一、深度学习框架
- Caffe
- Caffe2
- Chainer
- CNTK(Microsoft Cognitive Toolkit)
- Deeplearning4j
- Keras
- MATLAB
- MxNet
- TensorFlow
- Theano
- Torch/PyTorch
二、搭建开发环境(GPU环境)
1. GPU环境:NVIDIA CUDAv10.2
2. 库:cuDNN v7.6.5 (for CUDAv10.2)
3. 开发框架:tensorflow, pytorch等
- conda:调试很方便
+ pip: 轻量级,纯净4. 查看验证
- CUDA是否正确安装:cmd窗口,输入
nvcc -V
+ PyTorchtorch.cuda.is_available()返回True
+ GPU使用的设备variable.cuda()返回device
- GPU训练
(model/variable).to('cuda')
(model/variable).to('cpu')- 工具
使用:CUDA
查看:GPUz- 省内存的技巧
尽可能使用inplace操作- NVIDIA开发人员计划
使用最新的NVIDIA SDK和工具来加速您在人工智能,深度学习,加速计算和高级图形等关键技术领域中的应用
包括自动驾驶汽车,大数据,医疗保健,高性能计算,机器人技术,虚拟现实等领域
三、背景知识:CPU与GPU
1. 核心数
2. 进程与线程
- GIL Global Interpreter Lock
解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁
但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了
毫无疑问全局锁的存在会对多线程的效率有不小影响。甚至就几乎等于Python是个单线程的程序
解决方案:用multiprocessing替代Thread,多进程代替多线程
3. GPU使用场合
- 图像处理:适合并行运算
openACC
openCL
4. 编程实现
PyTorch框架调用
C++调用封装好的函数
四、PyTorch框架入门
1. 知识点
- 张量Tensor
向量和矩阵的泛化:类似ndarray,本质都是张量- 加法
torch.sum()
dim=0:跨行相加
dim=1:跨列相加- 乘法
- Hadamard product
x.mul(y)用法与乘法相同,两者都是broadcast的
x.mul_(y)下划线表示inplace = True
`对应元素相乘:如果a与b的size不同,则以某种方式将a或b进行复制,使得复制后的a和b的size相同<br />标量:数乘<br />一维向量`:广播机制
Tensor与行向量做乘法的结果是每列乘以行向量对应列的值
Tensor与列向量做乘法的结果是每行乘以列向量对应行的值- 矩阵相乘 (j, 1, n, m) & (k, m, p) == (j, k, n, p)
torch.mm(x, y)或x.mm(y)矩阵大小需满足: (i, n)x(n, j)
torch.matmul(x, y)torch.mm的broadcast版本
torch.matmul()支持广播;若均为一维:表示内积
- 除法:基于列
a (64, 10)b (64,)
a/b 报错:若b是列向量(64, 1),则a的每一行除以b的每一行(单个数)
关注列的维度,10/1能除尽@广播机制
但是b(64,)默认行向量,即1*64:无法做到10/64- 其余运算
torch.mean()注意dim的取值
torch.topk()topk, indices = torch.topk(data, k)
2. 关键细节
- 数据类型转换(Tensor&ndarray)
torch.from_numpy()ndarray转化为Tensor
torch.numpy()转化为ndarray
注意:转换前后共用同一块内存,所以两者同时改变- 下划线:表示
inplace=True- 维度调整
.shape()
.flatten()
.reshape()
.resize_()维度小了,则删除多余的数据;维度大了,则新数据先不初始化
weights.view()常用,返回与weights维度相同的新的张量(与原始数据相同):如果数量不同,则报错(避免.resize_的问题)
五、实例:识别数字(28*28图像)
基础操作:感知器
#导入模块import torch#自定义函数 激活函数def activation(x):return 1/(1+torch.exp(-x))#单层感知器 5*1#初始化torch.manual_seed(7)features = torch.randn((1, 5)) #1行5列 正态分布随机weights = torch.randn_like(features) #维度相同randn_likebias = torch.randn((1, 1))#前馈过程h = torch.sum(features.mul(weights)) + bias #一维向量.mul()表示* Hadamard producty = activation(h)#多层感知器 3*2*1#初始化torch.manual_seed(7)features = torch.randn((1, 3))n_input = features.shape[1]n_hidden = 2n_output = 1W1 = torch.randn(n_input, n_hidden) #3*2W2 = torch.randn(n_hidden, n_output) #2*1B1 = torch.randn((1, n_hidden))B2 = torch.randn((1, n_output))#前馈过程h = activation(features.mm(W1) + B1)y = activation(h.mm(W2) + B2)
- 预备工作:导入数据 数字0-9识别 数据源
数据大小:[64, 1, 28, 28]
一个Batch:64张图,每张图是28*28像素
from torchvision import datasets, transforms#Define a transform to normalize the datatransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, ), (0.5, ))])#Download and load the training datatrainset = datasets.MNIST('~/.pytorch/NNIST_data/', download=True, train=True, transform=transform)testset= datasets.MNIST('~/.pytorch/NNIST_data/', download=True, train=False, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)
实现1)清晰过程
1.1 建立模型
#导入模块import torchfrom torch import nn, optimimport torch.nn.functional as F#封装成类class Classifier(nn.Module):def __init__(self):super().__init__()#3个隐藏层self.fc1 = nn.Linear(784, 256) #fc full connectself.fc2 = nn.Linear(256, 128)self.fc3 = nn.Linear(128, 64)self.fc4 = nn.Linear(64, 10)def forward(self, x):x = x.view(x.shape[0], -1)x= F.relu(self.fc1(x))x= F.relu(self.fc2(x))x= F.relu(self.fc3(x))x= F.log_softmax(self.fc4(x), dim=1)return x
- 前馈测试
model = Classifier()images, labels = next(iter(testloader)) #测试样本 28*28图像;标签表示具体数字#计算结果:概率值#.forward()中含有等价于.flatten的操作ps = torch.exp(model(images)) #不需要model.forward() 默认为输入(继承nn.Module 且覆写方法.forward())print(ps.shape) #结果显示([64, 10])
1.2 训练网络-反向传播 + 1.3 验证测试
#1.2 训练网络-反向传播model = Classifier()criterion = nn.NLLLoss()optimizer = optim.Adam(model.parameters(), lr=0.003)epochs = 2steps = 0train_losses, test_losses = [], []for e in range(epochs):running_loss = 0for images, labels in trainloader:optimizer.zero_grad()log_ps = model.(images)loss = criterion(log_ps, labels)loss.backward()optimizer.step()running_loss += loss.item()#1.3 验证测试else:test_loss = 0accuracy = 0#验证过程中:关闭梯度跟踪with torch.no_grad():for images, labels in testloader:log_ps = model.(images)test_loss += criterion(log_ps, labels)ps = torch.exp(log_ps)top_p, top_class = ps.topk(1, dim=1)equals = top_class == labels.view(*top_class.shape)accuracy += torch.mean(equals.type(torch.FloatTensor))train_losses.append(running_loss/len(trainloader))test_losses.append(test_loss/len(testloader))print("" .format, ...)

实现2)nn.Module
2.1 建立模型
input_size = 784hidden_sizes = [128, 64]output_size = 10#建立模型#实现方法(1)逐个列举model = nn.Sequential(nn.Linear(input_size, hidden_sizes[0]),nn.ReLU(),nn.Linear(hidden_sizes[0], hidden_sizes[1]),nn.ReLU(),nn.Linear(hidden_sizes[1], output_size),nn.Softmax(dim=1))#实现方法(2)有序字典 collections.OrderedDict()from collections import OrderedDictmodel = nn.Sequential(OrderedDict([('fc1', nn.Linear(input_size, hidden_sizes[0])),('relu1', nn.ReLU()),('fc2', nn.Linear(hidden_sizes[0], hidden_sizes[1])),('relu2', nn.ReLU()),('output', nn.Linear(hidden_sizes[1], output_size)),('softmax', nn.Softmax(dim=1))]))#model[0]等价于model.fc1
2.2 训练网络-反向传播 + 2.3 验证测试
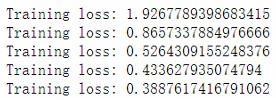
criterion = nn.NLLLoss()optimizer = optim.SGD(model.parameters(), lr=0.003)epochs = 5for e in range (epochs) :running_loss = 0for images, labels in trainloader:#Flatten WIST images into a 784 long vectorimages = images. view (images.shape[0], -1)#Training passoptimizer.zero_grad()output = model(images)loss = criterion(output, labels)loss.backward()optimizer.step()running_loss += loss.item ()else:print (f"Training loss: {running_loss/len (trainloader)}")
六、实例分析(流程梳理)
1. 模块汇总
import torch
from torch import nn
from torchvision import datasets, transforms
import torch.nn.functional as F
#torch.nn模块
(model).weight
.weight.data.normal_(std=0.01)
(model).bias
.bias.data.fill_(0)
torch.randn(, requires_grad=True) #梯度跟踪
torch.empty()
.random_()
#建模相关
criterion()
loss()
loss().backword() #backword() 某变量的偏导(基于梯度跟踪)
nn.ReLU()
nn.Logsoftmax() == log(nn.Softmax())
nn.NLLLoss() == - nn.Logsoftmax()
nn.CrossEntropyLoss() #交叉熵
nn.Sequential(nn.Linear(), nn.ReLU(), ...) # OrderedDict()方法
#torch.nn.functional模块
F.relu()
F.sigmoid()
F.softmax()
F.log_softmax()
#autograd模块
requires_grad = True
torch.set_grad_enabled(True|False)
(model).weight.grad
x.requires_grad_(True) #开启梯度跟踪
torch.zeros(1, requires_grad=True)
with torch.no_grad():
......
......
#optim模块
optim.SGD()
(optim.SGD()).zero_grad()
2. 操作细节
- 验证循环时
model.eval()将网络设为评估模式,验证环节不必dropout
model.train()将其设为训练模式
- CUDA错误
错误原因:一部分模型/张量在CPU,另一部分在GPU
解决方法:涉及所有相关的模型和张量转移到同一device
3. 评价指标
- 准确率
- 精确率、召回率
- top-5错误
4. 常见问题
- 欠拟合&过拟合 @类比-试穿裤子:选择大一点+腰带控制
- 模型复杂度图表
提前停止训练- 正则化:模型权重的影响
@ODS-惩罚因子λ:对权重系数增加惩罚因子λ
本质:避免影响,就针对该影响添加惩罚因子
L2倾向于选择均匀、非稀疏的向量
- 训练不均衡
- dropout
每个节点有20%的概率(可设置)在前馈-反向传播的一个循环中关闭
@肌肉训练:左右都训练
- 陷入局部最小点 1)随机启动random restart 设置不同的初始权值 2)动态步长momentum 动量β:结合步长的历史==动量的惯性 峡谷的例子:左右振荡——>振荡抵消 不用二阶方法:计算量太大 3)随机梯度下降SGD Stochastic gradient descent 梯度的随机近似(随机选择部分数据集),代替真正的梯度下降 更快迭代,但收敛率下降
- 计算量大
- 随机梯度下降(选择数据批次)
程序实现:
外循环(4个批次)
内循环(每个批次:6个点)
- 参数:学习速率选取
- 实际运用:“动态”学习速率
陡峭:步长大
平坦:步长小
- 选择:不同的误差函数 1)如果参数模型定义了一个分布p(y|x;θ),我们采用最大似然原理得到代价函数:训练数据和模型预测间的交叉熵
对数函数能帮我们避免梯度过小(例如有的输出单元有一个指数函数,取对数后梯度就不那么小了) 2)如果不预测y的完整概率分布,仅仅预测在给定x条件下y的某种统计量,那就用某些专门的损失函数来计算 2.1)均方误差 2.2)平均绝对误差
- 均方差损失函数+Sigmoid激活函数(不推荐)
均方误差和平均绝对误差在梯度下降法表现不好,因为饱和的输出单元梯度非常小。
(Sigmoid的这个曲线意味着在大多数时候,我们的梯度变化值很小,导致我们的W,b更新到极值的速度较慢,也就是我们的算法收敛速度较慢)- 使用交叉熵损失函数+Sigmoid激活函数(提高收敛速度)
对比来说交叉熵代价函数更受欢迎7. 梯度消失 选择:激活函数
- sigmoid函数两端导数接近0
Softmax:多个分类- 双曲正切tanh(x)
- 修正线性单元ReLU
5. 网络优化
- 网络结构
- 数据
- 运行时间
References

若有收获,就点个赞吧
0 人点赞
