1. Tutorial
Awk operates on one “record” at a time, which is each line by default. Each “field” in a record is separated by a space (by default) or another defined separator (using the -F option).
Awk Program consists of a sequence of pattern-action statements “pattern { action statements }“.
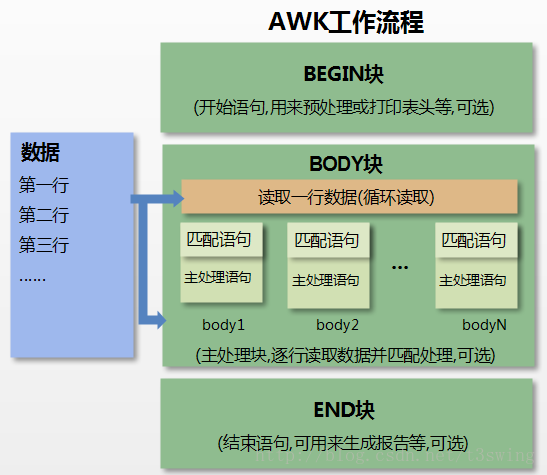
图片引自 [http://www.runoob.com/w3cnote/awk-work-principle.html](http://www.runoob.com/w3cnote/awk-work-principle.html)<br />
In a pattern-action statement either the pattern or the action may be missing.
Awk 主要将 “行” 内容,按照设定的 field-separator 分割, $0 为整行内容, $1 ~ $N 为分割后的各部分。
2. pattern
2.1 missing
If the pattern is missing, the action is applied to every single line of input: print $0
2.2 BEGIN
BEGIN is a special kind of pattern which is not tested against the input.It is executed before any input is read.
# 行结束时增加一行空行awk 'BEGIN {ORS="\n\n"};1'
2.3 END
END is another special kind of pattern which is not tested against the input. It is executed when all the input has been exhausted.
# 打印总行数awk '1; END {print NR}'
2.4 判断
awk 可以在 pattern 中使用多种判断方式,在满足判断条件后,再执行 action 动作。
- if 判断
if (条件) {动作}
awk 'if ($6>40) {print}'
- 与
&&
- 正则匹配
$1~RegEx
$1!~RegEx
# 正则匹配以 head 起始的行,若匹配,则打印该行awk '/^head/ {print}'awk '$0~/^head/'# 正则匹配不是以 # 起始的行,若匹配,则打印该行awk '!/^#/ {print}'awk '$0!~/^#/'
3. actions
3.1 missing
A missing action is equivalent to {print $0}
3.2 printf()
ORS does not get appended at the end of printf(), so we have to print the newline (\n) character explicitly.
4. Special Variable
4.1 $0
The entire line.
awk 'BEGIN {ORS="\n\n"}; {print $0}'
4.2 NF
NF - Number of Fields. Also may be considered as **Column**.
It contains the number of fields the current line was split into.
仅在非空行输入时,在尾部增加一行空行
awk 'NF {print $0 "\n"}'
4.3 RS & ORS
RS: The input record separator, by default a newline.
ORS:Every print statement in Awk is silently followed by an ORS - Output Record Separator variable, which is a newline by default.
# Concatenate every 5 lines of input with a commaawk ' ORS=NR%5 ? "," : "\n" {pre="%s%s" % (pre,$0); print pre} '
4.4 FS & OFS
FS: The input field separator, a space by default.
OFS: The output field separator, a space by default.
4.5 FNR
FNR - File Line Number
FNR variable contains the current line for each file separately.
For example, if this one-liner was called on two files, one containing 10 lines, and the other 12, it would number lines in the first file from 1 to 10, and then resume numbering from one for the second file and number lines in this file from 1 to 12. FNR gets reset from file to file.
4.6 NR
NR - Line Number. Also may be considered as **Row**.
It counts the input lines seen so far and does not get reset from file to file. For example, if it was called on the same two files with 10 and 12 lines, it would number the lines from 1 to 22 (10 + 12).
4.7 local variable — to be continued
# 1. Number only non-blank lines in filesawk 'NF { $0=++a " :"$0}; NF {print}'# 2. 输出field总和awk 'NF {for(i=1;i<NF;i++);s+=i}; END {print s+0}'awk '{total += NF}; END {print total+0}'# 3. Print the total number of lines containing word "Beth"awk '/Beth/ {n++}; END {print n+0}'# 4. Print the last field of each lineawk 'NF {print $NF}'# 5. Print the last field of last lineawk ';END {print $NF}'# 6. Print every line with more than 4 fields.awk 'NF > 4;'# 7. Print every line where the value of the last field is greater than 4.awk '$NF > 4;'# 8. Remove duplicate, nonconsecutive linesawk '!a[$0]++' # It registers the lines seen in the associative-array "a" (arrays are always associative in Awk) and at the same time tests if it had seen the line before.# The same as belows. Note that an empty statement "a[$0]" creates an element in the array.awk '!($0 in a) { a[$0]; print }'
4.7.1 awk的数组
在awk中,数组都是**关联数组**.
所谓关联数组就是每一个数组元素实际都包含两部分:key和value,类似python里面的**字典。在awk中数组之间是无序的,一个数组的key值是数值,例如1,2,3,并不代表该数组元素在数组中的出现的位置。
awk中的数组有以下特性:**
- 数组无需定义,直接使用
- 数组自动扩展
- 下标可以是数值型或者字符串型
元素赋值: arr[0]=123 arr[“one”]=123
数组长度: length(arr) — length默认返回 $0 的长度
数组遍历:
# 在action中,遍历数组arrfor( key in arr) print key,arr[key]# Note: 此处用的是 arr[key] 而非 arr[$key]# 对4.6例8进行扩展,每次符合条件,即遍历打印数组awk '!($0 in a) { a[$0]; for (key in a) print key,a[key]}'# 通过下标访问数组,起始index为1# 复杂式,建议先用大括号扩住echo "this is a value of arr" | awk '{ {split($0, arr, " ")}; for(i=1;i<=length(arr);i++){print arr[i]} }'
上例中,隐含了一个 由string创建数组 的方法:split(Str, Arr, separator-Regex)
It splits string Str into fields by regular expression Regex and puts the fields in array Arr.
The fields are placed in Arr[1], Arr[2], …, Arr[N]. The split() function itself returns the number of fields the string was split into.
echo "abc**def**haha**xixi" | awk '{n=split($0, arr, "\*{2}")}; { for(i=1; i<=n;i++){print arr[i]} }'
判断一个元素是否在数组中: if(k in arr)
删除数组元素:delete arr[key]
删除整个数组:delete arr
复杂例子:统计 当前TCP各链接状态的 总数
netstat -n|awk '/^tcp/ {++arr[$NF]} END {for(state in arr)print state,arr[state]}'
5. Functions
5.1 sub(regex, repl, [string])
This function substitutes the first instance of regular expression “regex” in string “string” with the string “repl”. If “string” is omitted, variable $0 is used.
# convert CRLF to LFawk '{sub(/\r$/, ""); print}'# convert LF to CRLFawk '{sub(/$/, "\r"); print}'# Delete leading whitespace (spaces and tabs) from the beginning of each lineawk '{sub(/^[ \t]+/, ""); print}'# Delete trailing whitespace (spaces and tabs) from the end of each lineawk '{sub(/[ \t]$+/, ""); print}'# Delete both leading and trailing whitespaces from each lineawk '{gsub(/^[ \t]+|[ \t]+$/, ""); print}' # gsub is a global sub as many as possible# Insert 5 blank spaces at beginning of each line.awk '{sub(/^/, " "); print}'# Substitute "foo" with "bar" only on lines that contain "baz".awk '/baz/ { gsub(/foo/, "bar") }; { print }'# Substitute "foo" with "bar" only on lines that do not contain "baz".awk '!/baz/ { gsub(/foo/, "bar") }; { print }'# Change "scarlet" or "ruby" or "puce" to "red".awk '{gsub(/scarlet|ruby|puce/, "red"); print}'
An & in the replacement text is replaced with the text that was actually matched.
# Insert a string of specific length at a certain character position (insert 49 x's after 6th char)gawk --re-interval 'BEGIN { while(a++<49) s=s"x" }; {sub(/^.{6}/, "&"s)}; 1'
Error case:
gawk —re-interval ‘BEGIN { while(a++<49) s=s”x” }; {sub(/^.{6}/, “&”s); 1}’
只有独立的 pattern,1才等价于 print $0,该处被包在了 另外一个pattern中,应显式使用 print
5.2 getline
This function sets $0 to the next line (and also updates NF, NR, FNR variables).
5.3 Numeric Functions
| int(expr) | Truncates to integer |
|---|---|
| srand([expr]) | Uses expr as a new seed for the random number generator. If no expr is provided, the time of day is used. The return value is the previous seed for the random number generator. |
5.4 Bit Manipulations Functions
| and(v1, v2) | Return the bitwise AND of the values prov ided by v1 and v2. |
|---|---|
| or(v1, v2) | Return the bitwise OR of the v alues provided by v1 and v2. |
| xor(v1, v2) | Return the bitwise XOR of the values provided by v1 and v2. |
| lshift(val, count) | Return the value of val, shifted left by count bits. |
| rshift(val, count) | Return the value of val, shifted right by count bits. |
6. Tricky
- 将空格、Tab等删除
awk '{ $1=$1; print }'
when you change a field, Awk rebuilds the $0 variable. It takes all the fields and concats them, separated by OFS (single space by default). All the whitespace between fields is gone
- 对齐方式
# 居中awk '{ l=length(); s=int((79-l)/2); printf "%"(s+l)"s\n", $0 }'# 右对齐:Align all text flush right on a 79-column width.awk '{ printf "%79s\n", $0 }'
Print the line immediately before a line that matches “/regex/“ (but not the line that matches itself).
awk '/^#/ { {x = (x==""?"fist line":x)}; {print x} }; {x=$0}'
Print the line immediately after a line that matches “/regex/“ (but not the line that matches itself).
awk '/^#/ {print getline}'
- Print a section of file from regular expression to end of file.
awk '/regex/,0'
range pattern: ‘pattern1, pattern2’
It matches all the lines starting with a line that matches “pattern1” and continuing until a line matches “pattern2” (inclusive).
In this one-liner “pattern1” is a regular expression “/regex/“ and “pattern2” is just 0 (false). So this one-liner prints all lines starting from a line that matches “/regex/“ continuing to end-of-file (because 0 is always false, and “pattern2” never matches).
print lines 8 to 12
awk 'NR==8, NR==12'
Print line number 52.
awk 'NR==52 {print;exit}'
Delete all blank lines from a file. ```bash
利用了空行的NF为0的特点
awk NF
正则表达式匹配非空
awk ‘/./‘
<a name="5zzZJ"></a># 7. awk参数1. -F 指定分隔符```bash-F " " :默认会压缩所有前导空白,包括制表符和空格。-F " :" :当空格后跟一个冒号时作为分隔符。会压缩前导空格,但不会匹配制表符,更不会压缩制表符。-F "[ ]" :只表示一个空格,不压缩任何空白。-F "|" :指定竖线作为分隔符。-F ",[ \t]*|[ \t]+":逗号后跟0或多个空白,或者只有1或多个空白时作为分隔符。
8. awk不适合使用之处
8.1 Awk类似迭代器,无法随机访问某行
there is no seek() statement in Awk。
类似处理起始N行,最后几行的操作,Awk是不适合作为首层的。
8.2 写成较大规模awk脚本
awk的优势之处,我认为就在于其以极少的代码对文本的格式化处理:过滤 及 格式化。
复杂逻辑处理,我并不认为是awk的主战场,不妨把那部分工作,交给其他语言或工具。
9. 参考
主要参考 Catonmat Awk One-Liners Explained 系列文章:
https://catonmat.net/awk-one-liners-explained-part-one
https://catonmat.net/awk-one-liners-explained-part-two
https://catonmat.net/awk-one-liners-explained-part-three
https://catonmat.net/update-on-famous-awk-one-liners-explained
https://catonmat.net/awk-nawk-and-gawk-cheat-sheet
Awk1line文档

若有收获,就点个赞吧
0 人点赞
