评价算法有很多维度,时间复杂度,空间复杂度等等。
解决一件事情,有很多种方法,可能每种方法的耗时各不相同,使用的资源也各不相同,那么如何评价哪个方法更好,这就需要一个评价标准,而时间复杂度,算是评价标准中非常重要的一个。
时间复杂度 的计算,是一个数学问题,通常使用 “大O表示法” 来表征。
大O表示法 就是将算法的所有步骤转化为代数项,然后排除不会对问题的整体复杂度产生较大影响的较低阶常数和系数,用以表示算法在问题规模不断增大时,对应的近似的时间增长曲线。我们只关注表达式中对最终结果会产生最大影响的因子。
大O表示法的数学含义
O(1) — 常量时间。给定一个大小为n的输入,该算法只需要执行一步就可以完成任务;
O(log) — 对数时间。给定大小为n的输入,算法每执行一步,它完成任务所需要的步骤数就会以指数形式减少;
O(n) — 线性时间。给定大小为n的输入,算法执行所需要的步骤,与n成线性关系,随n增大而线性增长;
O(nlogn) — 线性对数时间。
O(n^2) — 二次方时间。给定大小为n的输入,算法执行所需要的步骤,是n的平方;
| 描述 | 大O表示 | 说明 |
|---|---|---|
| 常量时间 | O(1) | 散列表。随着输入规模的增大,算法执行操作基本不变 |
| 对数时间 | O(logN) | 二分策略。给定大小为n的输入,算法每执行一步,它完成任务所需要的步骤数就会以指数形式减少 |
| 线性时间 | O(N) | 遍历。给定大小为n的输入,算法执行所需要的步骤,与n成线性关系,随n增大而线性增长。 |
| 线性对数时间 | O(NlogN) | 执行N次logN操作。分而治之策略思想 |
| 平方时间 | O(N^2) | 双层循环遍历。 |
对于O(logN)的理解
对于O(logN)的理解:
以编程的入门游戏—猜数字 为例。A在[1,100]范围内选一个数字写到卡片上,B进行猜测,如果B猜测有误,A需要告知大了还是小了,直到B猜中为止。
最简单的方式,B按序从1开始一次+1向上猜测,这样的测试步骤与输入数字的范围成线性增长,算法复杂度为O(N);
如果B采用二分的方式,每次猜测剩余数字的平均数,那么每次执行完,剩余的总步数将较上一次减少一半,直到最后只剩1个数字为止,算法复杂度为O(logN);
对于O(NlogN)的理解
对于O(NlogN)的理解:
NlogN,即执行了N次logN操作。
对一堆带有序号的书进行排序,如何才能较快地排好呢?先随机选择一本书,将剩余的书的序号与之比较,较小序号的书扔左边,较大序号的书扔右边。因为这是一次遍历操作,故本次的时间复杂度为O(N)。假如,我们本次随机抽出的书的序号,较小的一堆书剩N/3,则较大的一堆书剩近乎2N/3。对左侧的N/3本书重复执行上述步骤,则本次遍历操作的时间复杂度为O(N/3)->O(N),对右侧的2N/3本书重复执行上述步骤,则本次遍历操作的时间复杂度为O(2N/3)->O(N)。
由此可以看到,对于每次拆堆的操作,时间复杂度都是O(N),那么现在的问题焦点,就转化为了:“到底有多少次这种拆堆操作”。
为了便于理解,我们假设恰好每次选择的书的编号,都恰好介于其“所属堆”的中间位置,即根据所选编号拆堆,左堆和右堆的数量基本相等。这样的特殊情况,是不是很似曾相识 — 没错,每次执行,都一分为二,比较类似二分法。
二分法每次执行完,剩余的总数较上一次减半,但本例中并不是猜一个数,而是相当于每个数都是被猜的那个数 — 拆堆直到无法再拆为止,即只有一本书。每次集体拆堆,堆数就翻番,这更像是一个等比数列 ,其中Sm即可理解为书总数,m可以理解为拆的总堆数,公比q=2,a1=1,则
,其中Sm即可理解为书总数,m可以理解为拆的总堆数,公比q=2,a1=1,则 ,即logN。
,即logN。
现在该算法策略的时间复杂度即为 每次操作的时间复杂度 x 操作次数,即为 O(NlogN)。
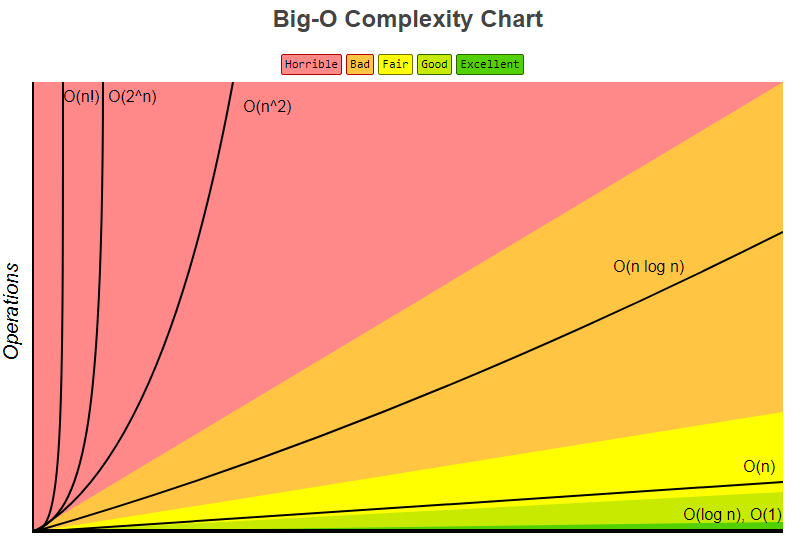
典型时间复杂度曲线图
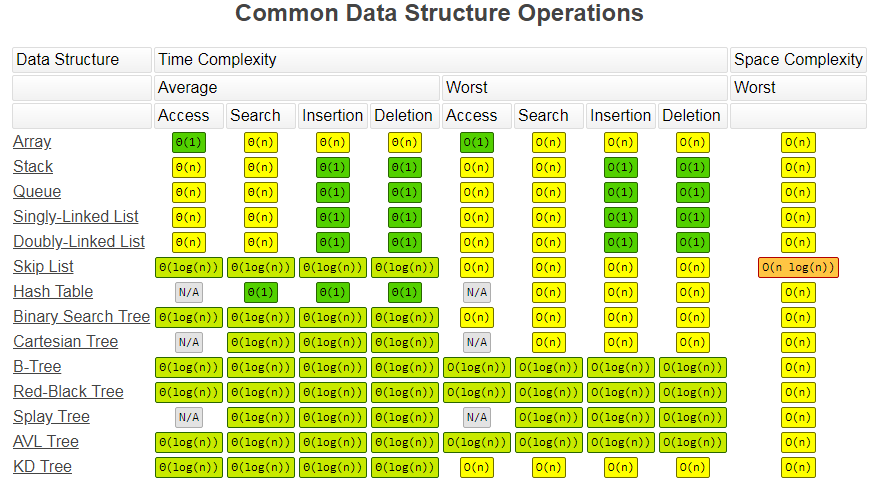
典型数据结构及其操作的时间复杂度
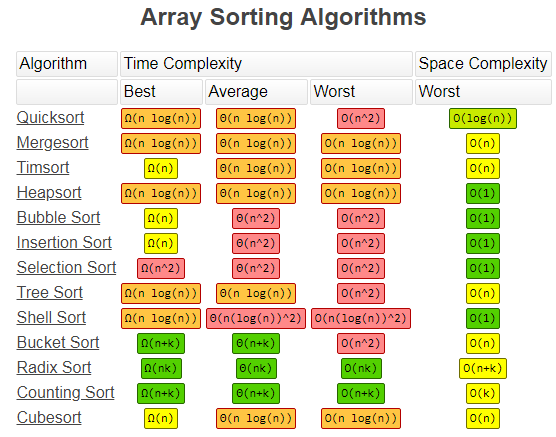
数组排序各算法时间复杂度

若有收获,就点个赞吧
0 人点赞
