问题展示:
(1)将req.html页面的请求方式修改为get
<form action="/request-demo/req2" method="get"><input type="text" name="username"><br><input type="password" name="password"><br><input type="checkbox" name="hobby" value="1"> 游泳<input type="checkbox" name="hobby" value="2"> 爬山 <br><input type="submit"></form>
(2)在Servlet方法中获取参数,并打印
(3)启动服务器,页面上输入中文参数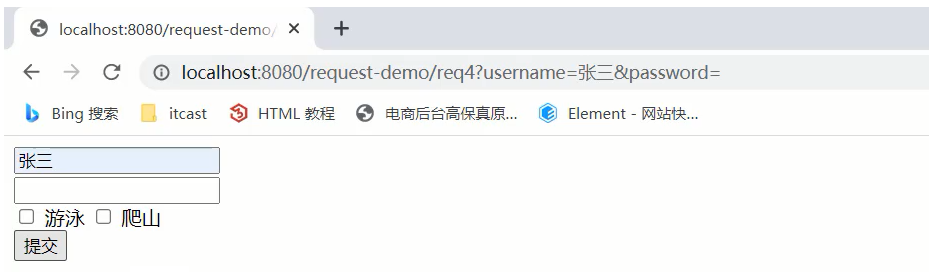
(4)查看控制台打印内容
(5)把req.html页面的请求方式改成post,再次发送请求和中文参数
(6)查看控制台打印内容,依然为乱码
通过上面的案例,会发现,不管是GET还是POST请求,在发送的请求参数中如果有中文,在后台接收的时候,都会出现中文乱码的问题。具体该如何解决呢?
1 POST请求解决方案
- 分析出现中文乱码的原因:
- POST的请求参数是通过request的getReader()来获取流中的数据
- TOMCAT在获取流的时候采用的编码是ISO-8859-1
- ISO-8859-1编码是不支持中文的,所以会出现乱码
- 解决方案:
- 页面设置的编码格式为UTF-8
- 把TOMCAT在获取流数据之前的编码设置为UTF-8
- 通过request.setCharacterEncoding(“UTF-8”)设置编码,UTF-8也可以写成小写
- 修改后的代码为:

重新发送POST请求,就会在控制台看到正常展示的中文结果。
至此POST请求中文乱码的问题就已经解决,但是这种方案不适用于GET请求,这个原因是什么呢,咱们下面再分析。
2 GET请求解决方案
上面说到POST请求的中文乱码解决方案为什么不适用GET请求 为什么?
- GET请求获取请求参数的方式是request.getQueryString()
- POST请求获取请求参数的方式是request.getReader()
- request.setCharacterEncoding(“utf-8”)是设置request处理流的编码
-
GET请求不能用设置编码的方式来解决中文乱码问题,那问题又来了,如何解决GET请求的中文乱码呢? (现在的版本没有乱码问题)
1. 首先我们需要先分析下GET请求出现乱码的原因:
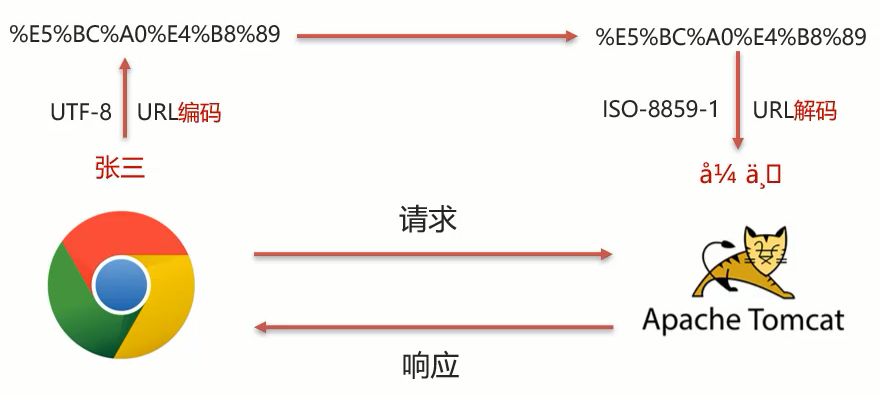
(1)浏览器通过HTTP协议发送请求和数据给后台服务器(Tomcat)
(2)浏览器在发送HTTP的过程中会对中文数据进行URL==编码==
(3)在进行URL编码的时候会采用页面标签指定的UTF-8的方式 进行编码,张三编码后的结果为%E5%BC%A0%E4%B8%89
(4)后台服务器(Tomcat)接收到%E5%BC%A0%E4%B8%89后会默认按 照ISO-8859-1进行URL==解码==
(5)由于前后编码与解码采用的格式不一样,就会导致后台获取到的数据 为乱码。思考: 如果把req.html页面的标签的charset属性改成ISO-8859-1,后台不做操作,能解决中文乱码问题么?
答案是否定的,因为ISO-8859-1本身是不支持中文展示的,所以改了标签的charset属性后,会导致页面上的中文内容都无法正常展示。
=URL编码==和==URL解码==,什么是URL编码,什么又是URL解码呢?
URL编码
这块知识我们只需要了解下即可,具体编码过程分两步,分别是:
(1)将字符串按照编码方式转为二进制
(2)每个字节转为2个16进制数并在前边加上%
张三按照UTF-8的方式转换成二进制的结果为:
1110 0101 1011 1100 1010 0000 1110 0100 1011 1000 1000 1001
这个结果是如何计算的?
使用http://www.mytju.com/classcode/tools/encode_utf8.asp,输入张三
就可以获取张和三分别对应的10进制,然后在使用计算器,选择程序员模式,计算出对应的二进制数据结果: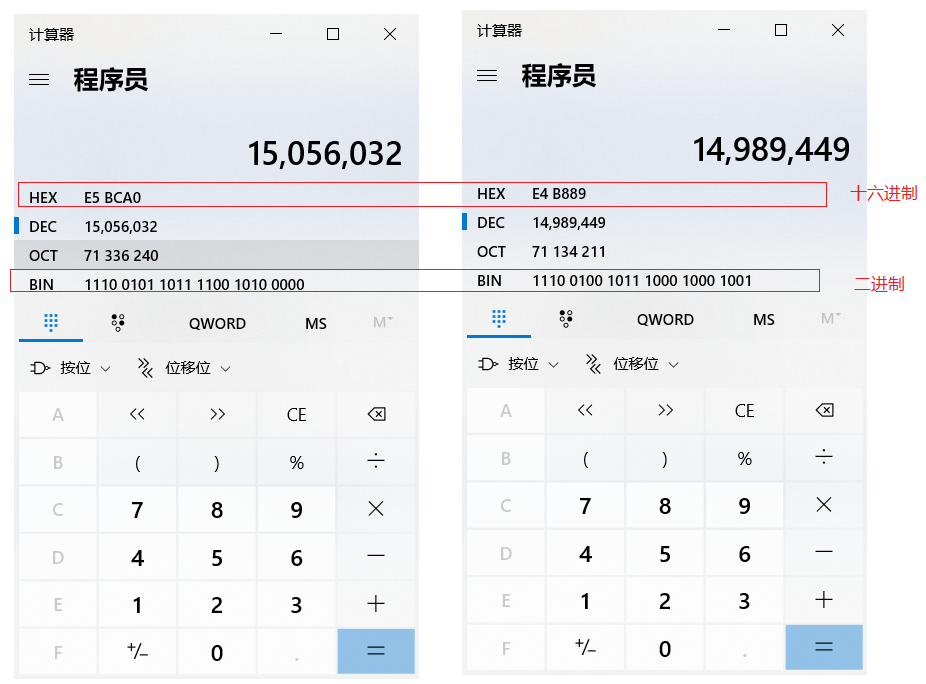
在计算的十六进制结果中,每两位前面加一个%,就可以获取到%E5%BC%A0%E4%B8%89。
当然你从上面所提供的网站中就已经能看到编码16进制的结果了:
但是对于上面的计算过程,如果没有工具,纯手工计算的话,相对来说还是比较复杂的,我们也不需要进行手动计算,在Java中已经为我们提供了编码和解码的API工具类可以让我们更快速的进行编码和解码:
编码:
java.net.URLEncoder.encode(“需要被编码的内容”,”字符集(UTF-8)”)
解码:
java.net.URLDecoder.decode(“需要被解码的内容”,”字符集(UTF-8)”)
接下来咱们对张三来进行编码和解码
到这,我们就可以分析出GET请求中文参数出现乱码的原因了
浏览器把中文参数按照UTF-8进行URL编码
- Tomcat对获取到的内容进行了ISO-8859-1的URL解码
-
2. 清楚了出现乱码的原因,接下来我们就需要想办法进行解决
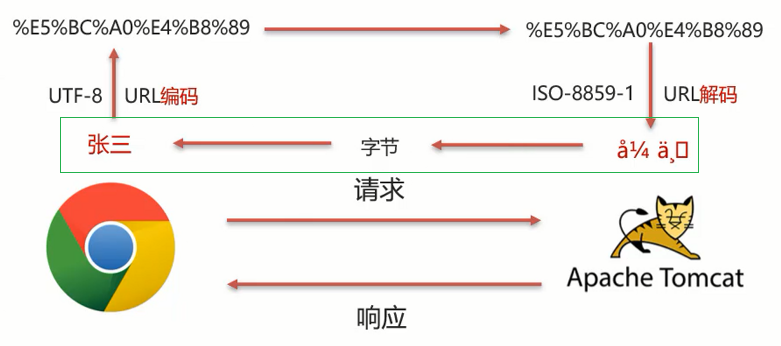
从上图可以看住,
在进行编码和解码的时候,不管使用的是哪个字符集,他们对应的%E5%BC%A0%E4%B8%89是一致的
- 那他们对应的二进制值也是一样的,为:
- 1110 0101 1011 1100 1010 0000 1110 0100 1011 1000 1000 1001
- 为所以我们可以考虑把å¼ ä¸转换成字节,在把字节转换成张三,在转换的过程中是它们的编码一致,就可以解决中文乱码问题。
具体的实现步骤为:
1.按照ISO-8859-1编码获取乱码å¼ ä¸对应的字节数组
2.按照UTF-8编码获取字节数组对应的字符串
public static void main(String[] args) throws UnsupportedEncodingException {String username = "张三";//1. URL编码String encode = URLEncoder.encode(username, "utf-8");System.out.println(encode);//2. URL解码String decode = URLDecoder.decode(encode, "ISO-8859-1");System.out.println(decode); //此处打印的是对应的乱码数据//3. 转换为字节数据,编码byte[] bytes = decode.getBytes("ISO-8859-1");for (byte b : bytes) {System.out.print(b + " ");}//此处打印的是:-27 -68 -96 -28 -72 -119//4. 将字节数组转为字符串,解码String s = new String(bytes, "utf-8");System.out.println(s); //此处打印的是张三}
说明:在第18行中打印的数据是-27 -68 -96 -28 -72 -119和张三转换成的二进制数据1110 0101 1011 1100 1010 0000 1110 0100 1011 1000 1000 1001为什么不一样呢?
其实打印出来的是十进制数据,我们只需要使用计算机换算下就能得到他们的对应关系,如下图: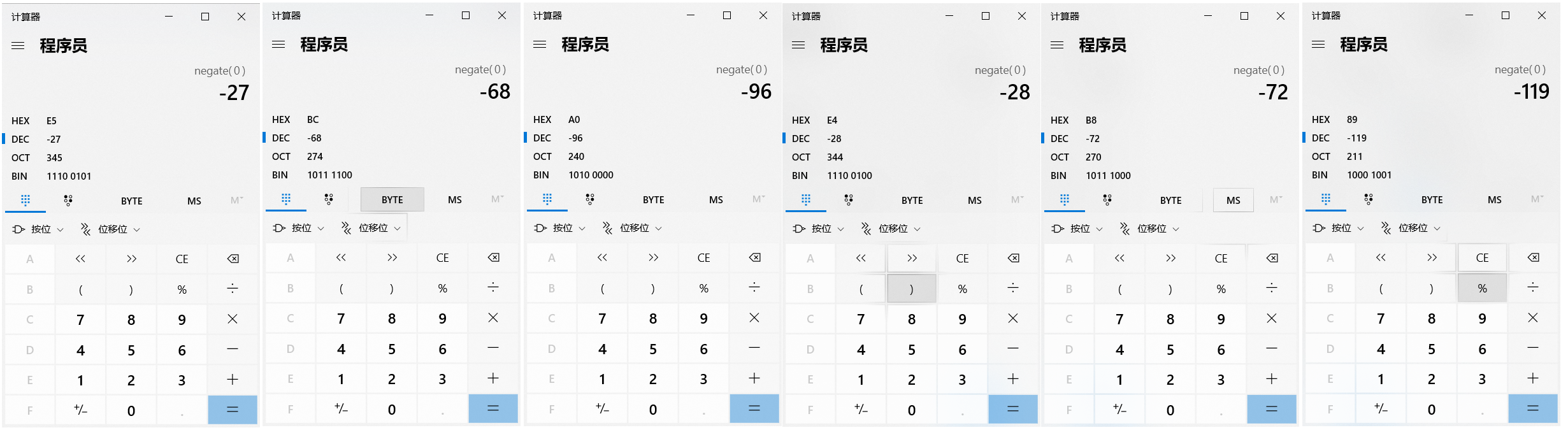
至此对于GET请求中文乱码的解决方案,我们就已经分析完了,最后在代码中去实现下:
/*** 中文乱码问题解决方案*/@WebServlet("/req4")public class RequestDemo4 extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {//1. 解决乱码:POST,getReader()//request.setCharacterEncoding("UTF-8");//设置字符输入流的编码//2. 获取usernameString username = request.getParameter("username");System.out.println("解决乱码前:"+username);//3. GET,获取参数的方式:getQueryString// 乱码原因:tomcat进行URL解码,默认的字符集ISO-8859-1/* //3.1 先对乱码数据进行编码:转为字节数组byte[] bytes =username.getBytes(StandardCharsets.ISO_8859_1);//3.2 字节数组解码username = new String(bytes, StandardCharsets.UTF_8);*/username = new String(username.getBytes(StandardCharsets.ISO_8859_1),StandardCharsets.UTF_8);System.out.println("解决乱码后:"+username);}@Overrideprotected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {this.doGet(request, response);}}
注意
- 把request.setCharacterEncoding(“UTF-8”)代码注释掉后,会发现GET请求参数乱码解决方案同时也可也把POST请求参数乱码的问题也解决了
- 只不过对于POST请求参数一般都会比较多,采用这种方式解决乱码起来比较麻烦,所以对于POST请求还是建议使用设置编码的方式进行。
另外需要说明一点的是==Tomcat8.0之后,已将GET请求乱码问题解决,设置默认的解码方式为UTF-8==
小结
- 中文乱码解决方案
- POST请求和GET请求的参数中如果有中文,后台接收数据就会出现中文乱码问题GET请求在Tomcat8.0以后的版本就不会出现了
- POST请求解决方案是:设置输入流的编码
- request.setCharacterEncoding(“UTF-8”);
注意:设置的字符集要和页面保持一致
- 通用方式(GET/POST):需要先解码,再编码
- new String(username.getBytes(“ISO-8859-1”),”UTF-8”);
- URL编码实现方式:
- 编码: URLEncoder.encode(str,”UTF-8”);
- 解码: URLDecoder.decode(s,”ISO-8859-1”);

若有收获,就点个赞吧
0 人点赞

{kind=link}