- 背景
预训练模型使用的训练数据并非训练集,可能来自ImageNet数据库等
用于图像分类,像素语义分割,对象检测,实例分割,人员关键点检测和视频分类 - 重点
+特征提取:去掉输出层;仅提取分类的特征,为分类做准备
+采用预训练模型的结构:权重随机化
+训练特定层(比如分类层),冻结其他层:将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重(冻结:不参与梯度的反向传播)
一、模块 & Data
1. 重点:迁移学习的模块
torchvision.models() 卷积层网络
%matplotlib inline%config InlineBackend.figure_format = 'retina'import matplotlib.pyplot as pltimport torchfrom torch import nnfrom torch import optimimport torch.nn.functional as Ffrom torchvision import datasets, transforms modelsdata_dir = 'Cat_Dog_data' #本地文件的路径#Define a transform to normalize the datatrain_transforms = transforms.Compose([transforms.Resize(384),transforms.CenterCrop(255),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])test_transforms = transforms.Compose([transforms.Resize(384),transforms.CenterCrop(255),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])#Input datatrain_data = datasets.ImageFolder(data_dir + '/train', transform=train_transforms)test_data = datasets.ImageFolder(data_dir + '/test', transform=test_transforms)#Dataloadertrainloader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)testloader = torch.utils.data.DataLoader(test_data, batch_size=64)
二、加载预训练模型
model = models.densenet121(pretrained=True)
- 特征层
应用:可以作为特征检测

- 分类层
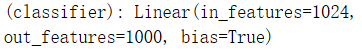
全连接:1000个类别(需要修改:猫狗分类只有2个类别)
本质:迁移学习到的是特征(从权重信息可进一步抽象出特征)
三、建立模型
1. 冻结参数:特征部分
冻结预训练模型中的所有参数
for param in model.parameters():param.requires_grad = False
2. 针对目标问题(猫狗分类),建立网络架构
注意:输入的维度与classifier.in_features保持一致
from collections import OrderedDictclassifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(1024, 500)),('relu', nn.ReLU()),('fc2', nn.Linear(500, 2)),('output', nn.LogSoftmax(dim=1))]))model.classifier = classifier
3. 训练(过程省略)
4. 测试(cpu VS cuda)
import timefor device in ['cpu', 'cuda']:criterion = nn.NLLLoss()#Only train the classifier parameters, feature parameters are frozenoptimizer = optim.Adam(model.classifier.parameters(), lr=0.001)model.to(device)for ii, (inputs, labels) in enumerate(trainloader):inputs, labels - inputs.to(device), labels.to(device)start = time.time()outputs = model(inputs) #或者model.forward(inputs)??loss = criterion(outputs, labels)loss.backward() #反向传播optimizer.step() #权重更新if ii==3:breakprint(f"Device = {device}; Time per batch:{(time.time()-start)/3:.3f} seconds")
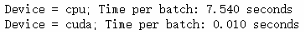
@me:同样的代码,我的GPU内存爆满
- 说明容量还是不够
- 要考虑代码优化
四、分析总结
1. 知识点
- 对象:模型优化(更新权重)
optim.()
#optim.Adam()optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)#optim.SGD()optim.SGD([{'params': model.base.parameters()},{'params': model.classifier.parameters(), 'lr': 1e-3}], lr=1e-2, momentum=0.9)#训练-内循环 梯度清零:梯度跟踪仅在反向传播阶段optimizer.zero_grad()
- 对象:DataLoader
torch.utils.data.DataLoader类
本质:格式化数据
输出:迭代器
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,batch_sampler=None, num_workers=0, collate_fn=None,pin_memory=False, drop_last=False, timeout=0,worker_init_fn=None)#Dataset负责生产数据#DataLoader负责数据的分批(batch_size)、采样(sampler)、传输
2. 模型参数/属性
- 模型
- torch.nn.Module
nn.Sequential((nn.(), nn.(), ...)),
nn.Sequential(OrderedDict([('', nn.()), ('', nn.()), ('', nn.()), ...]))- models.() 预训练模型:迁移学习
models.densenet121(pretrained=True)
- 模型的层次
- 特征层
model.features- 分类层
model.classifier- 探索:模型层次的组合
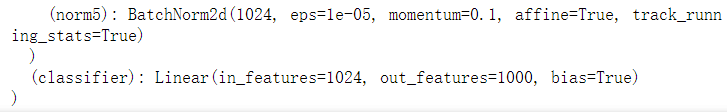
#基于预训练模型model_rechange = models.densenet121(pretrained=True)#重构特征层feature = nn.Sequential(OrderedDict([('fc1', nn.Linear(1024, 500)),('relu', nn.ReLU()),('fc2', nn.Linear(500, 800)),('output', nn.LogSoftmax(dim=1))]))model_rechange.features = feature #输出测试:特征层.features.parameters() 输出数据的维度是 torch.Size([800])#保留分类层classifierclassifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(1024, 500)),('relu', nn.ReLU()),('fc2', nn.Linear(500, 2)),('output', nn.LogSoftmax(dim=1))]))model_rechange.classifier = classifier

问题:feature层的输出是800,但classifier层的输入是1024,该模型是否可行?
- 模型的具体参数
model.features.parameters()model.classifier.parameters()torch.nn.Parameter()

若有收获,就点个赞吧
0 人点赞
