- 1. Hashable
- 2. Ways to Build Dictionaries
- 3. Common Mapping Methods
- 4. Handling Missing Keys
- ☆3 若key不在self.keys()中,将调用 missing方法。
#☆2 如果key不在self.keys()中,将key转换为str形式,再次get,如果无法获取,将再次调用missing方法
#☆1 如果key是str类型,证明key不在self.keys()中,截止查询,抛异常
#☆4 在contains方法中,使用self.keys()而不是 key in self,避免递归调用 contains死循环 - 5. Variations of dict
- 6. Set
- 7. HashMap Theory under the dict and set
Hash tables are the
engines behind Python’s high-performance dicts.
Sets are implemented with hash tables as well.
A few questions will be involved:
Common dictionary methods
Special handling for missing keys
Variations of dict in the standard library
The set and frozenset types
How hash tables work
Implications of hash tables (key type limitations, unpredictable ordering, etc.)
1. Hashable
All mapping types in the standard library use the basic dict in their implementation, so they share the limitation that the keys must be hashable (the values need not be hashable, only the keys).
An object is hashable if it has a **hash value** which **never changes** during its lifetime (itneeds a hash() method), and can be compared to other objects (it needs an eq() method). Hashable objects which compare equal must have the same hash value. Hashability makes an object usable as a dictionary key and a set member, because these data structures use the hash value internally. All of Python’s immutable built-in objects are hashable; mutable containers (such as lists or dictionaries) are not. Objects which are instances of user-defined classes are hashable by default. They all compare unequal (except with themselves), and their hash value is derived from their id(). —— Python Glossary Hashable

According to the above saying, it is easy to see: The atomic immutable types ( str , bytes , numeric types) are all hashable. A frozen
set is always hashable, because its elements must be hashable by definition.
But a tuple is
hashable only if all its items are hashable.
In [7]: tpM1 = (1, 2, (3, 4))In [8]: tpM2 = (1, 2, [3, 4])In [9]: hash(tpM1)Out[9]: -2725224101759650258In [10]: hash(tpM2)---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-10-46e92fa07838> in <module>()----> 1 hash(tpM2)TypeError: unhashable type: 'list'
**User-defined types** are hashable by default because their hash value is their **id()** and
they all compare not equal. If an object implements a custom eq that takes into account its internal state, it may be hashable only if all its attributes are immutable.
2. Ways to Build Dictionaries
2.1 Dict Constructor
- dict(mapping) -> new dictionary initialized from a mapping object’s (key, value) pairs
- dict(iterable) -> new dictionary initialized as if via:
d = {}
for k, v in iterable:
d[k] = v
- dict(**kwargs) -> new dictionary initialized with the name=value pairs
in the keyword argument list. For example: dict(one=1, two=2)
>>> a = dict(one=1, two=2, three=3) # 3>>> b = {'one': 1, 'two': 2, 'three': 3} # 1>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 2>>> d = dict([('two', 2), ('one', 1), ('three', 3)]) # 2>>> e = dict({'three': 3, 'one': 1, 'two': 2}) # 2>>> a == b == c == d == eTrue
2.2 Dict Comprehensions
Dict Comprehensions with list of pairs(tuples/lists) dict.items()
>>> country_code = {country: code for code, country in DIAL_CODES}>>> {code: country.upper() for country, code in country_code.items()... if code < 66}
3. Common Mapping Methods

4. Handling Missing Keys
4.1 Handle Missing Keys with dict.setdefault
dict access with d[k] will raise error when k is not an existing key.d.get(k, default) is a more convenient way than handling KeyError.
D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D
tmp_list = my_dict.get(key, [])tmp_list.append(new_value)my_dict[key] = tmp_list||∨if key not in my_dict:my_dict[key] = []my_dict[key].append(new_value)||∨my_dict.setdefault(key, []).append(new_value)
4.2 Handle Missing Keys with collections.defaultdict
Work Theory: When instantiating a defaultdict , you provide a callable that is used to produce a default value whenever getitem is passed a nonexistent key argument.
dd = defaultdict(list)
if
new-key is not in dd , the expression dd['new-key'] does the following steps:
Calls list() to create a new list.
Inserts the list into dd using ‘new-key’ as key.
Returns a reference to that list.
The callable that produces the default values is held in an instance attribute called default_factory.
# 上述case可以进一步演化为如下代码my_dict = collections.defaultdict(list)my_dict[key].append(new_value)
The defaultfactory of a defaultdict is only invoked to provide default values for getitem calls, and not for the other methods. For example, if dd is a defaultdict , and k is a missing key, _dd[k] will call the default_factory to create a default value, but dd.get(k) still returns None.
4.2.1 **missing** method — actual default_factory working reason
This method is not defined in the base dict class, but dict is aware of it: If you subclass dict and provide a missing method, the standard dict.getitem will call it whenever a key is not found, instead of raising KeyError.
The missing method is just called by __getitem__ (d[k] operator) . This is why the default_factory of defaultdict works only with __getitem.
#!/usr/bin/python# -*- encoding:utf-8 -*-import sys#import crash_on_ipyclass StrKeyDict0(dict):def __missing__(self, key):if isinstance(key, str): #☆1raise KeyError(key)return self[str(key)] #☆2def get(self, key, default=None):try:return self[key] #☆3except KeyError:return defaultdef __contains__(self, key):return key in self.keys() or str(key) in self.keys() #☆4if __name__ == '__main__':d = StrKeyDict0([('one',1), ('(1, 2, 3)', 'N/A'), ('1', 'oneone')])>>> (1,2,3) in dFalse>>> (1, 2, 3) in dTrue
☆3 若key不在self.keys()中,将调用 missing方法。
#☆2 如果key不在self.keys()中,将key转换为str形式,再次get,如果无法获取,将再次调用missing方法
#☆1 如果key是str类型,证明key不在self.keys()中,截止查询,抛异常
#☆4 在contains方法中,使用self.keys()而不是 key in self,避免递归调用 contains死循环
Python3: dict.keys() returns dict_keys object
5. Variations of dict
5.1 collections.OrderedDict
Maintains keys in insertion order.popitem method of an OrderedDict pops the first item by default, but
if called as my_odict.popitem(last=True) , it pops the last item added.
5.2 collections.ChainMap
5.3 collections.Counter
A mapping that holds an integer count for each key. Updating an existing key adds to its count.
Important method:update : update the Counter’s keys’ occurrencemost_common : an ordered list of tuples with the n most common items and their counts
>>> ct = collections.Counter('abracadabra')>>> ctCounter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})>>> ct.update('aaaaazzz')>>> ctCounter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})>>> ct.most_common(2)[('a', 10), ('z', 3)]
5.4 collections.UserDict
UserDict does not inherit from dict , but has an internal dict instance, called data , which holds the actual items.
import collectionsclass StrKeyDict(collections.UserDict):def __missing__(self, key):if isinstance(key, str):raise KeyError(key)return self[str(key)]def __contains__(self, key):return str(key) in self.datadef __setitem__(self, key, item):self.data[str(key)] = item
setitem converts any key to a str .
5.5 Immutable Mappings
Mapping(internal, Mutable, dynamic) —-> types.MappingProxyType(ReadOnly, Immutable)
>>> from types import MappingProxyType>>> d = {1: 'A'}>>> d_proxy = MappingProxyType(d)>>> d_proxymappingproxy({1: 'A'})>>> d_proxy[1]'A'>>> d_proxy[2] = 'x'Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: 'mappingproxy' object does not support item assignment>>> d[2] = 'B'>>> d_proxymappingproxy({1: 'A', 2: 'B'})>>> d_proxy[2]'B'>>>
6. Set
6.1 Constructor
Empty Set: must use set() {} represents an empty dict.
Literal set like {1, 2, 3} is both faster and more readable than calling the constructor like set([1, 2, 3]).
6.2 Set Comprehensions
from unicodedata import name{chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), '')}
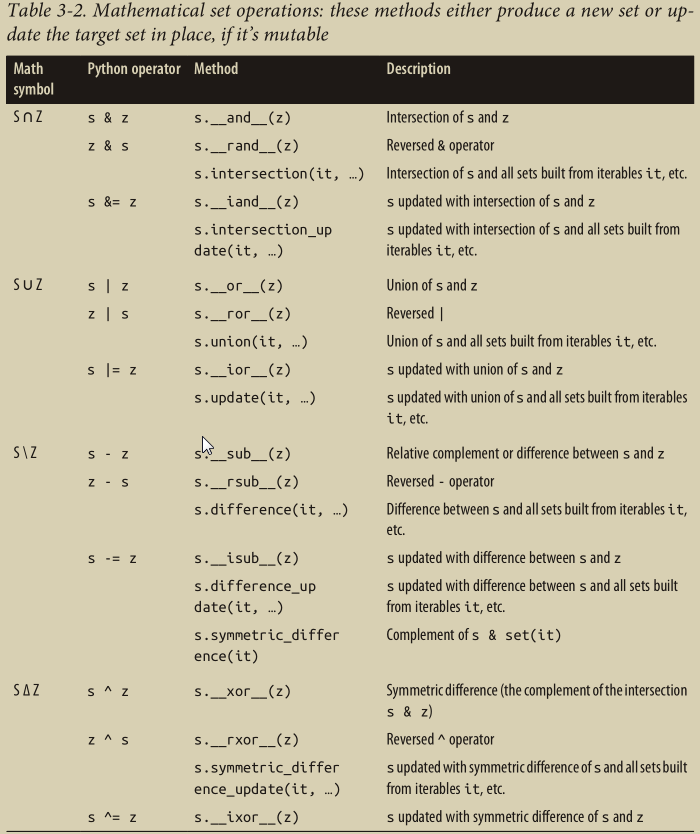
6.3 Set Operations

7. HashMap Theory under the dict and set
7.1 Hashes and Equality
The hash() built-in function works directly with built-in types and falls back to calling hash for user-defined types. If two objects compare equal, their hash values must also be equal, otherwise the hash table algorithm does not work. For example, because 1== 1.0 is true, hash(1) == hash(1.0) must also be true, even though the internal representation of an int and a float are very different.
7.2 Hash Table Algorithm
To fetch the value at mydict[search_key] , Python calls hash(search_key) to obtain the hash value of search_key and uses the least significant bits of that number as an offset to look up a bucket in the hash table (_the number of bits used depends on the current size of the table). If the found bucket is empty, KeyError is raised. Otherwise, the found bucket has an item—a found_key:found_value pair—and then Python checks whether search_key == found_key . If they match, that was the item sought: found_value is returned.
However, if search_key and found_key do not match, this is a hash collision. This happens because a hash function maps arbitrary objects to a small number of bits, and—in addition—the hash table is indexed with a subset of those bits. In order to resolve the collision, the algorithm then takes different bits in the hash, massages them in a particular way, and uses the result as an offset to look up a different bucket. If that is empty, KeyError is raised; if not, either the keys match and the item value is returned, or the collision resolution process is repeated
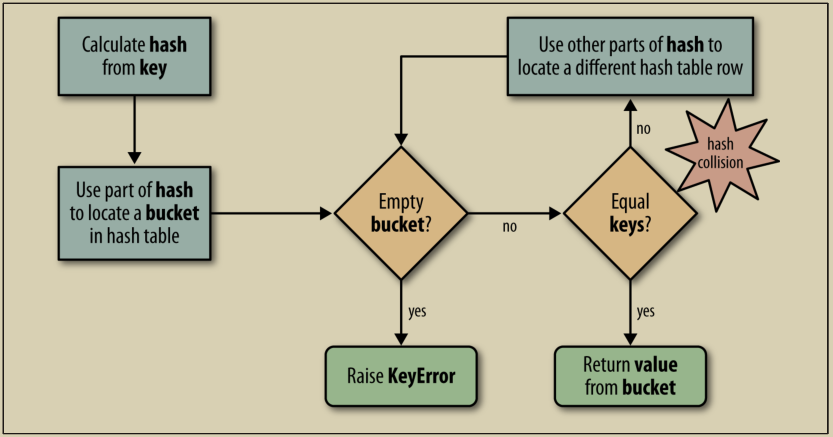
Additionally, when inserting items, Python may determine that the hash table is too crowded and rebuild it to a new location with more room. As the hash table grows, so does the number of hash bits** used as bucket offsets**, and this keeps the rate of collisions low.
7.3 Avoid Insertion during scan
Whenever you add a new item to a dict , the Python interpreter may decide that the
hash table of that dictionary needs to grow, with the result that the keys are likely to be ordered differently in the new hash table.
If you are iterating over the dictionary keys
and changing them at the same time, your loop may not scan all the items as expected
— not even the items that were already in the dictionary before you added to it.
This is why modifying the contents of a dict while iterating through it is a bad idea. If you need to scan and add items to a dictionary, do it in two steps: read the dict from start to finish and collect the needed additions in a second dict . Then update the first one with it.
In Python 3, the .keys() , .items() , and .values() methods return dictionary views, which behave more like sets than the lists returned by these methods in Python 2. Such views are also dynamic: they do not replicate the contents of the dict , and they immediately reflect any changes to the dict.

若有收获,就点个赞吧
0 人点赞
