背景:
Kubernetes 1.20.5 安装Prometheus-Oprator嗯,我的集群是1.21.3了虽然是……
执行kubectl top nodes如下:
解决问题过程:
网上一堆各种说法的,但是没有一个是适用于我的。把monitoring下所有的pod的日志看了一个遍,然后在prometheus-adapter中发现日志如下: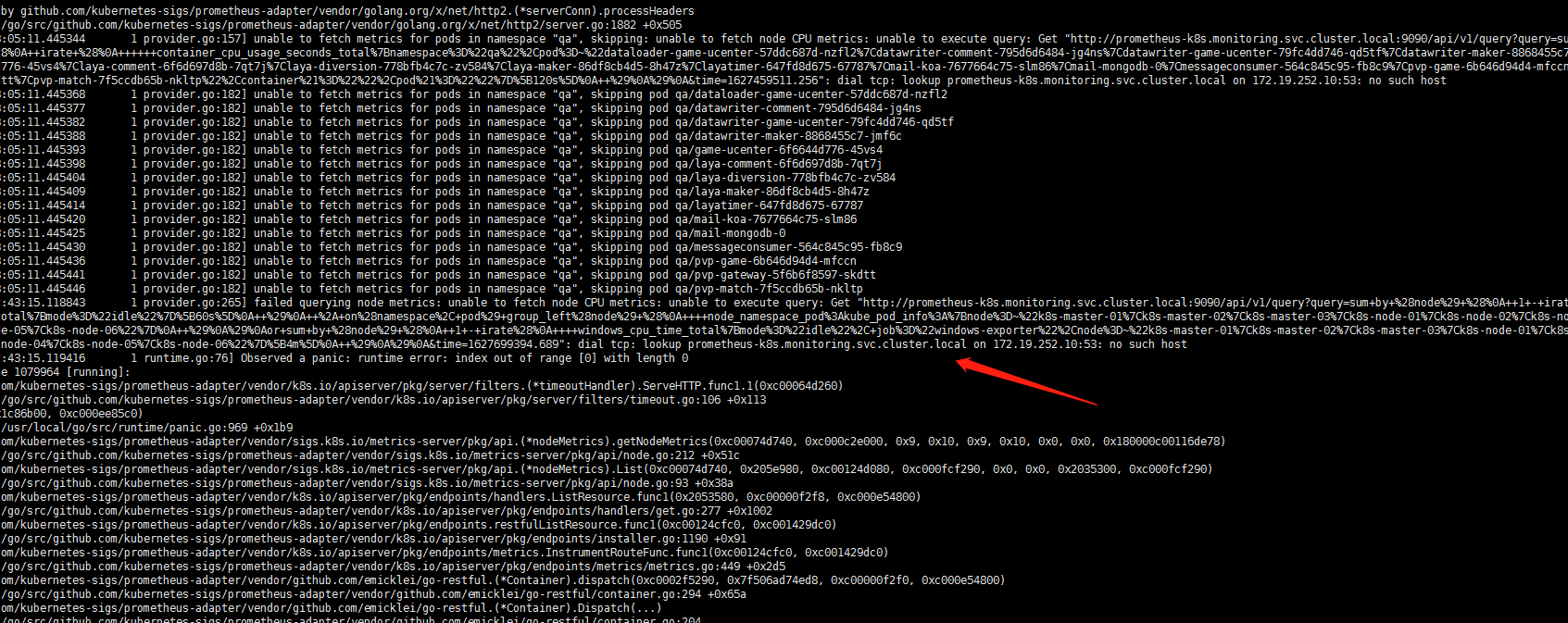
嗯想起来了我的集群都不是默认的cluster.local!如果有跟我一样自定义命名集群的需要注意修改这个这个配置!
然后找一下配置文件中哪个文件有此项配置:
比较笨的方式:
grep -A2 -B2 cluster.local

 一个一个前缀的排除。最后确认是prometheus-adapter-deployment.yaml配置文件,修改一下:
一个一个前缀的排除。最后确认是prometheus-adapter-deployment.yaml配置文件,修改一下: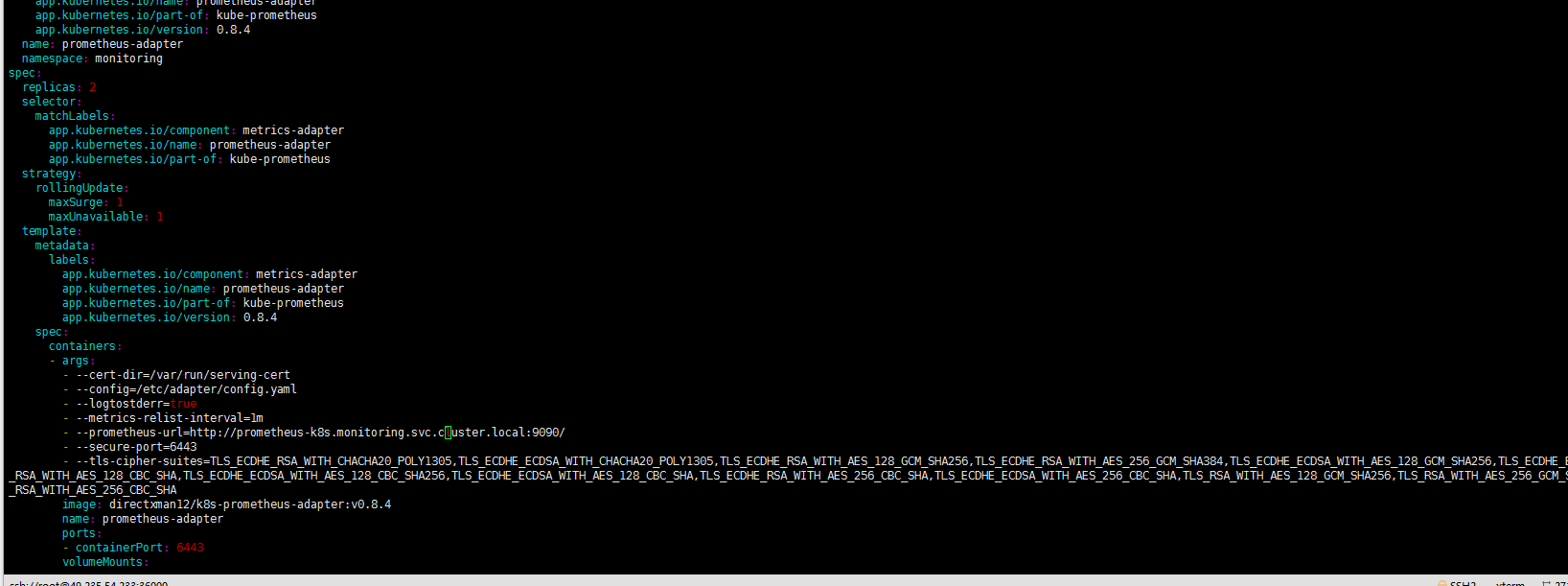
kubectl apply -f prometheus-adapter-deployment.yamlkubectl get pods -n monitoring
等待pod更新重新启动验证:
[root@k8s-master-01 manifests]# kubectl top nodesW0731 11:24:57.758043 1760118 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flagNAME CPU(cores) CPU% MEMORY(bytes) MEMORY%k8s-master-01 231m 5% 2497Mi 31%k8s-master-02 227m 5% 1989Mi 25%k8s-master-03 235m 5% 2071Mi 26%k8s-node-01 490m 3% 4023Mi 12%k8s-node-02 221m 1% 4854Mi 15%k8s-node-03 616m 3% 10671Mi 33%k8s-node-04 644m 4% 6238Mi 19%k8s-node-05 620m 3% 9058Mi 28%k8s-node-06 196m 4% 5436Mi 69
尽信书则不如无书。还是多看一下个人环境的日志。然后标注一下个人集群的修改地方。更快的定位问题,并解决问题!

若有收获,就点个赞吧
0 人点赞
