前言
- 我们提交SQL没有直接执行,而是让SQL的优化器先进行优化,优化过后才去执行
- SQL中库,表括起来的不是单撇,叫刀秋,tab键上面、波浪线按键下面的刀秋,将表名等括起来
- 数据库是没有布尔类型 boolean,mysql中用 tinyint替代
varchar(6) 与char(6)的区别
索引是独立存在,索引占空间,字段少,遍历快
int/bigint 采用二分查找,找的快
怎么提高表的查询性能?
- 索引! 优先想到,成本最低
- 分库,分表(mysql百万)
- 主从复制,读写分离
索引为什么快?
- 独自空间
- 索引进行了排序
- 算法:mysql中索引使用了 btree+(数据结构)
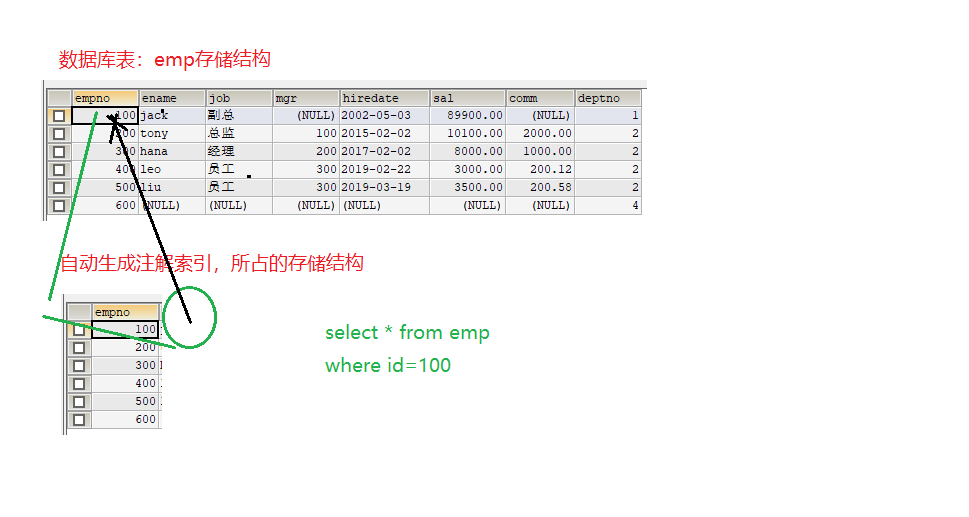
有索引和没有索引时:查询id为100的员工信息时的过程。
- 没有索引时,查询id为100的员工信息需要全表扫描,找到id为100的员工信息
- 给id设置主键,系统默认给id加上主键索引,这时查找id为100的员工信息直接通过B+Tree快速找到id100对应的索引,通过找到的索引直接对应到员工信息表里的记录
索引分类:
- 唯一索引 unique,数据库这个字段内容不能重复
- 单值索引,索引是一个字段
- 复合索引,多个字段形成一个索引
索引不要建立太多字段?
- 索引也占空间
- 索引字段非整数类型,性能没有整数高
操作数据库表:insert/update/delete会对索引有影响吗?
- 导致重新构造索引(构造树),如果记录很多,构建时间长
有关索引建立的一些规则
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段、排序的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B 、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
SQL优化准备
- 正确的完成了业务,再来考虑SQL优化,使用索引
-
基础SQL优化
查询SQL尽量不要使用select *,而是具体的字段
- 只取需要的字段,节省资源、减少网络开销
- select * 进行查询时,很可能不会用到索引,就会造成全表扫描
避免在where子句中使用or来连接条件
- or会导致索引失效,从而全表扫描
- 改进:可以用union all连接两个select语句来替换or
使用varchar代替char
- varchar是可变长度,比char省空间,一般用varchar
- 如果字段值固定,如性别,占两个字节,就可以使用char(2)来存放
尽量使用数值替代字符串类型
- 主键(id):primary key优先使用数值类型int,tinyint
- 性别(sex):0-代表女,1-代表男;数据库没有布尔类型,mysql推荐使用tinyint
- 支付方式(payment):1-现金、2-微信、3-支付宝、4-信用卡、5-银行卡
- 数值查询比字符串varchar快
查询尽量避免返回大量数据
- 查询返回数据量很大,就会造成查询时间过长,网络传输时间过长。
- 利用分页一次返回一部分数据
explain关键字,分析语句性能
语句性能分析中,type的值
- ALL 全表扫描,没有优化,最慢的方式
- index 索引全扫描,倒手第二慢的方式
- range 索引范围扫描,不错
- const单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询,最好
- ref 使用索引,多个字段的复合索引
- eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
- null MySQL不访问任何表或索引,直接返回结果
语句性能分析中possible_keys字段
- 显示可能应用在这张表中的索引
- 语句性能分析中key字段
- 真正使用的索引方式
创建字段索引
- alter table 表名 add index 索引名(要添加索引的字段1,要添加索引的字段2……要添加索引的字段n)
- 提高查询速度的最简单最佳的方式
索引不宜太多,一般5个以内
- 索引可以理解为一个就是一张表,其可以存储数据,那就要占空间
- 索引表数据是排序的,每次插入、更新、删除数据都要重构索引树,需要时间
优化like语句
- 模糊查询,程序员最喜欢的就是使用like,但是like很可能让你的索引失效
- like后面的具体字段,第一个是%会导致索引失效
- like后面的具体字段,第一个应该是具体的某个字(字母)
索引不适合建在有大量重复数据的字段上
- SQL优化器是根据表中数据量来进行查询优化的,如果索引列有大量重复数据,Mysql查询优化器推算发现不走索引的成本更低,很可能就放弃索引了,如性别字段
where限定查询的数据
- 数据中假定就一个男的记录
- 反例:
- SELECT id,NAME FROM student WHERE sex=’男’
- 计算机并不知道sex = ‘男’,将会全表扫描
- 正例:
- SELECT id,NAME FROM student WHERE id=1 AND sex=’男’
- 主键是索引,通过二分查找,找的快
- 如果知道查询结果为某一个数据时,能使用主键id查就用主键id查
避免在索引列上使用内置函数
- 给birthday设置索引
- EXPLAIN
- SELECT * FROM student
- WHERE DATE_ADD(birthday,INTERVAL 7 DAY) >=NOW();
- 使用索引嵌入在内置函数中,索引失效
- EXPLAIN
- SELECT * FROM student
- WHERE birthday >= DATE_ADD(NOW(),INTERVAL 7 DAY);
- 索引不失效
避免在where中对字段进行表达式操作
- EXPLAIN
- SELECT * FROM student WHERE id +1-1 = 1;
- 字段和表达式同一端,索引失效
- EXPLAIN
- SELECT * FROM student WHERE id = 1-1+1;
- 字段干净无表达式,索引有效
去重distinct过滤字段要少
- 当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,然而这个比较、过滤的过程会占用系统资源,如cpu时间
- 使用distinct去重时,字段不能是所有 *,也不能是非索引字段
避免在where子句中使用!=或<>操作符
- !=或<>操作符导致索引失效
where中使用默认值代替null
- !=、<>、is null、is not null经常会让索引失效
- 如果把null值,换成默认值,很多时候能让走索引成为可能,同时,表达意思也相对清晰一点
高级SQL优化
对于大量数据批量插入提升性能
- insert into 表名(M,N,…..) values(m1,n1….),(m2,n2….),(m3,n3….); #一条insert中插入多个数据
- mysql自动提交事务,一条一条插入要开启事务,关闭事务 n次,相比一条一条插入,性能高
批量删除优化,不用频繁开启和关闭事务
- 一次性删除太多数据,可能造成锁表,会有lock wait timeout exceed的错误
- 以下分批删除数据
for(){delete student where id<500;}delete student where id>=500 and id<1000;#采用分批删除数据
伪删除设计
- 给表增加一个是否删除标识字段isdel,类型是tinyint,0未删除,1已删除
- 删除数据,不是真正执行delete语句,执行update
- update student set isdel=1 where id=100;
- 而是用让用户不看见被删除的“记录”
- select * from student where …. and isdel=0
- 优点:
a. 修改标识的速度远高于删除语句
b. 这些历史数据,可以用来数据分析,数据挖掘,用户画像,大数据杀熟
提高group by语句的效率
- 如果一个过滤条件,即可以放在where,也可以放在having来实现,优先放在where中,因为每一步操作都会在内存中形成一个临时表,而形成的临时表越小越好
复合索引最左特性
左边依次拼接 (i,j,k)创建(i)/(i,j)/(i,j,k)
EXPLAIN SELECT * FROM student WHERE salary=3000
EXPLAIN SELECT * FROM student WHERE NAME=’陈’ AND salary=3000
EXPLAIN #不满足最左特性,但是满足优化器(交换律),使用了索引 SELECT * FROM student WHERE salary=3000 AND NAME=’陈’
- 排序字段创建索引- 在使用了排序的语句中,order by后面字段应该是索引字段,且select语句也应该是索引字段,才使用了索引。```sqlEXPLAIN #没有索引,sex不是索引字段SELECT id,NAME FROM student ORDER BY sexEXPLAIN #有,满足最左特性SELECT id,NAME FROM student ORDER BY NAMEEXPLAIN #没有,sex是没有索引SELECT id,NAME FROM student ORDER BY NAME,sexEXPLAIN #有,满足最左特性SELECT id,NAME FROM student ORDER BY NAME,salary排序时,不能select *,*包括非索引索引字段,造成索引失效规则:为了提高排序性能,频繁出现在排序order by后面的字段应该创建索引
删除冗余和重复的索引
- 利用最左特性,它会自动创建多个索引,别让它重复
- 如索引(a,b,c)有(a),(a,b),(a,b,c),索引(a,b)有(a),(a,b),(a)和(a,b)重复了,删除一个索引(a,b)
- 每个索引都需要单独占用空间,单独维护(索引会重构,数据新增、修改、删除变慢)
- 利用最左特性,它会自动创建多个索引,别让它重复
不要有超过3个以上的表连接
- 浪费空间,浪费时间,前面有理由
inner join 、left join、right join,优先使用inner join
- left join和right join的字段要多些,浪费空间,时间
- 三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小
in子查询的优化
先查出in 后面具体函数
SELECT id FROM student WHERE id<5
后用in
SELECT * FROM student WHERE id IN (1,2,3,4)
- 尽量使用union all替代union- union all不会去除重复的数据,没有比较操作,节省时间- union要去重,耗时<a name="lAOKJ"></a>## JDBC<a name="4WW0I"></a>### 简介- Java应用程序连接数据库的一套API<a name="i7hfF"></a>### 具体操作1. 创建TestJdbc工程2. 创建lib目录,复制jar包到lib目录下3. 项目导入jar包,file -> Project Structure ->Modules->找到你的模块->Dependencies(依赖)->右边+号 ->Jars or directories ->找到你的lib里的jar包,OK ->选中导入的jar包,OK<a name="99zce"></a>#### Statement```javapublic static void testStatement()throws Exception{//Mysql的驱动String driver = "com.mysql.jdbc.Driver";String url = "jdbc:mysql://localhost:3306/mysql-db";String username = "root";String password = "tarena";//1、注册驱动Class.forName(driver);//2、获取数据库连接Connection con = DriverManager.getConnection(url, username, password);//3、创建处理sql语句的对象Statement stat = con.createStatement();String str = "select * from student";//将查询的结果存放到结果集ResultSet中ResultSet rs = stat.executeQuery(str);//获得元数据表的列数int cols = rs.getMetaData().getColumnCount();System.out.println(cols);//获得元数据表的列名for (int i = 1; i <=cols ; i++) {System.out.print(rs.getMetaData().getColumnName(i)+"\t");}System.out.println();while (rs.next()){for (int i = 1; i <=cols ; i++) {System.out.print(rs.getString(i)+"\t");}System.out.println();}//关闭资源rs.close();stat.close();con.close();}
PreparedStatement(预编译)
- 增删改executeUpdate()
查询executeQuery() ```java public static void testPreparedStatement() throws Exception { String driver = “com.mysql.jdbc.Driver”; String username = “root”; String password = “tarena”; String url = “jdbc:mysql://localhost:3306/mysql-db”; //1、注册驱动 Class.forName(driver); //2、获得连接 Connection con = DriverManager.getConnection(url, username, password);
String str = “select * from student where id = ? and sex = ?”; //3、获得处理sql语句对象,PreparedStatement需要传入参数 PreparedStatement ps = con.prepareStatement(str); //对第一个和第二个 ? 赋值 ps.setString(1,”2”); ps.setString(2,”女”); //执行查询操作 其它增删改操作都是executeUpdate() ResultSet rs = ps.executeQuery(); //获得列数 int cols = rs.getMetaData().getColumnCount(); for(int i=1; i<=cols; i++){
//打印列的名称System.out.print( rs.getMetaData().getColumnName(i)+"\t");
} //打印具体值,rs.next表示行标下移 while(rs.next()){ //每次向下取一条,直到结尾
System.out.println(); //换行for(int i=1; i<=cols; i++){System.out.print( rs.getString(i)+"\t");}
} //关闭资源 rs.close(); ps.close(); con.close();
} ```
比较Statement和PreparedStatement
- Statement执行的sql语句,可能会因为人为的输入特别字符如 “ ‘ 等,当用”+ “拼接出现sql语法错误,这种现象叫sql注入。
- PreparedStatement在sql语句中用 ? 代替了sql中的变化值,能有效的防治sql注入

若有收获,就点个赞吧
0 人点赞
