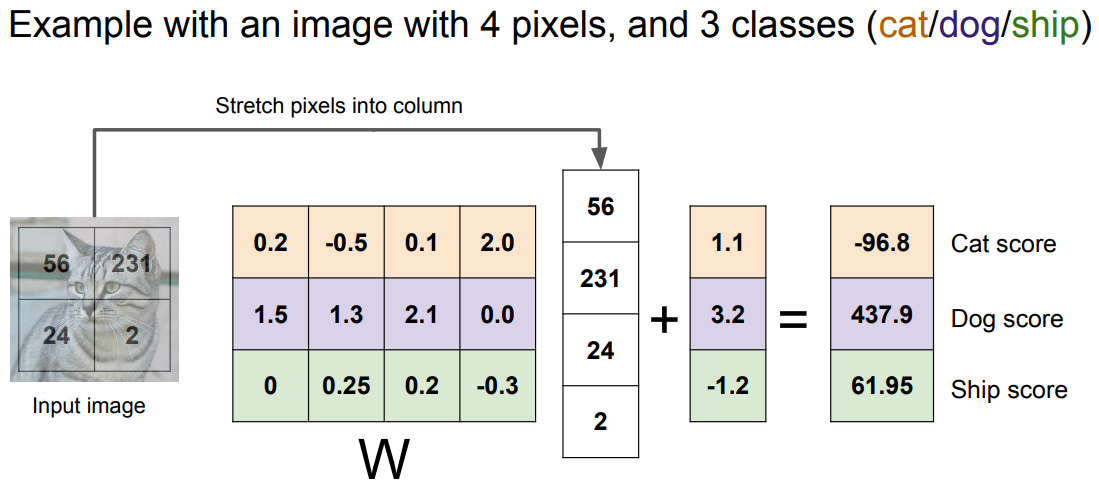
![📔 [大一暑假] Stanford CS 231N - Deep Learning for Computer Vision - 图19](/uploads/projects/isshikixiu@codes/82b709d7f8ae9b104c4b2e9d907c8b4b.svg)
- 即,我们构造一个函数,输入包含图像数据
和权重参数
,满足其计算结果为各个类别的预测得分
- 最终得到一个模版,它将尝试性地适应该类里尽可能多的样本
- 从这种角度来理解就很容易发现,单一的线性分类具有局限性,例如对于多模态的数据,使用单一的线性分类可能会比较吃力。


Lecture 3: Loss Functions and Optimization
- Linear classifier is an example of parametric classifier.
我们可以这样理解 Linear Classifation 中的
:矩阵中的每一个参数表示了每一个像素点(单个颜色通道)对于识别某个类的贡献权重。
A loss function that quantifies our unhappiness with the scores across the training data, tells how good our current classifier is.
[2.x] 作业笔记 📖
Assignment 1

若有收获,就点个赞吧
0 人点赞
