网站系统的伸缩性架构最重要的技术手段就是使用服务器集群功能,通过不断地向集群中添加服务器来增强整个集群的处理能力。“伸”即网站的规模和服务器的规模总是在不断扩大。
1、不同功能进行物理分离(不同应用,数据,服务,基础服务)2、单一功能,通过集群规模实现(应用服务器集群和数据服务器集群(缓存数据服务器集群,存储数据服务器集群)
服务器集群的伸缩性设计:
负载均衡:Http重定向、DNS域名解析、反向代理、IP负载均衡、数据链路层;
负载均衡算法:轮询(依次分发到每台服务器)、加权轮询、随机、最少链接、源地址散列;
分布式缓存集群伸缩性: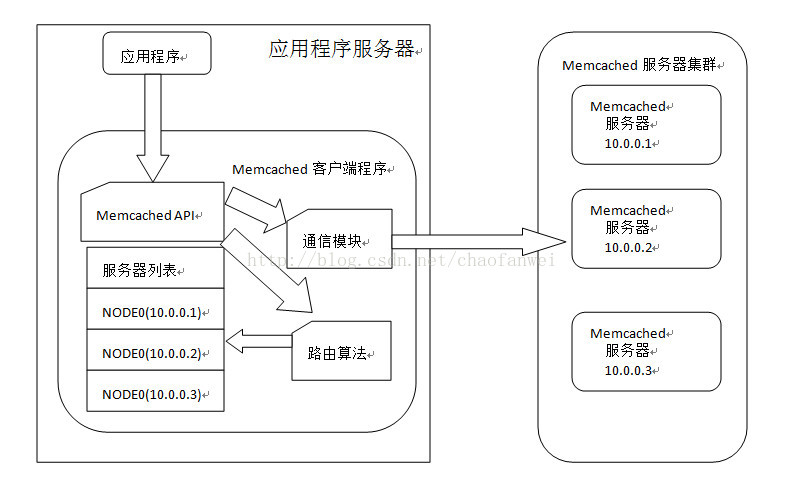
Hash表的读写性能很大程度上取决于HashCode的随机性,即HashCode越随机散列,Hash表冲突越少。目前比较好的字符串Hash散列有Time33算法,即对字符串逐字符迭代取hash值乘以33 求得hash值,算法原型为:hash(i) = hash(i–1) * 33 +str[i]。
Time33虽然可以较好的解决冲突,但是有可能相似的字符串的HashCode也比较接近,比如”AA” hash值是2210,”AB”的hash值是2211。这在某些场景下(分布式缓存,一致性hash分布式服务)是不能接受的。这种情况下,一个可行的方案是对对字符串取信息指纹(MD5),再对信息指纹求HashCode,由于字符串微小的变化就可以引起信息指纹的巨大不同,因此可以获得比较好的随机散列。如下:
原始字符串 –MD5–☞ 信息指纹 –hash计算–☞ HashCode值
另外在Java8源码中,对String的hash和equal重写,用的就是Time33的算法。
https://www.2cto.com/kf/201801/713436.html
【分布式缓存一致性Hash算法】
有一个不成熟的缓存扩容想法
提前预设1024个缓存服务器虚拟节点(理论值150个 from ALI-李智慧)(闭合环形-顺时针序列结构-【一致性Hash环】),然后,最开始数据量很小,只需要两台服务器。那么就是0 -511 两个节点有服务器存在。
前提:预设1024个缓存服务器虚拟节点(N个虚拟节点对应一个物理节点),并有服务器管理页面维护,可以添加一个节点,然后维护同步其中数据,选择上线或者下线的操作;
处理思路:
1、生成的数据Key值%1024取模取余后得到的一个节点值,但是这个值不一定是存在实际物理缓存服务器机器的。然后,将这条数据存储到顺时针的下一个具有实际物理缓存服务器的节点,此时,需要额外记录这个数据的节点为XXXX_NODE??:{数据ID}。
2、在缓存服务器不足以支撑现有的业务时,进行二次扩容。在任一两个相邻节点的中间加入一个新的服务器节点;
3、加入节点后,默认不进行发布上线,先执行数据的同步(从下一个服务器节点取出所有 上一节点 NODE_PRE 到 自身节点NODE_CUR 的所有缓存数据);
4、同步完成后,确认上线(最大可能避免缓存命中无效问题);
5、新增节点上线后,需要执行二次数据同步,然后将已同步完成的数据,从原节点移除。同步-上线期间产生的数据,同步到新增的节点(使缓存命中达到100%)。
以上的方式是数据有限的情况。若是正常一致性Hash是2^32次方的节点,新加节点后,失去缓存的数据直接访问数据库,也不会造成很大的压力。

若有收获,就点个赞吧
0 人点赞
