背景:
参照持续升级过程:Kubernetes 1.16.15升级到1.17.17,Kubernetes 1.17.17升级到1.18.20,Kubernetes 1.18.20升级到1.19.12 Kubernetes 1.19.12升级到1.20.9(强调一下selfLink)。由于系统都是centos7的。我想把节点摘掉重新安装一下系统(系统替换为centos8.2)然后重新加入集群。以k8s-master-03节点为例……
| 主机名 | 系统 | ip |
|---|---|---|
| k8s-vip | slb | 10.0.0.37 |
| k8s-master-01 | centos7 | 10.0.0.41 |
| k8s-master-02 | centos7 | 10.0.0.34 |
| k8s-master-03 | centos7 | 10.0.0.26 |
| k8s-node-01 | centos7 | 10.0.0.36 |
| k8s-node-02 | centos7 | 10.0.0.83 |
| k8s-node-03 | centos7 | 10.0.0.40 |
| k8s-node-04 | centos7 | 10.0.0.49 |
| k8s-node-05 | centos7 | 10.0.0.45 |
| k8s-node-06 | centos7 | 10.0.0.18 |
1. 升级更新过程:
1.将k8s-master-03节点设置为不可调度,并驱逐节点上pod。
kubectl drain k8s-master-03 --ignore-daemonsets
2. 删除k8s-master-03节点
kubectl delete nodes k8s-master-03
3. 重装系统
服务器是腾讯云的cvm。后台直接选择了centos8镜像重新初始化了!(当然了 我自己定制化过一个containerd kubeadm的基础镜像,就直接引用了这个镜像呢)
4. 升级内核
虽然centos8默认内核是4.18了,但是我还是想个人升级一下内核:
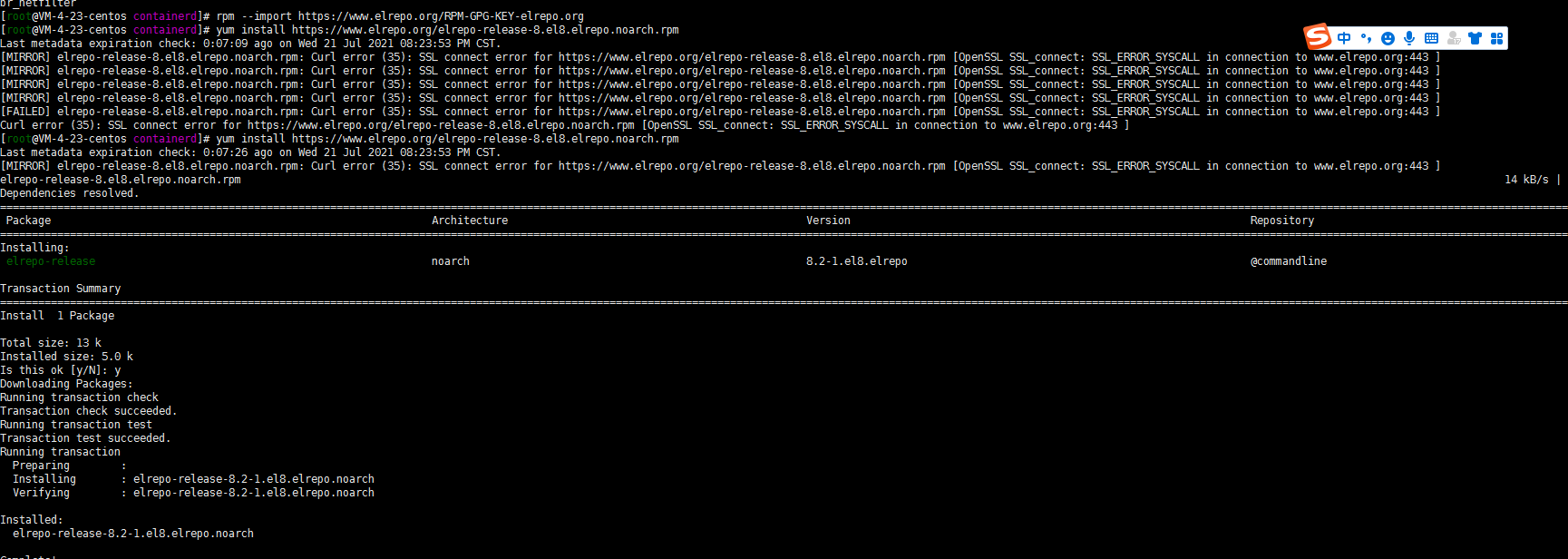
1. 安装epel源
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
yum install https://www.elrepo.org/elrepo-release-8.el8.elrepo.noarch.rpm
2. 查看并升级内核到ml版本
查询源中kernel版本,最终选择了ml主线最新版本……
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
yum --enablerepo=elrepo-kernel install kernel-ml
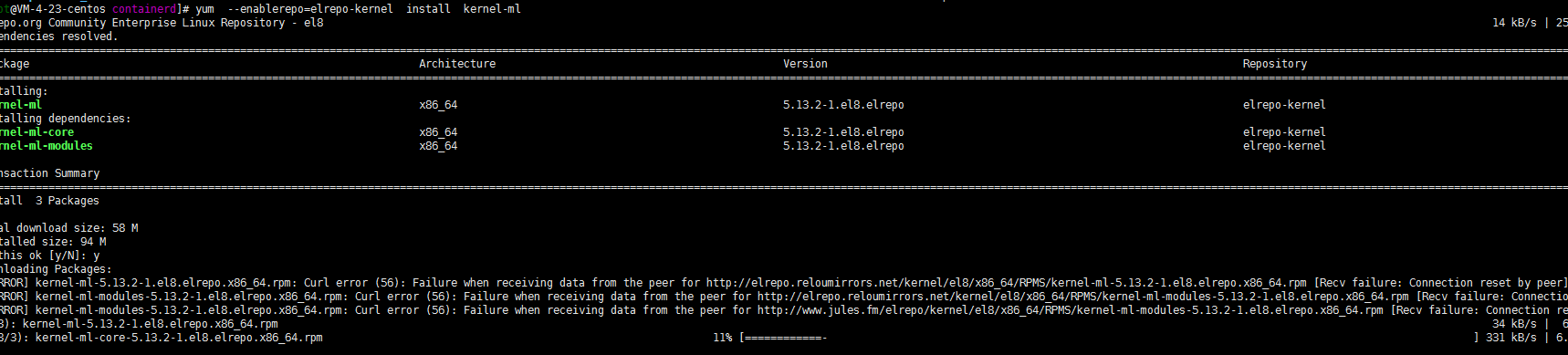
最近网比较抽筋,很慢的
关于ml lt版本:
kernel-lt(长期支持版本)
kernel-ml(主线最新版本)
一般的长期稳定支持版就好了,嗯我手贱选择了ml版本了……
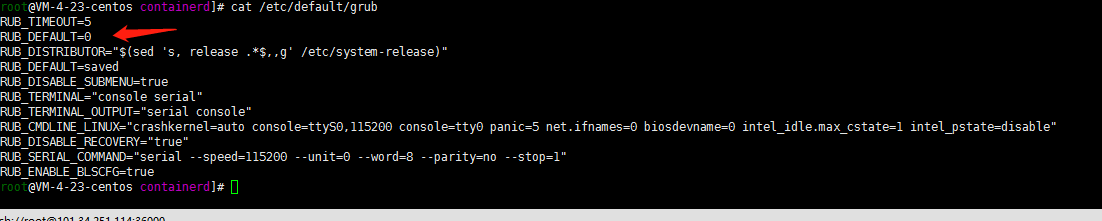
3. 编辑引导配置文件并重新生成引导
vi /etc/default/grub
设置
GRUB_DEFAULT=0
grub2-mkconfig -o /boot/grub2/grub.cfg

4. 重启系统并验证内核
reboot
uname -a

5. 节点初始化
参照: centos8+kubeadm1.20.5+cilium+hubble环境搭建
到这里就好了!哦对还有下面的一部haproxy
注: 完成了hostnamectl set-hosetname k8s-master-03
6. 生成token
登陆k8s-master-01节点生成token discovery-token-ca-cert-hash
kubeadm token create
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
并打包key解压到k8s-master-03节点/etc/kubernetes/pki目录下(解压操作的就没有写了)
cd /etc/kubernetes/pki
zip -r key.zip ca.* sa.* front-proxy-ca.* etcd/ca*
7. k8s-master-03节点重新加入集群
kubeadm join 10.0.0.37:6443 --token jj1ck5.hp7pn0lxxxxx --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxx --control-plane
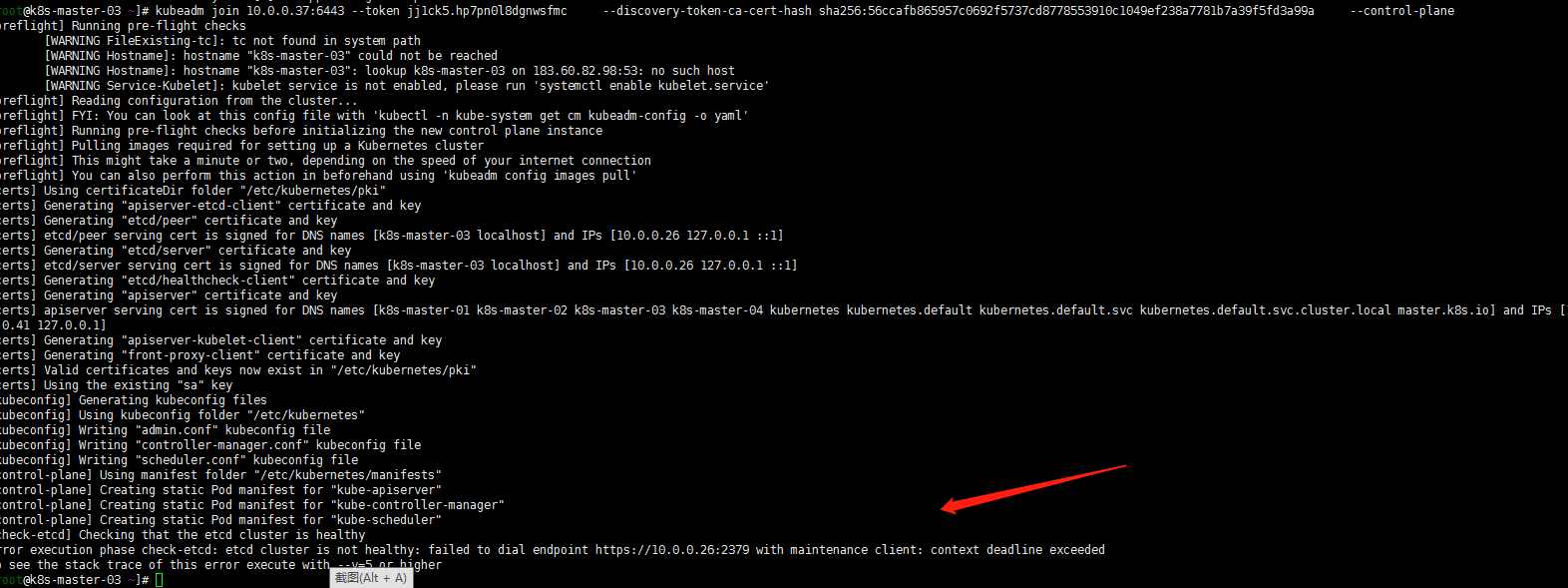
what?etcd报错了?怎么回事呢?开始的时候etcd是有三个节点的,我删除后重新加入会不会是冲突了呢?
k8s-master-01主机安装了etcd客户端方法如下: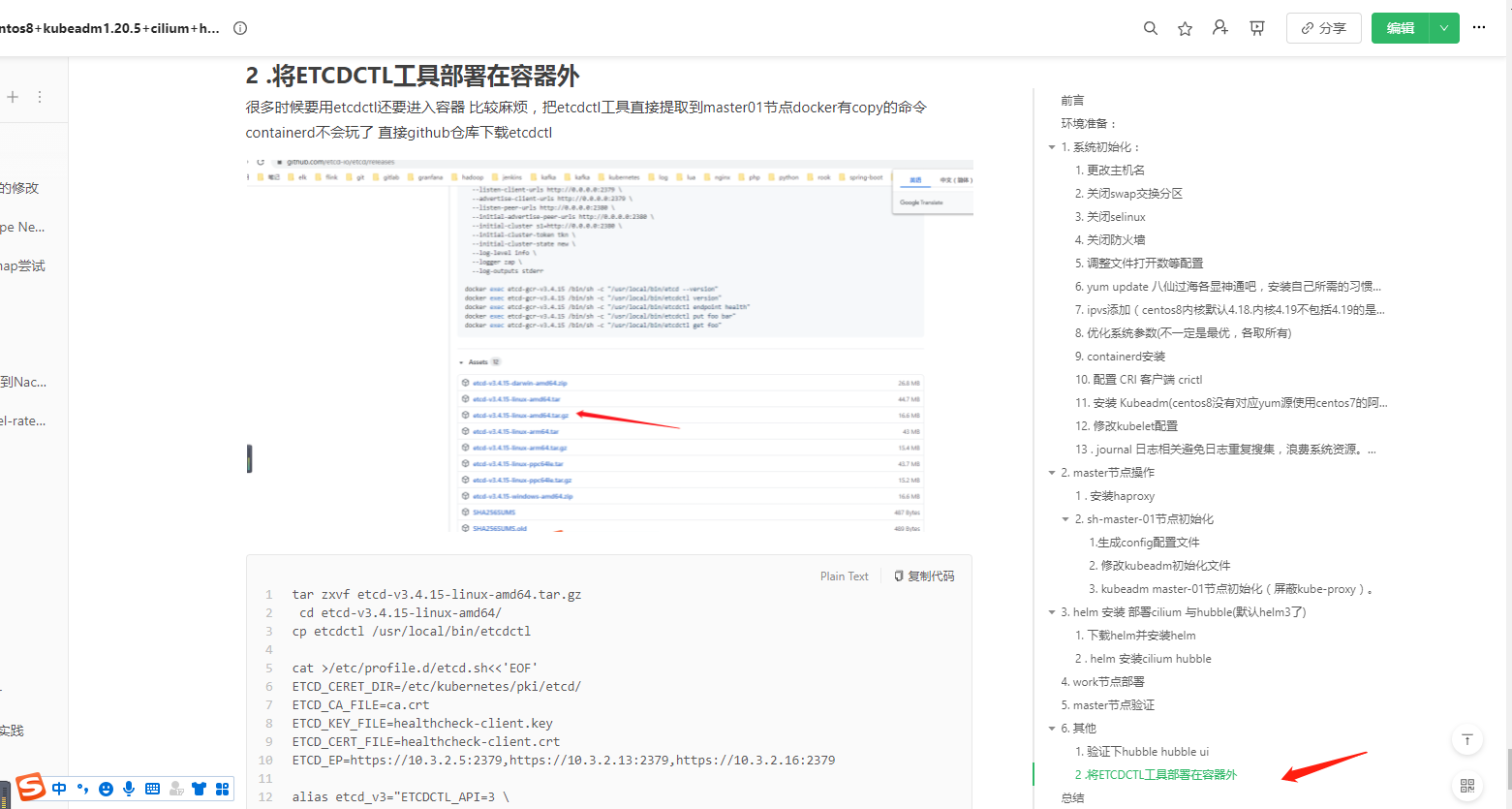
使用etcd命令查看相关信息:
etcd_v3 endpoint status --write-out=table
etcd_v3 member list
果真etcd信息中还是有k8s-master-03节点的相关信息,将其移除,并验证:
etcd_v3 member remove c86024150ccad21d
etcd_v3 member list

重新执行加入集群执行一下操作:
首先的reset
kubeadm reset
注: 然后继续解压一遍key.zip /etc/kubernetes/pki目录下
kubeadm join 10.0.0.37:6443 --token jj1ck5.hp7pn0lxxxxx --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxx --control-plane
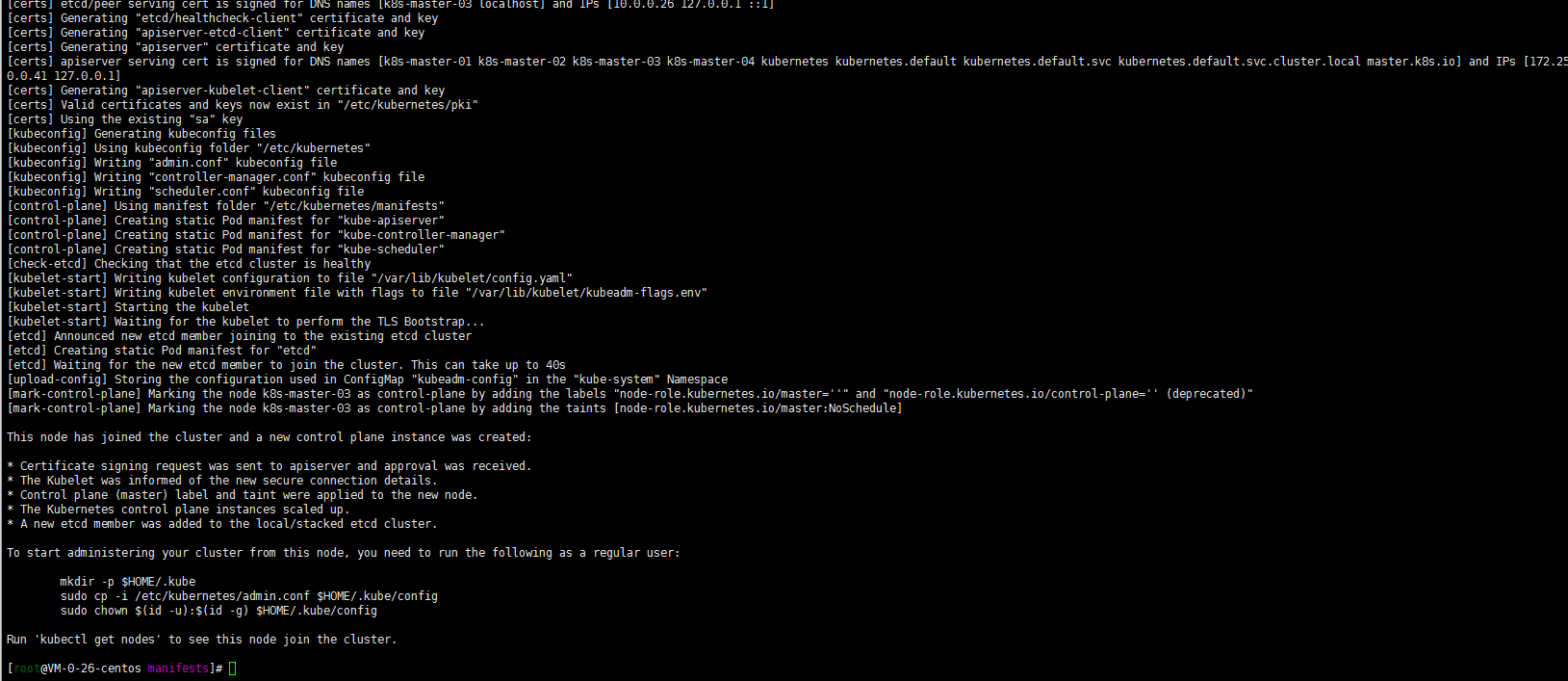
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
OK成功了!试验一下:
kubectl get nodes

嗯到了这里的还有修改/etc/kubernetes/manifests目录下kube-controller-manager.yaml kube-controller-manager.yaml —bind-adress=127.0.0.1为 —bind-adress=0.0.0.0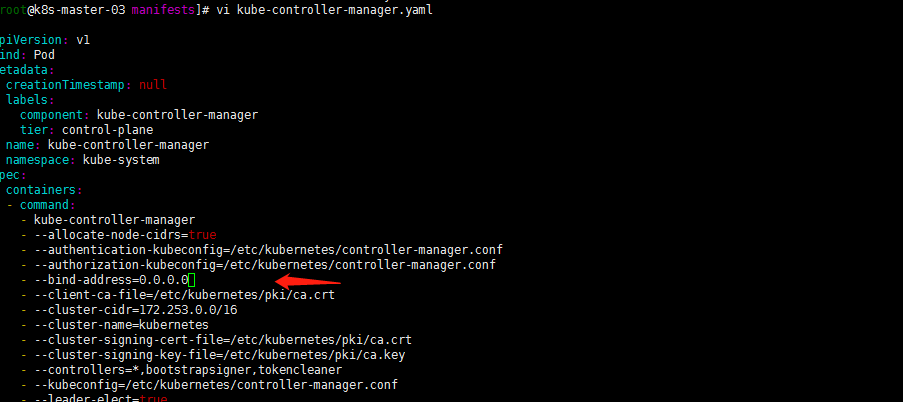
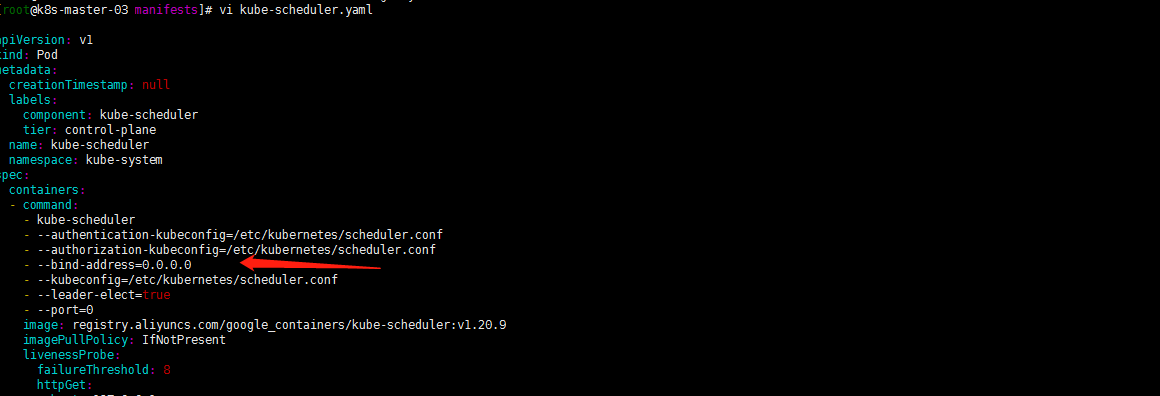
否则Prometheus一直报警的呢!

若有收获,就点个赞吧
0 人点赞
